
Le scraping de données Web à l'ère du Big Data : opportunités et dilemmes éthiques
Publié: 2024-05-29Scraping de données Web et analyse du Big Data
Le scraping de données Web est devenu un mécanisme essentiel pour la collecte de données en ligne. Ce processus implique la récupération automatisée d’informations à partir de sites Web, transformant le Web non structuré en une multitude de données structurées prêtes à être analysées.
Source de l'image : https://www.sas.com/
Parallèlement, l’analyse du Big Data s’est taillée une place dans l’identification de modèles, de tendances et d’informations issues des ensembles de données massifs accumulés, souvent via le scraping de données Web. À mesure que de vastes volumes de données (environ 2,5 quintillions d’octets de données générés chaque jour) deviennent plus accessibles, la synthèse du scraping de données Web avec l’analyse du Big Data ouvre une myriade de possibilités pour les entreprises, les chercheurs et les décideurs politiques.
En combinant habilement ces capacités technologiques, ils se positionnent pour capitaliser sur une prise de décision guidée par les données, stimuler l'innovation en matière de services et façonner des entreprises stratégiques adaptées à leurs objectifs. Néanmoins, il est essentiel de reconnaître l'apparition de dilemmes éthiques résultant de la relation synergique entre ces outils avancés.
Il convient de tracer une ligne fine en ce qui concerne l'équilibre crucial entre la maximisation de la valeur des données et la préservation du droit à la vie privée des individus, en veillant à ce qu'aucun aspect n'éclipse l'autre.
Avantages du Web Data Scraping pour les projets Big Data
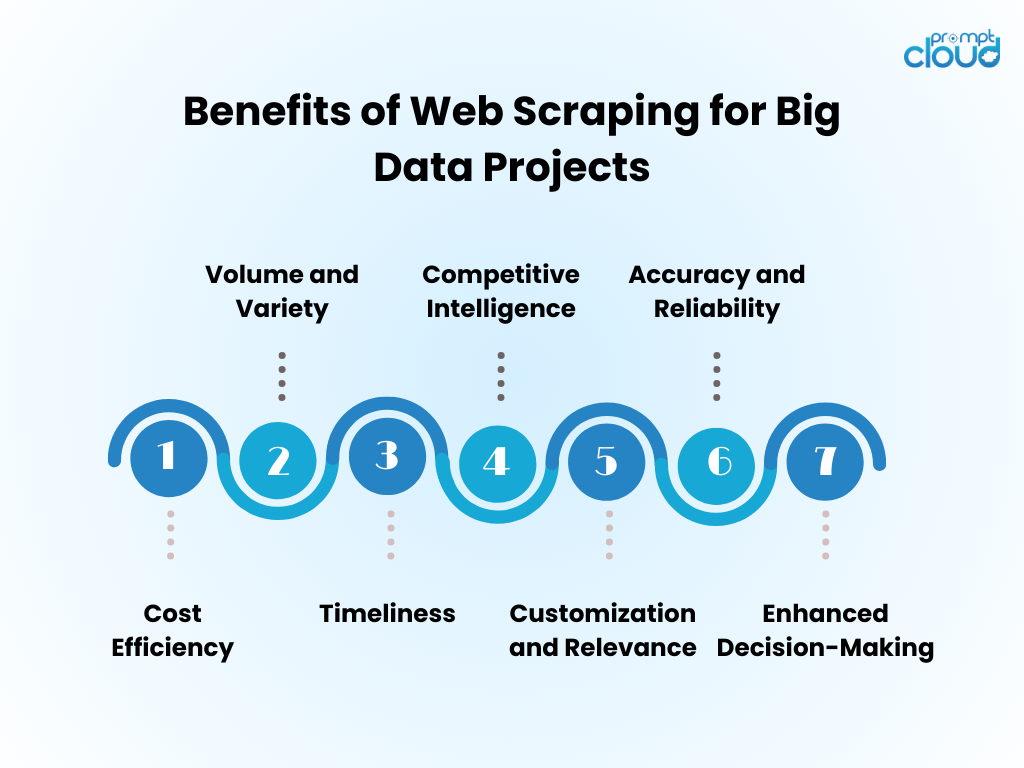
- Rentabilité : l'automatisation de la collecte de données via le web scraping réduit considérablement les coûts de main-d'œuvre humaine et accélère le délai d'obtention d'informations.
- Volume et variété : il permet la capture de grandes quantités de données provenant de sources diverses, essentielles pour alimenter l'analyse du Big Data.
- Rapidité : le web scraping fournit des données en temps réel ou quasi-réel, permettant des réponses plus agiles aux tendances du marché.
- Veille concurrentielle : elle donne aux organisations la possibilité de surveiller de près les concurrents et les changements du secteur.
- Personnalisation et pertinence : les données peuvent être adaptées à des besoins spécifiques, garantissant ainsi que l'analyse est pertinente et ciblée.
- Précision et fiabilité : le scraping automatisé minimise les erreurs humaines, conduisant à des ensembles de données plus précis.
- Prise de décision améliorée : l'accès à des données opportunes et pertinentes soutient une prise de décision éclairée et une planification stratégique.
Techniques de Web Scraping : de base à avancée

Source de l'image : travaux de connexion
Le scraping de données Web a évolué avec la technologie, en commençant par les techniques de base qui évoluent à mesure que la complexité des données augmente.
- Techniques de base : Initialement, les scrapers récupèrent des données à l'aide de simples requêtes HTTP pour obtenir des pages HTML, en analysant le contenu via des bibliothèques comme Beautiful Soup en Python. Ces outils peuvent gérer de manière adéquate des sites Web simples.
- Techniques intermédiaires : pour le contenu dynamique, les techniques évoluent pour inclure des outils d'automatisation comme Selenium, qui peuvent interagir avec JavaScript et imiter le comportement du navigateur.
- Techniques avancées : vers un scraping avancé, les méthodes intègrent des navigateurs sans tête et des serveurs proxy pour contourner les mesures anti-scraping. L'extraction de données devient sophistiquée grâce aux algorithmes d'apprentissage automatique, traitant le langage naturel et les images pour récupérer des informations.
- Considérations éthiques : Quelle que soit la complexité de la technique, des dilemmes éthiques persistent, nécessitant un équilibre entre l'accès aux données et le respect de la vie privée et de la propriété.
Intégration de données récupérées sur le Web dans l'analyse du Big Data
Les données récupérées sur le Web, lorsqu'elles sont intégrées à l'analyse du Big Data, peuvent révéler des informations complètes sur le marché et les tendances de consommation. Les analystes fusionnent les informations récupérées sur le Web avec les ensembles de données existants, améliorant ainsi la profondeur et l'étendue des résultats analytiques. Cette fusion engendre des modèles prédictifs améliorés, des stratégies marketing adaptées et des profils de consommateurs affinés.

- Nettoyage des données : les données récupérées nécessitent un nettoyage méticuleux pour garantir l'exactitude des analyses.
- Intégration des données : la combinaison de données récupérées avec d'autres sources nécessite des techniques avancées d'intégration de données.
- Amélioration de l'analyse : grâce à des données supplémentaires, les algorithmes d'apprentissage automatique peuvent révéler des modèles plus nuancés.
- Considération éthique : les analystes doivent garantir que l'utilisation des données Web est conforme aux normes juridiques et éthiques.
Le pool de données augmenté stimule l’innovation, mais exige une méthodologie rigoureuse et une surveillance éthique.
Meilleures pratiques pour un scraping Web efficace
- Respecter les protocoles robots.txt ; ne supprimez pas les sites qui l'interdisent via leur fichier robots.
- Planifiez les activités de scraping pendant les heures creuses pour minimiser l'impact sur les performances du serveur cible.
- Utilisez la mise en cache pour éviter de regratter le même contenu, en respectant les données du site Web et en économisant la bande passante.
- Implémentez une gestion des erreurs appropriée pour éviter que votre scraper ne plante et pour éviter d'envoyer trop de requêtes en cas d'erreurs.
- Faites pivoter les agents utilisateurs et les adresses IP pour éviter d'être bloqués, simulant ainsi un comportement de navigation plus naturel.
- Restez informé des pratiques légales et éthiques de web scraping, en vous assurant que vos activités de scraping ne violent pas les droits d'auteur ou les lois sur la confidentialité.
- Optimisez le code pour qu'il soit efficace et réduisez la charge sur le système de scraping et sur les sites Web cibles.
- Mettez régulièrement à jour le code de scraping pour vous adapter à tout changement dans la présentation ou la technologie du site Web, en maintenant l'efficacité et l'exactitude de votre récupération de données.
- Stockez les données collectées en toute sécurité et gérez-les conformément à toutes les réglementations pertinentes en matière de protection des données.
L'avenir du Web Scraping à l'ère du Big Data
À mesure que le Big Data continue de se développer, le scraping de données Web est sur le point de devenir encore plus intégré à l'analyse des données et à la business intelligence. L’avenir verra probablement :
- Modèles d'apprentissage automatique améliorés formés avec de vastes ensembles de données obtenus grâce au scraping, améliorant ainsi la précision et les informations.
- Demande accrue de récupération de données en temps réel, permettant aux entreprises de prendre des décisions plus rapides et basées sur les données.
- Développement d'outils de scraping plus sophistiqués pour naviguer dans les technologies anti-scraping et maintenir des pratiques de collecte de données éthiques.
- Des réglementations et des lois sur la confidentialité plus strictes façonnent les méthodologies de collecte de données Web, garantissant que les données sont collectées de manière responsable et avec le consentement.
- L’émergence de plateformes de scraping-as-a-service, offrant une extraction de données sur mesure pour les entreprises de toutes tailles.
Grâce à ces avancées, le web scraping continuera d’être un outil essentiel dans la boîte à outils Big Data.
Si le scraping manuel du Web semble intimidant ou si une assistance est nécessaire pour résoudre des défis complexes liés à l'obtention de données précieuses, soyez assuré que PromptCloud est prêt à vous aider !
Nous sommes spécialisés dans la fourniture de solutions complètes de web scraping conçues explicitement pour les initiatives Big Data, garantissant une extraction de données fiable et à grande échelle.
Faites-nous confiance pour aborder les aspects exigeants, vous permettant ainsi de vous concentrer sur la génération de choix éclairés en utilisant des ensembles de données robustes et significatifs. Contactez-nous à sales@promptcloud.com pour découvrir comment notre expertise peut booster votre plan de match Big Data !