
Qu'est-ce que Robots.txt dans le référencement : comment le créer et l'optimiser
Publié: 2022-04-22Le sujet d'aujourd'hui n'est pas directement lié à la monétisation du trafic. Mais robots.txt peut avoir un impact sur le référencement de votre site Web et, éventuellement, sur la quantité de trafic qu'il reçoit. De nombreux administrateurs Web ont ruiné le classement de leurs sites Web en raison d'entrées robots.txt bâclées. Ce guide vous aidera à éviter tous ces pièges. Assurez-vous de lire jusqu'à la fin!
- Qu'est-ce qu'un fichier robots.txt ?
- À quoi ressemble un fichier robots.txt ?
- Comment trouver votre fichier robots.txt
- Comment fonctionne un fichier Robots.txt ?
- Syntaxe robots.txt
- Directives prises en charge
- Agent utilisateur*
- Permettre
- Refuser
- Plan du site
- Directives non prises en charge
- Délai d'exploration
- Pas d'index
- Pas de suivi
- Avez-vous besoin d'un fichier robots.txt ?
- Création d'un fichier robots.txt
- Fichier robots.txt : bonnes pratiques SEO
- Utiliser une nouvelle ligne pour chaque directive
- Utilisez des caractères génériques pour simplifier les instructions
- Utilisez le signe dollar "$" pour spécifier la fin d'une URL
- Utilisez chaque agent utilisateur une seule fois
- Utiliser des instructions spécifiques pour éviter les erreurs involontaires
- Entrez des commentaires dans le fichier robots.txt avec un hachage
- Utiliser des fichiers robots.txt différents pour chaque sous-domaine
- Ne bloquez pas le bon contenu
- N'abusez pas du délai de crawl
- Attention à la casse
- Autres bonnes pratiques :
- Utilisation de robots.txt pour empêcher l'indexation du contenu
- Utilisation de robots.txt pour protéger le contenu privé
- Utilisation de robots.txt pour masquer le contenu en double malveillant
- Accès complet pour tous les bots
- Pas d'accès pour tous les bots
- Bloquer un sous-répertoire pour tous les bots
- Bloquer un sous-répertoire pour tous les bots (avec un fichier dans les limites autorisées)
- Bloquer un fichier pour tous les bots
- Bloquer un type de fichier (PDF) pour tous les bots
- Bloquer toutes les URL paramétrées pour Googlebot uniquement
- Comment tester votre fichier robots.txt pour les erreurs
- URL soumise bloquée par robots.txt
- Bloqué par robots.txt
- Indexé, bien que bloqué par robots.txt
- Robots.txt vs méta-robots vs x-robots
- Lectures complémentaires
- Emballer
Qu'est-ce qu'un fichier robots.txt ?
Le robots.txt, ou protocole d'exclusion de robots, est un ensemble de normes Web qui contrôlent la façon dont les robots des moteurs de recherche explorent chaque page Web, jusqu'aux balises de schéma sur cette page. Il s'agit d'un fichier texte standard qui peut même empêcher les robots d'exploration d'accéder à l'ensemble de votre site Web ou à des parties de celui-ci.
Tout en ajustant le référencement et en résolvant les problèmes techniques, vous pouvez commencer à tirer un revenu passif des publicités. Une seule ligne de code sur votre site Web renvoie des paiements réguliers !
Au sommaire ↑À quoi ressemble un fichier robots.txt ?
La syntaxe est simple : vous donnez des règles aux bots en spécifiant leur user-agent et leurs directives. Le fichier a le format de base suivant :
Plan du site : [emplacement de l'URL du plan du site]
Agent utilisateur : [identifiant du bot]
[directive 1]
[directive 2]
[directive …]
User-agent : [un autre identifiant de bot]
[directive 1]
[directive 2]
[directive …]
Comment trouver votre fichier robots.txt
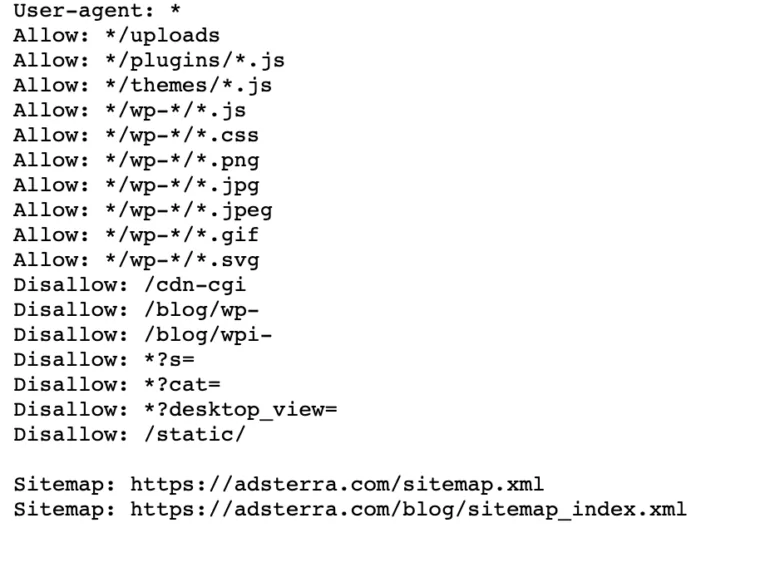
Si votre site Web possède déjà un fichier robot.txt, vous pouvez le trouver en accédant à cette URL : https://votrenomdedomaine.com/robots.txt dans votre navigateur. Par exemple, voici notre fichier
Comment fonctionne un fichier Robots.txt ?
Un fichier robots.txt est un fichier texte brut qui ne contient aucun code de balisage HTML (d'où l'extension .txt). Ce fichier, comme tous les autres fichiers du site Web, est stocké sur le serveur Web. Il est peu probable que les utilisateurs visitent cette page car elle n'est liée à aucune de vos pages, mais la plupart des robots d'exploration du Web la recherchent avant d'explorer l'intégralité du site Web.
Un fichier robots.txt peut donner des instructions aux bots mais ne peut pas appliquer ces instructions. Un bon robot, tel qu'un robot d'exploration Web ou un robot de flux d'actualités, vérifiera le fichier et suivra les instructions avant de visiter une page de domaine. Mais les robots malveillants ignoreront ou traiteront le fichier pour trouver des pages Web interdites.
Dans une situation où un fichier robots.txt contient des commandes en conflit, le bot utilisera l'ensemble d'instructions le plus spécifique.
Au sommaire ↑Syntaxe robots.txt
Un fichier robots.txt se compose de plusieurs sections de "directives", chacune commençant par un agent utilisateur. Le user-agent spécifie le crawl bot avec lequel le code communique. Vous pouvez soit vous adresser à tous les moteurs de recherche en même temps, soit gérer des moteurs de recherche individuels.
Chaque fois qu'un bot parcourt un site Web, il agit sur les parties du site qui l'appellent.
Agent utilisateur: *
Interdire : /
Agent utilisateur : Googlebot
Refuser:
Agent utilisateur : Bingbot
Interdire : /pas-pour-bing/
Directives prises en charge
Les directives sont des directives que vous voulez que les agents utilisateurs que vous déclarez suivent. Google prend actuellement en charge les directives suivantes.
Agent utilisateur*
Lorsqu'un programme se connecte à un serveur Web (un robot ou un navigateur Web classique), il envoie un en-tête HTTP appelé "user-agent" contenant des informations de base sur son identité. Chaque moteur de recherche a un agent utilisateur. Les robots de Google sont connus sous le nom de Googlebot, ceux de Yahoo sous le nom de Slurp et ceux de Bing sous le nom de BingBot. L'agent utilisateur initie une séquence de directives, qui peuvent s'appliquer à des agents utilisateurs spécifiques ou à tous les agents utilisateurs.
Permettre
La directive allow indique aux moteurs de recherche d'explorer une page ou un sous-répertoire, même un répertoire restreint. Par exemple, si vous souhaitez que les moteurs de recherche ne puissent pas accéder à tous les articles de votre blog sauf un, votre fichier robots.txt pourrait ressembler à ceci :
Agent utilisateur: *
Interdire : /blog
Autoriser : /blog/allowed-post
Cependant, les moteurs de recherche peuvent accéder à /blog/allowed-post mais ils ne peuvent pas accéder à :
/blog/autre-article
/blog/encore-un-autre-article
/blog/download-me.pd
Refuser
La directive disallow (qui est ajoutée au fichier robots.txt d'un site Web) indique aux moteurs de recherche de ne pas explorer une page spécifique. Dans la plupart des cas, cela empêchera également une page d'apparaître dans les résultats de recherche.
Vous pouvez utiliser cette directive pour demander aux moteurs de recherche de ne pas explorer les fichiers et les pages d'un dossier spécifique que vous cachez au grand public. Par exemple, du contenu sur lequel vous travaillez encore mais que vous avez publié par erreur. Votre fichier robots.txt pourrait ressembler à ceci si vous souhaitez empêcher tous les moteurs de recherche d'accéder à votre blog :
Agent utilisateur: *
Interdire : /blog
Cela signifie que tous les sous-répertoires du répertoire /blog ne seront pas non plus explorés. Cela empêcherait également Google d'accéder aux URL contenant /blog.
Au sommaire ↑Plan du site
Les sitemaps sont une liste de pages que vous souhaitez que les moteurs de recherche explorent et indexent. Si vous utilisez la directive sitemap, les moteurs de recherche connaîtront l'emplacement de votre sitemap XML. La meilleure option est de les soumettre aux outils des webmasters des moteurs de recherche, car chacun peut fournir aux visiteurs des informations précieuses sur votre site Web.
Il est important de noter qu'il n'est pas nécessaire de répéter la directive sitemap pour chaque agent utilisateur et qu'elle ne s'applique pas à un seul agent de recherche. Ajoutez vos directives de sitemap au début ou à la fin de votre fichier robots.txt.
Un exemple de directive sitemap dans le fichier :
Plan du site : https://www.domain.com/sitemap.xml
Agent utilisateur : Googlebot
Interdire : /blog/
Autoriser : /blog/post-title/
Agent utilisateur : Bingbot
Interdire : /services/
Au sommaire ↑Directives non prises en charge
Les directives suivantes ne sont plus prises en charge par Google , dont certaines n'ont techniquement jamais été approuvées.
Délai d'exploration
Yahoo, Bing et Yandex réagissent rapidement à l'indexation des sites Web et réagissent à la directive sur le délai d'exploration, ce qui les maintient sous contrôle pendant un certain temps.
Appliquez cette ligne à votre bloc :
Agent utilisateur : Bingbot
Délai d'exploration : 10
Cela signifie que les moteurs de recherche peuvent attendre dix secondes avant d'explorer le site Web ou dix secondes avant de réaccéder au site Web après l'exploration, ce qui revient au même mais légèrement différent selon l'agent utilisateur utilisé.
Pas d'index
La balise meta noindex est un excellent moyen d'empêcher les moteurs de recherche d'indexer l'une de vos pages. La balise permet aux robots d'accéder aux pages Web, mais elle informe également les robots de ne pas les indexer.
- En-tête de réponse HTTP avec balise noindex. Vous pouvez implémenter cette balise de deux manières : un en-tête de réponse HTTP avec une balise X-Robots ou une balise <meta> placée dans la section <head>. Voici à quoi devrait ressembler votre balise <meta> :
<meta name=”robots” content=”noindex”>
- Code d'état HTTP 404 et 410. Les codes d'état 404 et 410 indiquent qu'une page n'est plus disponible. Après avoir exploré et traité les pages 404/410, ils les suppriment automatiquement de l'index de Google. Pour réduire le risque de pages d'erreur 404 et 410, explorez régulièrement votre site Web et utilisez des redirections 301 pour diriger le trafic vers une page existante si nécessaire.
Pas de suivi
Nofollow ordonne aux moteurs de recherche de ne pas suivre les liens sur les pages et les fichiers sous un chemin spécifique. Depuis le 1er mars 2020, Google ne considère plus les attributs nofollow comme des directives. Au lieu de cela, ce seront des indices, un peu comme des balises canoniques. Si vous souhaitez un attribut "nofollow" pour tous les liens d'une page, utilisez la balise meta du robot, l'en-tête x-robots ou l'attribut de lien rel= "nofollow" .
Auparavant, vous pouviez utiliser la directive suivante pour empêcher Google de suivre tous les liens de votre blog :
Agent utilisateur : Googlebot
Pas de suivi : /blog/
Avez-vous besoin d'un fichier robots.txt ?
De nombreux sites Web moins complexes n'en ont pas besoin. Bien que Google n'indexe généralement pas les pages Web bloquées par robots.txt, il n'existe aucun moyen de garantir que ces pages n'apparaissent pas dans les résultats de recherche. Avoir ce fichier vous donne plus de contrôle et de sécurité sur le contenu de votre site Web par rapport aux moteurs de recherche.
Les fichiers robots vous aident également à accomplir les tâches suivantes :
- Empêcher le contenu dupliqué d'être exploré.
- Maintenir la confidentialité des différentes sections du site Web.
- Restreindre l'exploration des résultats de recherche interne.
- Empêcher la surcharge du serveur.
- Prévenir le gaspillage lié au "budget d'exploration".
- Gardez les images, les vidéos et les fichiers de ressources hors des résultats de recherche Google.
Ces mesures affectent finalement vos tactiques de référencement. Par exemple, le contenu dupliqué confond les moteurs de recherche et les oblige à choisir laquelle des deux pages se classe en premier. Quelle que soit la personne qui a créé le contenu, Google peut ne pas sélectionner la page d'origine pour les meilleurs résultats de recherche.

Dans les cas où Google détecte un contenu en double destiné à tromper les utilisateurs ou à manipuler les classements, il ajustera l'indexation et le classement de votre site Web. Par conséquent, le classement de votre site peut souffrir ou être entièrement supprimé de l'index de Google, disparaissant des résultats de recherche.
Le maintien de la confidentialité des différentes sections du site Web améliore également la sécurité de votre site Web et le protège des pirates. À long terme, ces mesures rendront votre site Web plus sûr, plus fiable et plus rentable.
Êtes-vous un propriétaire de site Web qui souhaite tirer profit du trafic ? Avec Adsterra, vous obtiendrez un revenu passif de n'importe quel site Web !
Au sommaire ↑Création d'un fichier robots.txt
Vous aurez besoin d'un éditeur de texte tel que le Bloc-notes.
- Créez une nouvelle feuille, enregistrez la page vierge sous le nom "robots.txt" et commencez à saisir des directives dans le document .txt vierge.
- Connectez-vous à votre cPanel, accédez au répertoire racine du site, recherchez le dossier public_html .
- Faites glisser votre fichier dans ce dossier, puis vérifiez si l'autorisation du fichier est correctement définie.
Vous pouvez écrire, lire et modifier le fichier en tant que propriétaire, mais les tiers ne sont pas autorisés. Un code d'autorisation "0644" doit apparaître dans le fichier. Sinon, cliquez avec le bouton droit sur le fichier et choisissez "autorisation de fichier".
Fichier robots.txt : bonnes pratiques SEO
Utiliser une nouvelle ligne pour chaque directive
Vous devez déclarer chaque directive sur une ligne distincte. Sinon, les moteurs de recherche seront confus.
Agent utilisateur: *
Interdire : /répertoire/
Interdire : /un autre répertoire/
Utilisez des caractères génériques pour simplifier les instructions
Vous pouvez utiliser des caractères génériques (*) pour tous les agents utilisateurs et faire correspondre les modèles d'URL lors de la déclaration des directives. Le caractère générique fonctionne bien pour les URL qui ont un modèle uniforme. Par exemple, vous pouvez empêcher l'exploration de toutes les pages de filtre comportant un point d'interrogation (?) dans leur URL.
Agent utilisateur: *
Interdire : /* ?
Utilisez le signe dollar "$" pour spécifier la fin d'une URL
Les moteurs de recherche ne peuvent pas accéder aux URL qui se terminent par des extensions telles que .pdf. Cela signifie qu'ils ne pourront pas accéder à /file.pdf, mais ils pourront accéder à /file.pdf?id=68937586, qui ne se termine pas par ".pdf". Par exemple, si vous souhaitez empêcher les moteurs de recherche d'accéder à tous les fichiers PDF de votre site Web, votre fichier robots.txt pourrait ressembler à ceci :
Agent utilisateur: *
Interdire : /*.pdf$
Utilisez chaque agent utilisateur une seule fois
Dans Google, peu importe si vous utilisez plusieurs fois le même user-agent. Il compilera simplement toutes les règles des différentes déclarations en une seule directive et la suivra. Cependant, déclarer chaque user-agent une seule fois a du sens car c'est moins déroutant.
Garder vos directives ordonnées et simples réduit le risque d'erreurs critiques. Par exemple, si votre fichier robots.txt contient les agents utilisateurs et directives suivants.
Agent utilisateur : Googlebot
Interdire : /a/
Agent utilisateur : Googlebot
Interdire : /b/
Utiliser des instructions spécifiques pour éviter les erreurs involontaires
Lors de la définition de directives, le fait de ne pas fournir d'instructions spécifiques peut créer des erreurs pouvant nuire à votre référencement. Supposons que vous ayez un site multilingue et que vous travailliez sur une version allemande pour le sous-répertoire /de/.
Vous ne voulez pas que les moteurs de recherche puissent y accéder car il n'est pas encore prêt. Le fichier robots.txt suivant empêchera les moteurs de recherche d'indexer ce sous-dossier et son contenu :
Agent utilisateur: *
Interdire : /de
Cependant, cela empêchera les moteurs de recherche d'explorer les pages ou les fichiers commençant par /de. Dans ce cas, l'ajout d'une barre oblique finale est la solution simple.
Agent utilisateur: *
Interdire : /de/
Au sommaire ↑Entrez des commentaires dans le fichier robots.txt avec un hachage
Les commentaires aident les développeurs et peut-être même vous à comprendre votre fichier robots.txt. Commencez la ligne par un dièse (#) pour inclure un commentaire. Les robots ignorent les lignes commençant par un hachage.
# Cela indique au bot Bing de ne pas explorer notre site.
Agent utilisateur : Bingbot
Interdire : /
Utiliser des fichiers robots.txt différents pour chaque sous-domaine
Robots.txt affecte uniquement l'exploration sur son domaine hôte. Vous aurez besoin d'un autre fichier pour restreindre l'exploration sur un autre sous-domaine. Par exemple, si vous hébergez votre site Web principal sur example.com et votre blog sur blog.example.com, vous aurez besoin de deux fichiers robots.txt. Placez-en un dans le répertoire racine du domaine principal, tandis que l'autre fichier doit se trouver dans le répertoire racine du blog.
Ne bloquez pas le bon contenu
N'utilisez pas un fichier robots.txt ou une balise noindex pour bloquer tout contenu de qualité que vous souhaitez rendre public afin d'éviter des effets négatifs sur les résultats SEO. Vérifiez soigneusement les balises noindex et interdisez les règles sur vos pages.
N'abusez pas du délai de crawl
Nous avons expliqué le délai d'exploration, mais vous ne devez pas l'utiliser fréquemment car il empêche les bots d'explorer toutes les pages. Cela peut fonctionner pour certains sites Web, mais vous risquez de nuire à votre classement et à votre trafic si vous avez un grand site Web.
Attention à la casse
Le fichier robots.txt est sensible à la casse, vous devez donc vous assurer que vous créez un fichier robots au format correct. Le fichier robots doit être nommé "robots.txt" avec toutes les lettres minuscules. Sinon, ça ne marchera pas.
Autres bonnes pratiques :
- Assurez-vous de ne pas bloquer l'exploration du contenu ou des sections de votre site Web.
- N'utilisez pas robots.txt pour conserver des données sensibles (informations privées sur l'utilisateur) hors des résultats SERP. Utilisez une méthode différente, telle que le cryptage des données ou la directive méta noindex , pour restreindre l'accès si d'autres pages renvoient directement à la page privée.
- Certains moteurs de recherche ont plus d'un agent utilisateur. Google, par exemple, utilise Googlebot pour les recherches organiques et Googlebot-Image pour les images. Il n'est pas nécessaire de spécifier des directives pour les multiples robots d'indexation de chaque moteur de recherche, car la plupart des agents utilisateurs d'un même moteur de recherche suivent les mêmes règles.
- Un moteur de recherche met en cache le contenu du fichier robots.txt mais le met à jour quotidiennement. Si vous modifiez le fichier et souhaitez le mettre à jour plus rapidement, vous pouvez envoyer l'URL du fichier à Google.
Utilisation de robots.txt pour empêcher l'indexation du contenu
Désactiver une page est le moyen le plus efficace d'empêcher les bots de l'explorer directement. Cependant, cela ne fonctionnera pas dans les situations suivantes :
- Si une autre source a des liens vers la page, les robots continueront de l'explorer et de l'indexer.
- Les robots illégitimes continueront d'explorer et d'indexer le contenu.
Utilisation de robots.txt pour protéger le contenu privé
Certains contenus privés, tels que les PDF ou les pages de remerciement, peuvent toujours être indexables même si vous bloquez les bots. Placer toutes vos pages exclusives derrière une connexion est l'un des meilleurs moyens de renforcer la directive d'interdiction. Votre contenu restera disponible, mais vos visiteurs franchiront une étape supplémentaire pour y accéder.
Utilisation de robots.txt pour masquer le contenu en double malveillant
Le contenu dupliqué est soit identique, soit très similaire à un autre contenu dans la même langue. Google essaie d'indexer et d'afficher des pages avec un contenu unique. Par exemple, si votre site a des versions "normale" et "imprimante" de chaque article et qu'une balise noindex ne bloque aucune des deux, ils listeront l'une d'entre elles.
Exemples de fichiers robots.txt
Voici quelques exemples de fichiers robots.txt. Ce sont principalement des idées, mais si l'une d'entre elles répond à vos besoins, copiez-la et collez-la dans un document texte, enregistrez-la sous le nom de "robots.txt" et téléchargez-la dans le répertoire approprié.
Accès complet pour tous les bots
Il existe plusieurs façons de dire aux moteurs de recherche d'accéder à tous les fichiers, y compris avoir un fichier robots.txt vide ou aucun.
Agent utilisateur: *
Refuser:
Pas d'accès pour tous les bots
Le fichier robots.txt suivant indique à tous les moteurs de recherche d'éviter d'accéder à l'intégralité du site :
Agent utilisateur: *
Interdire : /
Bloquer un sous-répertoire pour tous les bots
Agent utilisateur: *
Interdire : /dossier/
Bloquer un sous-répertoire pour tous les bots (avec un fichier dans les limites autorisées)
Agent utilisateur: *
Interdire : /dossier/
Autoriser : /dossier/page.html
Bloquer un fichier pour tous les bots
Agent utilisateur: *
Interdire : /ceci-est-un-fichier.pdf
Bloquer un type de fichier (PDF) pour tous les bots
Agent utilisateur: *
Interdire : /*.pdf$
Bloquer toutes les URL paramétrées pour Googlebot uniquement
Agent utilisateur : Googlebot
Interdire : /* ?
Comment tester votre fichier robots.txt pour les erreurs
Les erreurs dans Robots.txt peuvent être graves, il est donc important de les surveiller. Consultez régulièrement le rapport "Couverture" dans la Search Console pour les problèmes liés à robot.txt. Certaines des erreurs que vous pourriez rencontrer, ce qu'elles signifient et comment les corriger sont répertoriées ci-dessous.
URL soumise bloquée par robots.txt
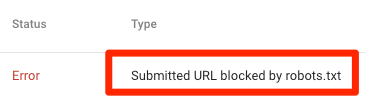
Cela indique que robots.txt a bloqué au moins une des URL de votre ou vos sitemaps. Si votre sitemap est correct et n'inclut pas de pages canonisées, non indexées ou redirigées, alors robots.txt ne devrait pas bloquer les pages que vous envoyez. Si tel est le cas, identifiez les pages concernées et supprimez le blocage de votre fichier robots.txt.
Vous pouvez utiliser le testeur robots.txt de Google pour identifier la directive de blocage. Soyez prudent lorsque vous modifiez votre fichier robots.txt, car une erreur peut affecter d'autres pages ou fichiers.
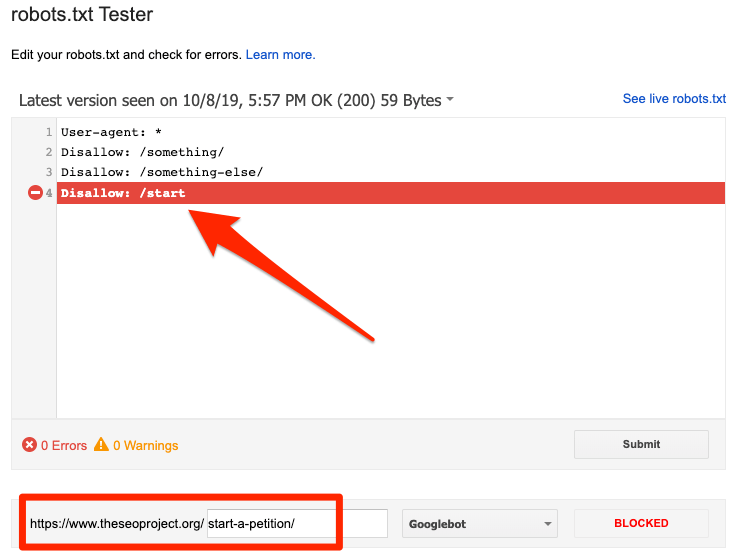
Bloqué par robots.txt
Cette erreur indique que robots.txt a bloqué du contenu que Google ne peut pas indexer. Supprimez le bloc d'exploration dans robots.txt si ce contenu est crucial et doit être indexé. (Vérifiez également que le contenu n'est pas indexé.)
Si vous souhaitez exclure du contenu de l'index de Google, utilisez la balise meta d'un robot ou l'en-tête x-robots et supprimez le bloc d'exploration. C'est le seul moyen de garder le contenu hors de l'index de Google.
Indexé, bien que bloqué par robots.txt
Cela signifie que Google indexe toujours une partie du contenu bloqué par robots.txt. Robots.txt n'est pas la solution pour empêcher votre contenu de s'afficher dans les résultats de recherche Google.
Pour empêcher l'indexation, supprimez le bloc d'analyse et remplacez-le par une balise meta robots ou un en-tête HTTP x-robots-tag. Si vous avez accidentellement bloqué ce contenu et souhaitez que Google l'indexe, supprimez le blocage d'exploration dans robots.txt. Cela peut aider à améliorer la visibilité du contenu dans les recherches Google.
Robots.txt vs méta-robots vs x-robots
Qu'est-ce qui différencie ces trois commandes de robot ? Robots.txt est un simple fichier texte, tandis que meta et x-robots sont des meta directives. Au-delà de leurs rôles fondamentaux, les trois ont des fonctions distinctes. Robots.txt spécifie le comportement d'exploration pour l'ensemble du site Web ou du répertoire, tandis que les méta et x-robots définissent le comportement d'indexation pour des pages individuelles (ou des éléments de page).
Lectures complémentaires
Ressources utiles
- Wikipédia : Protocole d'exclusion des robots
- Documentation de Google sur Robots.txt
- Documentation Bing (et Yahoo) sur Robots.txt
- Directives expliquées
- Documentation Yandex sur Robots.txt
Emballer
Nous espérons que vous avez pleinement compris l'importance du fichier robot.txt et ses contributions à votre pratique globale de référencement et à la rentabilité de votre site Web. Si vous avez encore du mal à tirer des revenus de votre site Web, vous n'aurez pas besoin de codage pour commencer à gagner de l'argent avec les publicités Adsterra. Mettez un code publicitaire sur votre site Web HTML, WordPress ou Blogger et commencez à générer des bénéfices dès aujourd'hui !