
Pengikisan Halaman Web Dinamis dengan Python – Panduan Cara
Diterbitkan: 2024-06-08Pengikisan web dinamis melibatkan pengambilan data dari situs web yang menghasilkan konten secara real-time melalui JavaScript atau Python. Tidak seperti halaman web statis, konten dinamis dimuat secara asinkron, sehingga membuat teknik pengikisan tradisional menjadi tidak efisien.
Penggunaan pengikisan web dinamis:
- Situs web berbasis AJAX
- Aplikasi Satu Halaman (SPA)
- Situs dengan elemen pemuatan tertunda
Alat dan teknologi utama:
- Selenium – Mengotomatiskan interaksi browser.
- BeautifulSoup – Mem-parsing konten HTML.
- Permintaan – Mengambil konten halaman web.
- lxml – Mem-parsing XML dan HTML.
Python pengikisan web dinamis memerlukan pemahaman lebih dalam tentang teknologi web untuk mengumpulkan data waktu nyata secara efektif.
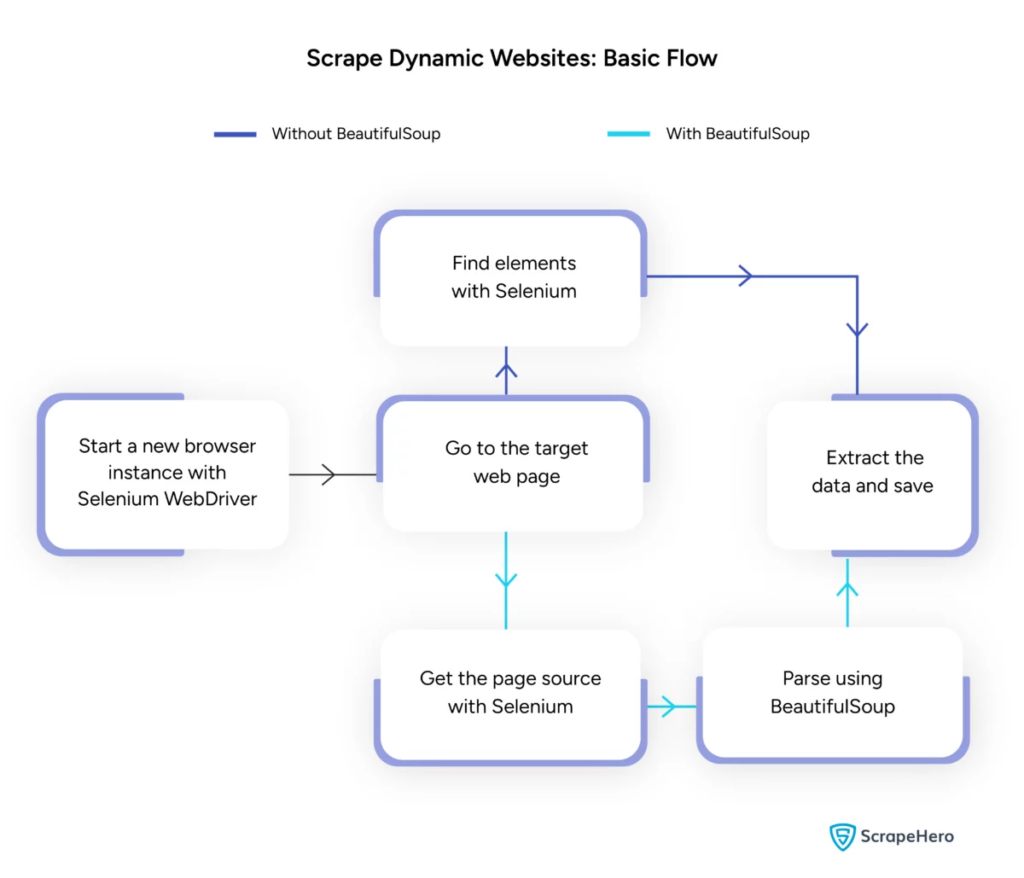
Sumber Gambar: https://www.scrapehero.com/scrape-a-dynamic-website/
Menyiapkan Lingkungan Python
Untuk memulai pengikisan web dinamis dengan Python, penting untuk mengatur lingkungan dengan benar. Ikuti langkah ini:
- Instal Python : Pastikan Python diinstal pada mesin. Versi terbaru dapat diunduh dari situs resmi Python.
- Buat Lingkungan Virtual :

Aktifkan lingkungan virtual:

- Instal Perpustakaan yang Diperlukan :

- Menyiapkan Editor Kode : Gunakan IDE seperti PyCharm, VSCode, atau Jupyter Notebook untuk menulis dan menjalankan skrip.
- Biasakan dengan HTML/CSS : Memahami struktur halaman web membantu dalam menavigasi dan mengekstrak data secara efektif.
Langkah-langkah ini membangun dasar yang kuat untuk proyek python web scraping dinamis.
Memahami Dasar-dasar Permintaan HTTP
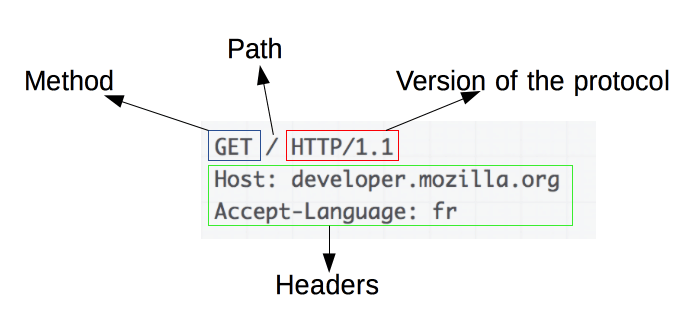
Sumber Gambar: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Permintaan HTTP adalah dasar dari web scraping. Ketika klien, seperti browser web atau web scraper, ingin mengambil informasi dari server, ia mengirimkan permintaan HTTP. Permintaan ini mengikuti struktur tertentu:
- Metode : Tindakan yang akan dilakukan, seperti GET atau POST.
- URL : Alamat sumber daya di server.
- Header : Metadata tentang permintaan, seperti tipe konten dan agen pengguna.
- Isi : Data opsional yang dikirim bersama permintaan, biasanya digunakan dengan POST.
Memahami cara menafsirkan dan menyusun komponen-komponen ini sangat penting untuk web scraping yang efektif. Pustaka Python seperti permintaan menyederhanakan proses ini, memungkinkan kontrol yang tepat atas permintaan.
Menginstal Perpustakaan Python
Sumber Gambar: https://ajaytech.co/what-are-python-libraries/
Untuk web scraping dinamis dengan Python, pastikan Python diinstal. Buka terminal atau command prompt dan instal perpustakaan yang diperlukan menggunakan pip:
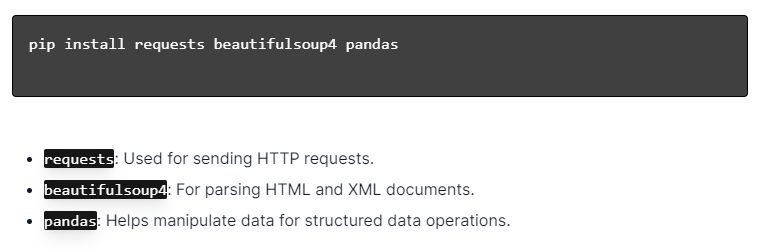
Selanjutnya, impor perpustakaan ini ke dalam skrip Anda:

Dengan demikian, setiap perpustakaan akan tersedia untuk tugas web scraping, seperti mengirim permintaan, menguraikan HTML, dan mengelola data secara efisien.
Membangun Skrip Scraping Web Sederhana
Untuk membuat skrip scraping web dinamis dasar dengan Python, pertama-tama kita harus menginstal perpustakaan yang diperlukan. Pustaka "permintaan" menangani permintaan HTTP, sementara "BeautifulSoup" mem-parsing konten HTML.
Langkah-langkah yang Harus Diikuti:
- Instal Ketergantungan:

- Impor Perpustakaan:

- Dapatkan Konten HTML:
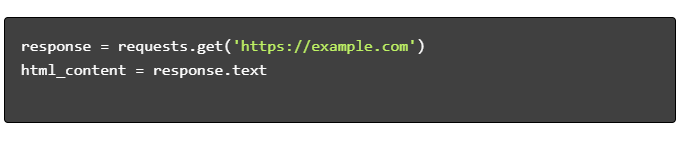
- Parsing HTML:

- Ekstrak Data:

Menangani Scraping Web Dinamis dengan Python
Situs web dinamis menghasilkan konten dengan cepat, seringkali memerlukan teknik yang lebih canggih.

Pertimbangkan langkah-langkah berikut:
- Identifikasi Elemen Target : Periksa halaman web untuk menemukan konten dinamis.
- Pilih Kerangka Python : Manfaatkan perpustakaan seperti Selenium atau Penulis Drama.
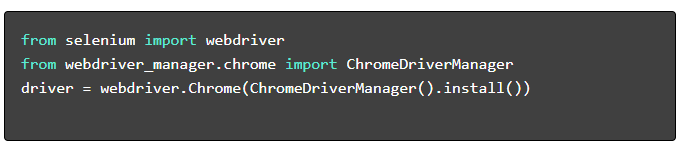
- Instal Paket yang Diperlukan :
- Siapkan WebDriver :

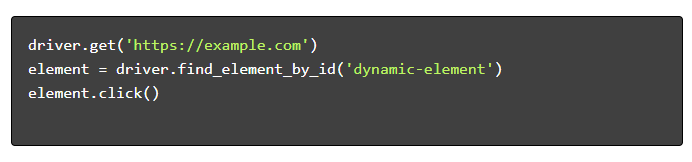
- Navigasi dan Berinteraksi :
Praktik Terbaik Pengikisan Web
Disarankan untuk mengikuti praktik terbaik pengikisan Web untuk memastikan efisiensi dan legalitas. Di bawah ini adalah pedoman utama dan strategi penanganan kesalahan:
- Hormati Robots.txt : Selalu periksa file robots.txt situs target.
- Throttling : Menerapkan penundaan untuk mencegah kelebihan beban server.
- Agen-Pengguna : Gunakan string Agen-Pengguna khusus untuk menghindari potensi pemblokiran.
- Logika Coba Ulang : Gunakan blok coba-kecuali dan atur logika coba lagi untuk menangani waktu tunggu server habis.
- Logging : Pertahankan log komprehensif untuk debugging.
- Penanganan Pengecualian : Secara khusus menangkap kesalahan jaringan, kesalahan HTTP, dan kesalahan penguraian.
- Deteksi Captcha : Menggabungkan strategi untuk mendeteksi dan memecahkan atau melewati CAPTCHA.
Tantangan Umum Pengikisan Web Dinamis
Captcha
Banyak situs web menggunakan CAPTCHA untuk mencegah bot otomatis. Untuk melewati ini:
- Gunakan layanan penyelesaian CAPTCHA seperti 2Captcha.
- Terapkan intervensi manusia untuk penyelesaian CAPTCHA.
- Gunakan proxy untuk membatasi tingkat permintaan.
Pemblokiran IP
Situs mungkin memblokir IP yang membuat terlalu banyak permintaan. Atasi ini dengan:
- Menggunakan proxy yang berputar.
- Menerapkan pembatasan permintaan.
- Menerapkan strategi rotasi agen pengguna.
Render JavaScript
Beberapa situs memuat konten melalui JavaScript. Atasi tantangan ini dengan:
- Menggunakan Selenium atau Puppeteer untuk otomatisasi browser.
- Menggunakan Scrapy-splash untuk merender konten dinamis.
- Menjelajahi browser tanpa kepala untuk berinteraksi dengan JavaScript.
Masalah hukum
Pengikisan web terkadang dapat melanggar persyaratan layanan. Pastikan kepatuhan dengan:
- Konsultasi nasihat hukum.
- Mengikis data yang dapat diakses publik.
- Menghormati arahan robots.txt.
Penguraian Data
Menangani struktur data yang tidak konsisten dapat menjadi sebuah tantangan. Solusinya meliputi:
- Menggunakan perpustakaan seperti BeautifulSoup untuk penguraian HTML.
- Menggunakan ekspresi reguler untuk ekstraksi teks.
- Memanfaatkan parser JSON dan XML untuk data terstruktur.
Menyimpan dan Menganalisis Data yang Tergores
Menyimpan dan menganalisis data yang diambil adalah langkah penting dalam web scraping. Memutuskan di mana menyimpan data bergantung pada volume dan format. Opsi penyimpanan umum meliputi:
- File CSV : Mudah untuk kumpulan data kecil dan analisis sederhana.
- Database : database SQL untuk data terstruktur; NoSQL untuk tidak terstruktur.
Setelah disimpan, analisis data dapat dilakukan menggunakan pustaka Python:
- Pandas : Ideal untuk manipulasi dan pembersihan data.
- NumPy : Efisien untuk operasi numerik.
- Matplotlib dan Seaborn : Cocok untuk visualisasi data.
- Scikit-learn : Menyediakan alat untuk pembelajaran mesin.
Penyimpanan dan analisis data yang tepat meningkatkan aksesibilitas dan wawasan data.
Kesimpulan dan Langkah Selanjutnya
Setelah mempelajari Python web scraping dinamis, sangat penting untuk menyempurnakan pemahaman tentang alat dan pustaka yang disorot.
- Tinjau Kode : Konsultasikan skrip akhir dan lakukan modularisasi jika memungkinkan untuk meningkatkan penggunaan kembali.
- Perpustakaan Tambahan : Jelajahi perpustakaan tingkat lanjut seperti Scrapy atau Splash untuk kebutuhan yang lebih kompleks.
- Penyimpanan Data : Pertimbangkan opsi penyimpanan yang tangguh—database SQL atau penyimpanan cloud untuk mengelola kumpulan data besar.
- Pertimbangan Hukum dan Etis : Terus ikuti perkembangan pedoman hukum tentang web scraping untuk menghindari potensi pelanggaran.
- Proyek Berikutnya : Menangani proyek web scraping baru dengan kompleksitas berbeda akan semakin memperkuat keterampilan ini.
Ingin mengintegrasikan web scraping dinamis profesional dengan Python ke dalam proyek Anda? Bagi tim yang memerlukan ekstraksi data berskala tinggi tanpa kerumitan penanganannya secara internal, PromptCloud menawarkan solusi yang disesuaikan. Jelajahi layanan PromptCloud untuk solusi yang kuat dan andal. Hubungi kami hari ini!