
Analisis Faktor Eksplorasi dalam R
Diterbitkan: 2017-02-16Apa itu analisis faktor eksplorasi dalam R?
Analisis Faktor Eksplorasi (EFA) atau secara kasar dikenal sebagai analisis faktor dalam R adalah teknik statistik yang digunakan untuk mengidentifikasi struktur relasional laten di antara sekumpulan variabel dan mempersempitnya menjadi sejumlah kecil variabel. Ini pada dasarnya berarti bahwa varians dari sejumlah besar variabel dapat dijelaskan oleh beberapa variabel ringkasan, yaitu faktor. Berikut ini adalah ikhtisar analisis faktor eksploratif dalam R.
Seperti namanya, EFA bersifat eksploratif – kami tidak benar-benar mengetahui variabel laten, dan langkah-langkah tersebut diulang sampai kami mencapai jumlah faktor yang lebih rendah. Dalam tutorial ini, kita akan melihat EFA menggunakan R. Sekarang, pertama-tama mari kita dapatkan ide dasar dari dataset.
1. Datanya
Dataset ini berisi 90 tanggapan untuk 14 variabel berbeda yang dipertimbangkan pelanggan saat membeli mobil. Pertanyaan survei dibingkai menggunakan skala Likert 5 poin dengan 1 sangat rendah dan 5 sangat tinggi. Variabel-variabel tersebut adalah sebagai berikut:
- Harga
- Keamanan
- Tampak luar
- Ruang dan kenyamanan
- Teknologi
- Layanan purna jual
- Nilai jual kembali
- Jenis bahan bakar
- Efisiensi bahan bakar
- Warna
- Pemeliharaan
- Uji jalan
- Ulasan produk
- Testimonial
Klik di sini untuk mengunduh kumpulan data berkode.
2. Mengimpor Data Web
Sekarang kita akan membaca dataset yang ada dalam format CSV ke dalam R dan menyimpannya sebagai variabel.
[code language=”r”] data & (amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;ampamp;amp;amp;amp;amp;amp;amp;amp;amp; ( hukum guna guna guna guna guna mencapai tujuan) amp;amp;amp;lt;- read.csv(file.choose( ),header=TRUE) [/kode]
Ini akan membuka jendela untuk memilih file CSV dan opsi `header` akan memastikan bahwa baris pertama file dianggap sebagai header. Masukkan yang berikut ini untuk melihat beberapa baris pertama dari bingkai data dan konfirmasikan bahwa data telah disimpan dengan benar.
[bahasa kode="r"] kepala(data) [/kode]
3. Instalasi Paket
Sekarang kita akan menginstal paket yang diperlukan untuk melakukan analisis lebih lanjut. Paket-paket ini adalah `psych` dan `GPArotation`. Dalam kode yang diberikan di bawah ini, kita memanggil `install.packages()` untuk instalasi.
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. Jumlah Faktor
Selanjutnya, kita akan mengetahui jumlah faktor yang akan kita pilih untuk analisis faktor. Ini dievaluasi melalui metode seperti `Analisis Paralel` dan `nilai eigen`, dll.
Analisis Paralel
Kami akan menggunakan fungsi `fa.parallel` paket `Psych` untuk menjalankan analisis paralel. Di sini kami menentukan kerangka data dan metode faktor (`minres` dalam kasus kami). Jalankan yang berikut ini untuk menemukan jumlah faktor yang dapat diterima dan buat `scree plot`:
[code language=”r”] paralel & (amp;amp;amp;amp;amp;amp;amp;amp;amp; (amp;amp;amp;amp;amp;amp;;amp;amp;amp;amp;amp;; 'minres', fa = 'fa') [/code]
Konsol akan menunjukkan jumlah maksimum faktor yang dapat kami pertimbangkan. Begini tampilannya.
“Analisis paralel menunjukkan bahwa jumlah faktor = 5 dan jumlah komponen = NA“
Diberikan di bawah ini dalam `scree plot` yang dihasilkan dari kode di atas:
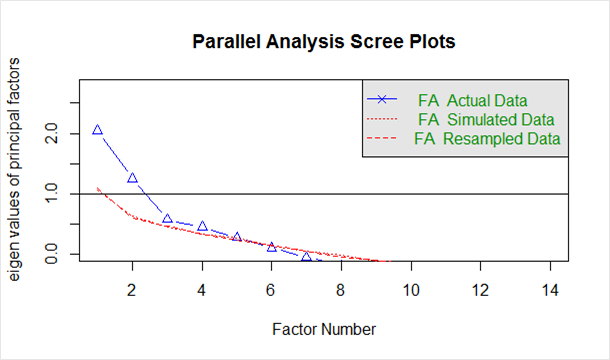
Garis biru menunjukkan nilai eigen dari data aktual dan dua garis merah (ditempatkan di atas satu sama lain) menunjukkan data simulasi dan sampel ulang. Di sini kita melihat penurunan besar dalam data aktual dan menemukan titik di mana ia mendatar ke kanan. Juga, kami menemukan titik belok – titik di mana kesenjangan antara data simulasi dan data aktual cenderung minimum.

Melihat plot ini dan analisis paralel, di mana saja antara 2 hingga 5 faktor akan menjadi pilihan yang baik.
Analisis faktor
Sekarang kita telah sampai pada sejumlah kemungkinan faktor, mari kita mulai dengan 3 sebagai jumlah faktor. Untuk melakukan analisis faktor, kita akan menggunakan fungsi `psych` package`fa(). Diberikan di bawah ini adalah argumen yang akan kami berikan:
- r – Data mentah atau korelasi atau matriks kovarians
- nfactors – Jumlah faktor yang akan diekstraksi
- rotate – Meskipun ada berbagai jenis rotasi, `Varimax` dan `Oblimin` adalah yang paling populer
- fm – Salah satu teknik ekstraksi faktor seperti `Minimum Residual (OLS)`, `Maximum Liklihood`, `Principal Axis` dll.
Dalam hal ini, kami akan memilih rotasi miring (rotate = "oblimin") karena kami percaya bahwa ada korelasi dalam faktor-faktor tersebut. Perhatikan bahwa rotasi Varimax digunakan dengan asumsi bahwa faktor-faktor tersebut sama sekali tidak berkorelasi. Kami akan menggunakan pemfaktoran `Ordinary Least Squared/Minres` (fm = “minres”), karena diketahui memberikan hasil yang serupa dengan `Maximum Likelihood` tanpa mengasumsikan distribusi normal multivariat dan memperoleh solusi melalui dekomposisi eigen berulang seperti sumbu utama.
Jalankan yang berikut ini untuk memulai analisis.
[code language=”r”] threefactor & (amp;amp;amp;amp;amp;amp;amp;amp;amp; (amp;amp;amp;amp;amp;amp;amp;;amp;amp;amp;;amp; Pengelasan) tiga faktor;- fa(data,nfactors = 3, rotate = “oblimin”,fm=”minres”) print(tiga faktor) [/code]
Berikut adalah output yang menunjukkan faktor dan pemuatan:
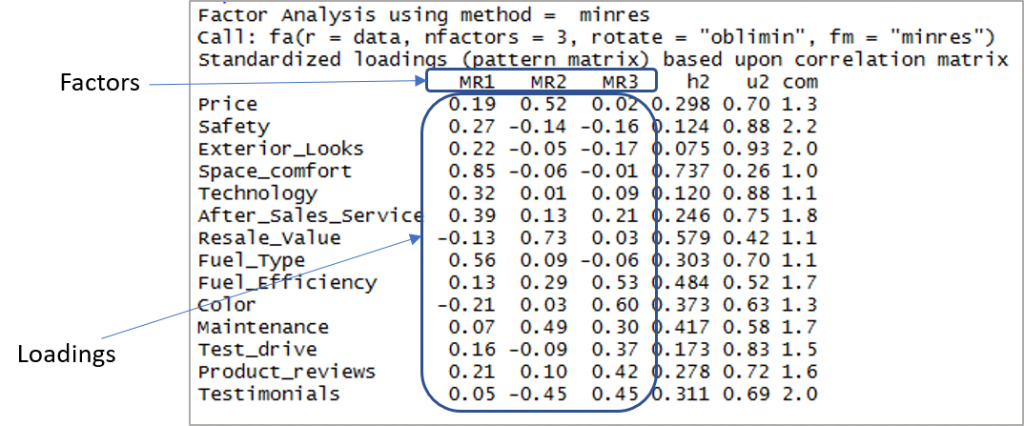
Sekarang kita perlu mempertimbangkan pembebanan lebih dari 0,3 dan tidak memuat lebih dari satu faktor. Perhatikan bahwa nilai negatif dapat diterima di sini. Jadi, pertama-tama mari kita buat batas untuk meningkatkan visibilitas.
[code language="r"] print(threefactor$loadings,cutoff = 0.3) [/code]
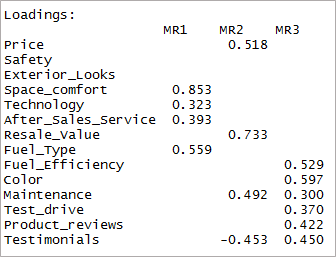
Seperti yang Anda lihat, dua variabel menjadi tidak signifikan dan dua lainnya memuat ganda. Selanjutnya, kita akan mempertimbangkan faktor '4'.
[code language=”r”] fourfactor & (amp;amp;amp;amp;amp;amp;amp;amp;amp; (amp;amp;amp;amp;amp;amp;;amp;amp;amp;amp;;amp;amp; Pengelasan) empat faktor;amp;amp;amp;lt;- fa(data,nfactors = 4, rotate = “oblimin”,fm=”minres”) print(fourfactor$loadings,cutoff = 0.3) [/code]
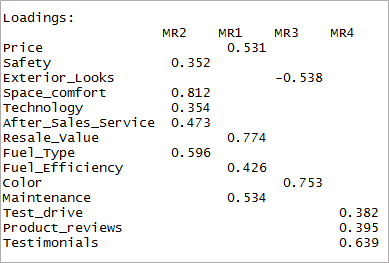
Kita dapat melihat bahwa itu hanya menghasilkan pemuatan tunggal. Ini dikenal sebagai struktur sederhana.
Tekan yang berikut untuk melihat pemetaan faktor.
[bahasa kode=”r”] fa.diagram(empat faktor) [/kode]
Uji Kecukupan
Sekarang kita telah mencapai struktur sederhana saatnya bagi kita untuk memvalidasi model kita. Mari kita lihat output analisis faktor untuk melanjutkan.

Akar berarti kuadrat residu (RMSR) adalah 0,05. Ini dapat diterima karena nilai ini seharusnya mendekati 0. Selanjutnya, kita harus memeriksa indeks RMSEA (root mean square error of approximation). Nilainya 0,001 menunjukkan model fit yang baik karena berada di bawah 0,05. Terakhir, Tucker-Lewis Index (TLI) adalah 0,93 – nilai yang dapat diterima mengingat lebih dari 0,9.
Menyebutkan Faktor

Setelah menentukan kecukupan faktor-faktor tersebut, saatnya kita menyebutkan faktor-faktor tersebut. Ini adalah sisi teoretis dari analisis di mana kita membentuk faktor-faktor tergantung pada beban variabel. Dalam hal ini, berikut adalah bagaimana faktor-faktor tersebut dapat diciptakan.
Kesimpulan
Dalam tutorial analisis dalam r ini, kita membahas ide dasar EFA (analisis faktor eksplorasi dalam R), mencakup analisis paralel, dan interpretasi scree plot. Kemudian kami pindah ke analisis faktor di R untuk mencapai struktur sederhana dan memvalidasi hal yang sama untuk memastikan kecukupan model. Akhirnya sampai pada nama-nama faktor dari variabel. Sekarang silakan, mencobanya, dan posting temuan Anda di bagian komentar.