
Quelle technologie les moteurs de recherche utilisent-ils pour explorer les sites Web ?
Publié: 2023-03-02
Si vous vous êtes déjà demandé quelle technologie les moteurs de recherche utilisent pour explorer les sites Web, alors préparez-vous à obtenir enfin des réponses à vos questions. Vous découvrirez ce qu'est un robot d'exploration Web, les nombreux types de robots d'exploration Web utilisés par les principaux moteurs de recherche et en quoi consiste le processus d'indexation de la recherche. Vous apprendrez également comment tout cela affectera les résultats des moteurs de recherche et comment les propriétaires de sites Web peuvent dire aux robots d'indexation des moteurs de recherche d'indexer le contenu en fonction de leurs souhaits. Découvrons-en plus sur cette technologie que les moteurs de recherche utilisent pour fournir avec précision des milliards de résultats de recherche pertinents aux personnes qui recherchent des informations sur le World Wide Web.
Que sont les robots d'exploration Web ou les robots des moteurs de recherche ?
Les robots d'indexation Web, également connus sous le nom d'araignées, sont des programmes automatisés que des entreprises comme Google et Microsoft utilisent pour enseigner à leurs moteurs de recherche ce qui est présent sur chaque page Web accessible de chaque site Web qu'ils peuvent trouver sur Internet. Ce n'est qu'en apprenant quelles informations sont incluses sur une page Web que ces moteurs de recherche peuvent récupérer ces informations avec précision lorsqu'un de leurs utilisateurs tape une requête de recherche demandant des informations sur un sujet spécifique.
Les types de robots Web Crawler
Chaque moteur de recherche a ses robots d'indexation. Voici quelques-uns des plus utilisés.
GoogleBot
Google est le moteur de recherche le plus populaire de la planète et utilise deux versions de robots d'indexation pour indexer des centaines de milliards de pages Web. Le GoogleBot Desktop examinera les pages imitant le comportement d'une personne utilisant un ordinateur de bureau pour naviguer sur Internet, tandis que le GoogleBot Mobile fera de même pour les utilisateurs de smartphones.
Le GoogleBot est l'un des types de robots de recherche les plus efficaces jamais créés et peut rapidement explorer et indexer des pages Web. Il a cependant du mal à explorer des structures de sites Web très complexes. De plus, cela peut souvent prendre plusieurs jours ou plusieurs semaines à GoogleBot pour explorer une page Web qui vient d'être publiée, ce qui signifie qu'elle n'apparaîtra pas dans les résultats pertinents pendant un certain temps.
Bingbot
Le Bingbot est la réponse de Microsoft à Google sur son propre moteur de recherche Bing. Cela fonctionne de la même manière que le robot d'exploration Web de Google et inclut même un outil de récupération qui indique comment le bot explorera une page, vous permettant de voir s'il y a des problèmes ici.
Robot slurp
Le Slurp Bot est le robot d'exploration Web utilisé par Yahoo, bien qu'ils utilisent également Bingbot pour fournir les résultats de leurs moteurs de recherche. Le propriétaire du site Web doit autoriser l'accès au Slurp Bot s'il souhaite que le contenu de sa page Web apparaisse dans les résultats de recherche Yahoo Mobile. En outre, le Slurp Bot peut également accéder aux sites partenaires de Yahoo pour ajouter du contenu à leurs sites Web Yahoo News, Yahoo Sports et Yahoo Finance.
CanardCanardBot
Il s'agit du robot d'exploration Web utilisé par DuckDuckGo, un moteur de recherche connu pour fournir un niveau de confidentialité inégalé à ses utilisateurs en ne suivant pas leur activité comme le font de nombreux moteurs populaires. Ils fournissent des résultats de recherche obtenus à partir de leur DuckDuckBot, ainsi que des sites Web participatifs comme Wikipedia et d'autres moteurs de recherche.
Baiduspider et robot Yandex
Ce sont les robots d'exploration utilisés respectivement par les moteurs de recherche Baidu de Chine et Yandex de Russie. Baidu détient plus de 80 % du marché des moteurs de recherche en Chine continentale.
Fonctionnement de l'exploration Web, de l'indexation de la recherche et du classement des moteurs de recherche
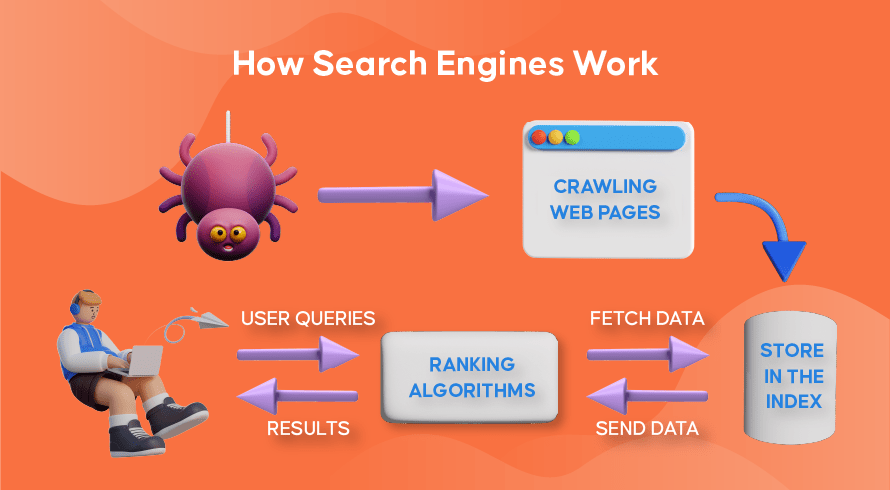
Voyons maintenant comment la plupart des moteurs de recherche utilisent les robots d'exploration Web pour rechercher, stocker, organiser et récupérer les informations contenues dans les sites Web.
Comment fonctionnent les robots d'exploration Web
Le processus de recherche de contenu nouveau et mis à jour sur les sites Web est appelé "exploration du Web", d'où le nom des logiciels qui remplissent cette fonction. Les robots commenceront par explorer quelques pages Web, trouveront leur contenu, puis suivront les hyperliens inclus sur cette page Web pour découvrir de nouvelles URL, menant à encore plus de contenu.
Comment fonctionne l'indexation des moteurs de recherche
Une fois que les robots ont découvert du contenu nouveau ou mis à jour grâce à l'exploration du Web, tout ce qu'ils trouvent est ajouté à une base de données massive appelée « index de moteur de recherche ». C'est comme une bibliothèque où les livres sont comme des pages Web, organisés pour une récupération facile plus tard. Contenant dans chaque livre la plupart du texte contenu sur une page Web que nous pouvons voir (à l'exclusion des mots comme 'a', 'an' et 'the') ainsi que les métadonnées que seuls les crawlers voient. Les métadonnées sont ce que les moteurs de recherche utilisent pour comprendre le contenu d'une page Web. Le méta titre et la méta description sont des exemples de métadonnées.
Comment fonctionne le classement de recherche
Chaque fois qu'un utilisateur tape une requête de recherche, le moteur de recherche respectif vérifie son index, trouve les informations les plus pertinentes qui correspondent à cette requête, organise la liste des liens Web contenant le contenu pertinent et le présente à l'utilisateur dans le moteur de recherche. pages de résultats (SERP).
Cette organisation des SERPs est appelée « classement de recherche » et est réalisée par un algorithme de recherche qui prend en compte les données collectées dont les métadonnées, la crédibilité du site (autorité), ainsi que les mots-clés et les liens. Les sites Web qui sont considérés comme des sources très crédibles et qui contiennent un contenu très pertinent qui sera utile aux utilisateurs seront très bien classés, recevant les meilleurs résultats sur les SERP. C'est pourquoi chaque propriétaire de site Web a des stratégies pour classer son site Web sur les SERP.
Comment l'optimisation des moteurs de recherche (SEO) entre dans l'image
Les propriétaires de sites Web peuvent optimiser le contenu de leurs pages de manière à ce que les moteurs de recherche les reconnaissent plus facilement comme étant pertinents et utiles pour leurs utilisateurs. Cela poussera ces pages vers le haut des SERP, apportant plus de trafic organique vers le site Web. L'inclusion stratégique de mots-clés pertinents dans la copie de la page, la création de liens et l'utilisation d'images et de vidéos originales sont quelques-unes des façons dont les techniques de référencement peuvent être utilisées.

En outre, les sites Web peuvent également utiliser divers outils tels que SEMrush pour rechercher et résoudre divers problèmes sur leurs pages, tels que des liens brisés, ce qui améliorera encore leur classement aux yeux des moteurs de recherche.
Dire aux moteurs de recherche comment crawler votre site Web

Parfois, vous constaterez que les robots d'indexation n'ont pas rempli leur fonction de manière adéquate, ce qui fait que des pages importantes de votre site Web manquent à l'index. Cela signifie que les requêtes de recherche pertinentes ne seront pas présentées avec votre contenu, ce qui rendra difficile pour les clients potentiels de trouver leur chemin vers vos pages. Heureusement, il existe des moyens de communiquer avec les moteurs de recherche, ce qui vous permet de contrôler un peu ce qui est indexé et ce qui est ignoré.
Le fichier robots.txt stocké dans le répertoire racine de votre site Web indique aux robots d'indexation quelles pages vous souhaitez explorer, lesquelles ignorer et comment l'architecture de votre site Web est organisée. Vous souhaiterez peut-être empêcher l'indexation de pages spécifiques si elles sont utilisées pour des tests, ou des promotions spéciales et des URL en double utilisées dans le commerce électronique.
GoogleBot, par exemple, continuera à explorer un site Web dans son intégralité s'il n'y a pas de fichier robots.txt présent. Lors de la détection de votre fichier robots.txt, GoogleBot suivra vos instructions lors de l'exploration. S'il a du mal à détecter le fichier ou rencontre une erreur, il se peut qu'il n'explore pas votre site Web. Vous devez utiliser le fichier robots.txt correctement, organiser l'architecture de votre site Web et utiliser les meilleures pratiques de référencement sur la page pour éviter tout problème d'exploration. Vous pouvez effectuer un audit de site Web pour analyser et identifier les problèmes qui affligent votre site Web.
Besoin de services de référencement pour votre site Web ?
Si vous recherchez un fournisseur de services qui comprend comment les robots d'exploration Web et l'indexation de recherche fonctionnent pour améliorer le classement de votre site Web, alors Inquivix est le partenaire SEO que vous recherchiez. Nous fournissons un ensemble complet de services de référencement sur la page, de la création de contenu à l'optimisation de l'architecture du site et à l'analyse des performances du site Web pour continuer à améliorer la qualité de l'expérience de votre site Web. Pour en savoir plus, visitez les services de référencement sur page d'Inquivix dès aujourd'hui !
FAQ
Les moteurs de recherche utilisent des programmes appelés « robots Web », également appelés « araignées » ou « bots », pour découvrir à la fois le contenu nouveau et mis à jour sur les pages d'un site Web. Il suivra ensuite les liens inclus dans la page pour trouver plus de pages. Le contenu trouvé sur une page est enregistré dans un index qui est utilisé pour récupérer des informations pour les résultats de recherche lorsqu'un utilisateur le demande.
GoogleBot Desktop et GoogleBot Mobile sont les robots d'exploration Web les plus populaires dans la plupart des pays, suivis de Bingbot, Slurp Bot et DuckDuckBot. Baiduspider est principalement utilisé en Chine tandis que Yandex Bot est utilisé en Russie.