
Praktik terbaik dan kasus penggunaan untuk mengambil data dari situs web
Diterbitkan: 2023-12-28Saat mengambil data dari situs web, penting untuk menghormati peraturan dan kerangka situs target. Mematuhi praktik terbaik bukan hanya masalah etika namun juga berfungsi untuk menghindari komplikasi hukum dan menjamin keandalan ekstraksi data. Berikut adalah pertimbangan utama:
- Patuhi robots.txt : Selalu periksa file ini terlebih dahulu untuk memahami apa yang telah ditetapkan oleh pemilik situs sebagai terlarang untuk pengikisan.
- Memanfaatkan API : Jika tersedia, gunakan API resmi situs, yang merupakan metode yang lebih stabil dan disetujui untuk mengakses data.
- Perhatikan tingkat permintaan : Pengikisan data yang berlebihan dapat membebani server situs web, jadi atur permintaan Anda dengan cara yang bijaksana.
- Identifikasi diri Anda : Melalui string agen pengguna Anda, bersikaplah transparan tentang identitas dan tujuan Anda saat melakukan scraping.
- Tangani data secara bertanggung jawab : Simpan dan gunakan data bekas sesuai undang-undang privasi dan peraturan perlindungan data.
Mengikuti praktik-praktik ini memastikan penghapusan etika, menjaga integritas dan ketersediaan konten online.
Memahami Kerangka Hukum
Saat mengambil data dari situs web, penting untuk menavigasi batasan hukum yang saling terkait. Teks legislatif utama meliputi:
- Undang-undang Penipuan dan Penyalahgunaan Komputer (CFAA): Perundang-undangan di Amerika Serikat menjadikannya ilegal untuk mengakses komputer tanpa otorisasi yang tepat.
- Peraturan Perlindungan Data Umum (GDPR) Uni Eropa : Mengamanatkan persetujuan untuk penggunaan data pribadi dan memberikan kontrol kepada individu atas data mereka.
- Digital Millennium Copyright Act (DMCA) : Melindungi terhadap distribusi konten berhak cipta tanpa izin.
Scraper juga harus menghormati perjanjian 'ketentuan penggunaan' situs web, yang seringkali membatasi ekstraksi data. Memastikan kepatuhan terhadap undang-undang dan kebijakan ini penting untuk menghapus data situs web secara etis dan legal.
Memilih Alat yang Tepat untuk Mengikis
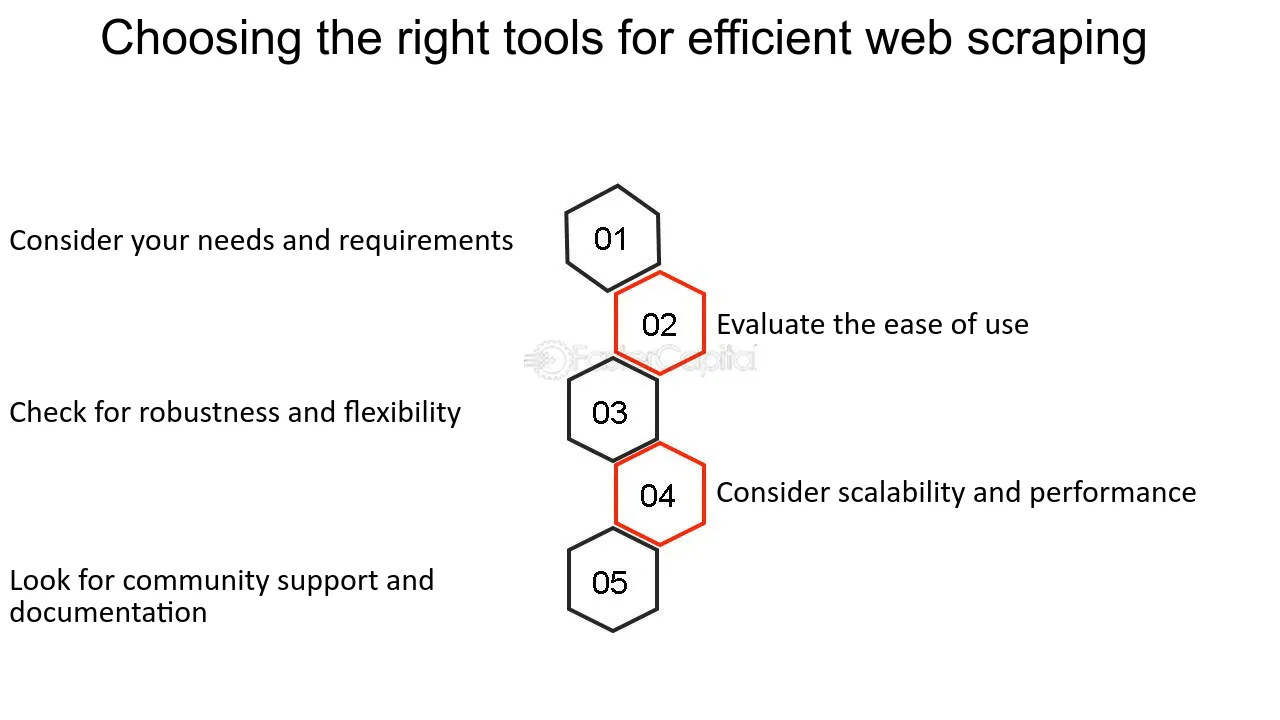
Memilih alat yang tepat sangat penting ketika memulai proyek web scraping. Faktor-faktor yang perlu dipertimbangkan meliputi:
- Kompleksitas Situs Web : Situs dinamis mungkin memerlukan alat seperti Selenium yang dapat berinteraksi dengan JavaScript.
- Kuantitas Data : Untuk pengikisan skala besar, disarankan menggunakan alat dengan kemampuan pengikisan terdistribusi seperti Scrapy.
- Legalitas dan Etika : Pilih alat dengan fitur yang sesuai dengan robots.txt dan tetapkan string agen pengguna.
- Kemudahan Penggunaan : Pemula mungkin lebih menyukai antarmuka ramah pengguna yang ditemukan di perangkat lunak seperti Octoparse.
- Pengetahuan Pemrograman : Non-coder mungkin memilih perangkat lunak dengan GUI, sementara programmer dapat memilih perpustakaan seperti BeautifulSoup.
Sumber Gambar: https://fastercapital.com/
Praktik Terbaik untuk Mengikis Data dari Situs Web secara Efektif
Untuk mengikis data dari situs web secara efisien dan bertanggung jawab, ikuti panduan berikut:
- Hormati file robots.txt dan persyaratan situs web untuk menghindari masalah hukum.
- Gunakan header dan putar agen pengguna untuk meniru perilaku manusia.
- Terapkan penundaan antar permintaan untuk mengurangi beban server.
- Memanfaatkan proxy untuk mencegah larangan IP.
- Kikis selama jam-jam di luar jam sibuk untuk meminimalkan gangguan situs web.
- Selalu simpan data secara efisien, hindari entri duplikat.
- Pastikan keakuratan data yang diambil dengan pemeriksaan rutin.
- Perhatikan undang-undang privasi data saat menyimpan dan menggunakan data.
- Selalu perbarui alat pengikis Anda untuk menangani perubahan situs web.
- Selalu bersiap untuk mengadaptasi strategi scraping jika situs web memperbarui strukturnya.
Kasus Penggunaan Pengikisan Data di Seluruh Industri
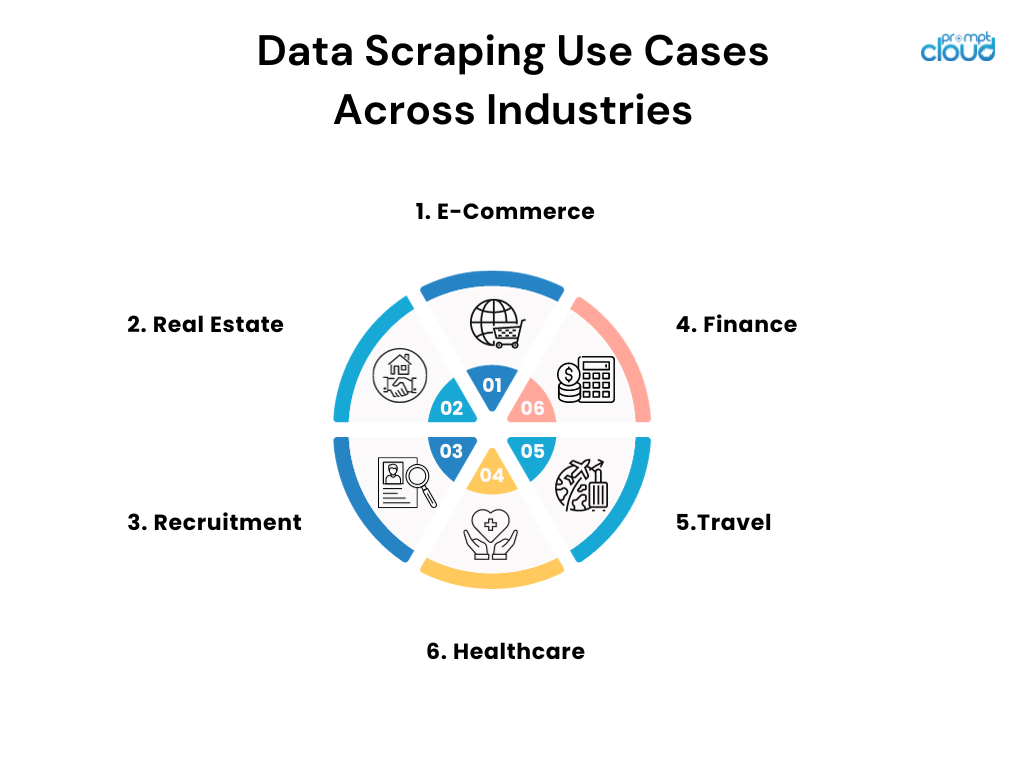
- E-Commerce: Pengecer online menerapkan scraping untuk memantau harga pesaing dan menyesuaikan strategi penetapan harga mereka.
- Real Estat: Agen dan perusahaan mengumpulkan daftar untuk mengumpulkan informasi properti, tren, dan data harga dari berbagai sumber.
- Rekrutmen: Perusahaan mencari lowongan kerja dan media sosial untuk menemukan kandidat potensial dan menganalisis tren pasar kerja.
- Keuangan: Analis mengumpulkan catatan publik dan dokumen keuangan untuk menginformasikan strategi investasi dan melacak sentimen pasar.
- Perjalanan: Agensi menaikkan harga maskapai dan hotel untuk memberikan penawaran dan paket terbaik kepada pelanggan.
- Layanan Kesehatan: Para peneliti mengumpulkan database dan jurnal medis untuk terus mendapatkan informasi terbaru tentang temuan terbaru dan uji klinis.
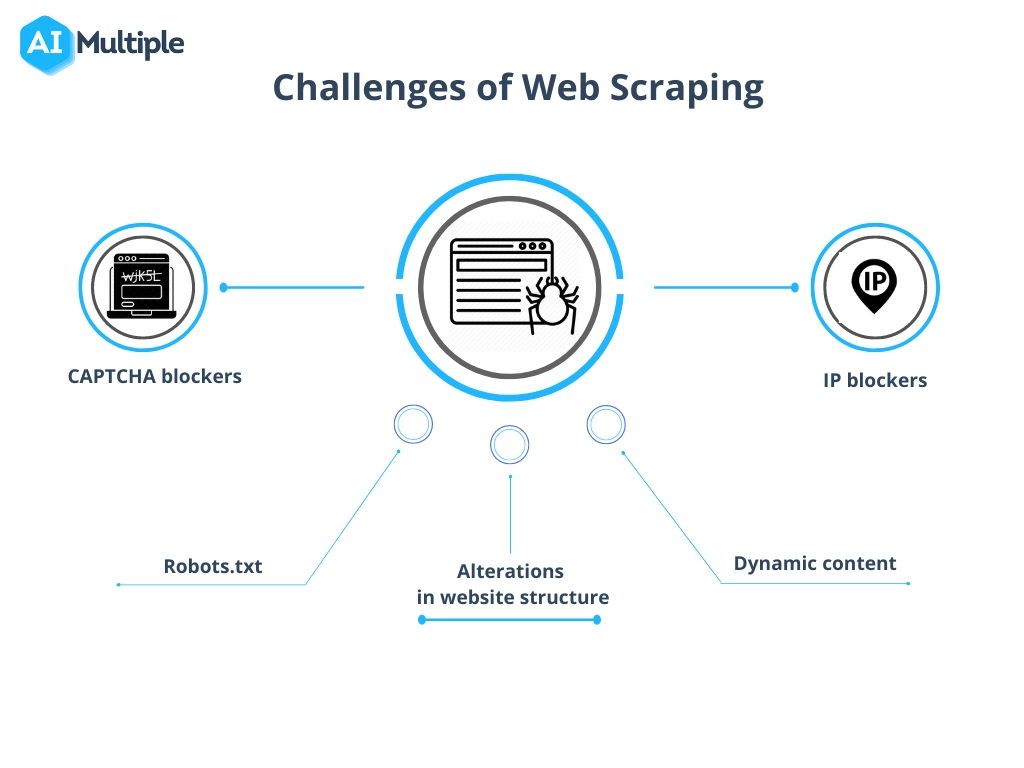
Mengatasi Tantangan Umum dalam Pengikisan Data
Proses pengambilan data dari situs web, meskipun sangat berharga, sering kali melibatkan mengatasi hambatan seperti perubahan struktur situs web, tindakan anti-pengikisan, dan kekhawatiran mengenai kualitas data.

Sumber Gambar: https://research.aimultiple.com/
Untuk menavigasi hal ini secara efektif:
- Tetap Adaptif : Perbarui skrip scraping secara teratur agar sesuai dengan pembaruan situs web. Penggunaan pembelajaran mesin dapat membantu beradaptasi terhadap perubahan struktural secara dinamis.
- Hormati Batasan Hukum : Memahami dan mematuhi legalitas pengikisan untuk menghindari litigasi. Pastikan untuk meninjau file robots.txt dan persyaratan layanan di situs web.
- Bentuk Atas
- Meniru Interaksi Manusia : Situs web mungkin memblokir scraper yang mengirimkan permintaan terlalu cepat. Terapkan penundaan dan interval acak antar permintaan agar tampak kurang robotik.
- Menangani CAPTCHA : Tersedia alat dan layanan yang dapat mengatasi atau mengabaikan CAPTCHA, meskipun penggunaannya harus dipertimbangkan tanpa adanya implikasi etika dan hukum.
- Jaga Integritas Data : Pastikan keakuratan data yang diekstraksi. Validasi data secara berkala dan bersihkan untuk menjaga kualitas dan kegunaan.
Strategi-strategi ini membantu mengatasi hambatan umum dan memfasilitasi ekstraksi data berharga.
Kesimpulan
Mengekstraksi data secara efisien dari situs web adalah metode berharga dengan beragam aplikasi, mulai dari riset pasar hingga analisis persaingan. Penting untuk mematuhi praktik terbaik, memastikan legalitas, menghormati pedoman robots.txt, dan secara hati-hati mengontrol frekuensi scraping untuk mencegah kelebihan server.
Menerapkan metode-metode ini secara bertanggung jawab akan membuka pintu bagi sumber data yang kaya yang dapat memberikan wawasan yang dapat ditindaklanjuti dan mendorong pengambilan keputusan yang tepat bagi bisnis dan individu. Penerapan yang tepat, ditambah dengan pertimbangan etis, memastikan bahwa pengikisan data tetap menjadi alat yang ampuh dalam lanskap digital.
Siap menambah wawasan Anda dengan mengambil data dari situs web? Tidak perlu mencari lagi! PromptCloud menawarkan layanan web scraping yang etis dan andal yang disesuaikan dengan kebutuhan Anda. Terhubung dengan kami di sales@promptcloud.com untuk mengubah data mentah menjadi intelijen yang dapat ditindaklanjuti. Mari tingkatkan pengambilan keputusan Anda bersama-sama!
Pertanyaan yang Sering Diajukan
Apakah mengikis data dari situs web dapat diterima?
Tentu saja, pengumpulan data tidak masalah, tetapi Anda harus bertindak sesuai aturan. Sebelum menyelami petualangan scraping apa pun, perhatikan baik-baik persyaratan layanan dan file robots.txt dari situs web yang dimaksud. Menunjukkan rasa hormat terhadap tata letak situs web, mematuhi batas frekuensi, dan menjaga etika adalah kunci dari praktik pengumpulan data yang bertanggung jawab.
Bagaimana cara mengekstrak data pengguna dari situs web melalui scraping?
Mengekstraksi data pengguna melalui scraping memerlukan pendekatan yang cermat dan selaras dengan norma hukum dan etika. Jika memungkinkan, disarankan untuk memanfaatkan API yang tersedia untuk umum yang disediakan oleh situs web untuk pengambilan data. Dengan tidak adanya API, sangat penting untuk memastikan bahwa metode scraping yang digunakan mematuhi undang-undang privasi, ketentuan penggunaan, dan kebijakan yang ditetapkan oleh situs web untuk mengurangi potensi konsekuensi hukum.
Apakah mengambil data situs web dianggap ilegal?
Legalitas web scraping bergantung pada beberapa faktor, termasuk tujuan, metodologi, dan kepatuhan terhadap undang-undang terkait. Meskipun web scraping sendiri pada dasarnya tidak ilegal, akses tanpa izin, pelanggaran persyaratan layanan situs web, atau pengabaian terhadap undang-undang privasi dapat mengakibatkan konsekuensi hukum. Perilaku yang bertanggung jawab dan beretika dalam aktivitas web scraping adalah hal yang terpenting, yang melibatkan kesadaran yang tinggi akan batasan hukum dan pertimbangan etis.
Bisakah situs web mendeteksi kejadian web scraping?
Situs web telah menerapkan mekanisme untuk mendeteksi dan mencegah aktivitas web scraping, memantau elemen seperti string agen pengguna, alamat IP, dan pola permintaan. Untuk memitigasi deteksi, praktik terbaik mencakup penggunaan teknik seperti merotasi agen pengguna, memanfaatkan proxy, dan menerapkan penundaan acak antar permintaan. Namun, penting untuk diingat bahwa upaya untuk menghindari tindakan deteksi dapat melanggar persyaratan layanan situs web dan berpotensi menimbulkan konsekuensi hukum. Praktik web scraping yang bertanggung jawab dan etis memprioritaskan transparansi dan kepatuhan terhadap standar hukum dan etika.