
Suara Bazar
Diterbitkan: 2024-04-24Artikel tentang modernisasi sistem lama ini merupakan bagian pendamping dari pembicaraan yang baru-baru ini saya presentasikan di AWS Data Summit for Software Companies tentang menghasilkan nilai dari data dengan memanfaatkan praktik terbaik kami untuk memastikan keberhasilan dalam proyek pembelajaran mesin. Anda dapat langsung turun ke bawah di sini untuk menontonnya jika Anda mau.
Jujur saja: perangkat lunak lebih mudah untuk ditulis daripada dipelihara. Inilah sebabnya kami, sebagai insinyur perangkat lunak, lebih memilih untuk “merobeknya dan memulai kembali” daripada mencoba memahami apa yang dipikirkan pengembang lain (atau diri kami di masa lalu). Tampaknya kita secara kolektif lupa bahwa “program harus ditulis agar dapat dibaca oleh manusia, dan hanya secara kebetulan agar dapat dijalankan oleh mesin”.
Anda tahu itu benar - kita semua harus dengan susah payah menelusuri kode spageti dan abstraksi tipis gaya lama yang menggali inti program hanya untuk menemukan apa pun selain kekacauan di dasar piring kita.
Sangat mudah untuk berteriak “WTF” dan menyalahkan pengembang sebelumnya, namun kenyataannya seringkali lebih rumit. Kita tidak dapat melihat masa depan, sehingga tidak mungkin untuk memahami bagaimana persyaratan, teknologi, atau tujuan bisnis akan berkembang ketika kita merancang sistem yang baru. Akibatnya, sistem menjadi tidak dapat dibaca karena cakupannya meningkat seiring dengan ketergantungan bisnis terhadap sistem tersebut. Ini sedikit paradoks: sistem yang lebih tua dan lebih sulit dipelihara sering kali memberikan nilai paling besar. Hal-hal tersebut sulit untuk dikerjakan karena mereka telah tumbuh bersama perusahaan, dan menakutkan untuk dikerjakan karena melanggarnya dapat menjadi sebuah bencana.
Di sinilah saya memanggil Anda: jika Anda menyukai masalah yang sulit dan bermanfaat… cobalah. Ambil sistem tertua yang Anda miliki dan buat agar dapat dipelihara. Anda tahu yang saya bicarakan - yang tidak akan "dimiliki" oleh siapa pun. Departemen lain bergantung pada hal itu tetapi para insinyur membencinya. Yang pertama Anda harus menambal Log4Shell. Lakukan. Saya tantang kamu.
Baru-baru ini saya mendapat kesempatan untuk memperbarui sistem pembelajaran mesin berusia satu dekade di Bazaarvoice. Di permukaan, kedengarannya tidak menarik : benda ini bahkan tidak memiliki jaringan saraf! Siapa peduli! Ya… itu penting. Sistem ini memproses hampir setiap ulasan produk buatan pengguna yang diterima oleh Bazaarvoice — hampir 9 juta per bulan — dan melakukannya dengan 90 juta panggilan inferensi ke model pembelajaran mesin. Yup — 90 juta kesimpulan! Skalanya sangat besar, dan saya tidak sabar untuk menyelaminya.
Dalam postingan ini, saya akan berbagi bagaimana memodernisasi sistem lama ini melalui arsitektur ulang, alih-alih menulis ulang, memungkinkan kami menjadikannya skalabel dan hemat biaya tanpa harus menghapus semua kode dan memulai dari awal. Sistem yang dihasilkan tidak memiliki server, terkontainer, dan dapat dipelihara sekaligus mengurangi biaya hosting kami hingga hampir 80%.
Apa itu sistem warisan?
Sistem warisan mengacu pada perangkat lunak dan/atau perangkat keras komputasi yang menua dan masih beroperasi. Meskipun masih memenuhi tujuan awalnya, namun tidak memiliki skalabilitas untuk pertumbuhan di masa depan.
Sistem warisan lama
Pertama, mari kita lihat apa yang kita hadapi di sini. Sistem lama yang diperbarui oleh tim saya memoderasi konten buatan pengguna untuk semua Bazaarvoice. Secara khusus, ini menentukan apakah setiap konten sesuai untuk situs web klien kami.

Hal ini terdengar mudah – menghilangkan pelanggaran yang nyata seperti ujaran kebencian, bahasa kotor, atau ajakan – namun dalam praktiknya, hal ini jauh lebih bernuansa. Setiap klien memiliki persyaratan unik untuk apa yang mereka anggap tepat. Merek bir, misalnya, mengharapkan diskusi tentang alkohol, namun merek anak-anak mungkin tidak mengharapkannya. Kami menangkap opsi khusus klien ini saat kami menerima klien baru, dan tim Layanan Klien kami mengkodekannya ke dalam database manajemen.
Untuk menambah kerumitan, kami juga mengambil sampel sebagian konten kami untuk dimoderasi oleh moderator manusia. Hal ini memungkinkan kami untuk terus mengukur performa model kami dan menemukan peluang untuk membuat lebih banyak model.
Arsitektur lengkap sistem lama kami ditunjukkan di bawah ini:
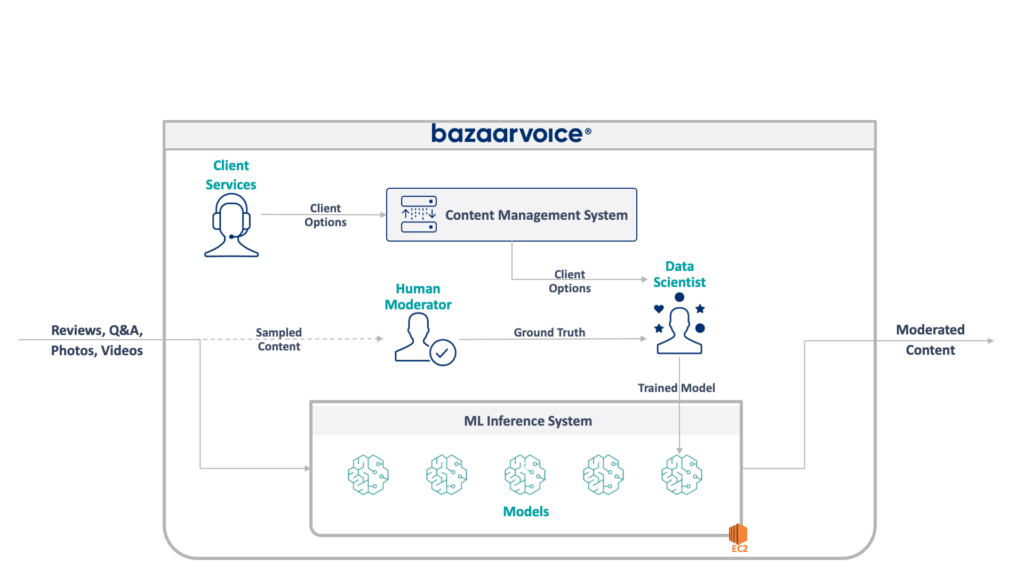
Sistem ini mempunyai beberapa kelemahan serius. Secara khusus — semua model dihosting pada satu instans EC2. Hal ini bukan disebabkan oleh rekayasa yang buruk - hanya ketidakmampuan pemrogram asli untuk meramalkan skala yang diinginkan oleh perusahaan. Tidak ada yang berpikir bahwa itu akan tumbuh sebesar itu.
Selain itu, sistem ini mengalami penolakan dari pengembang: sistem ini ditulis dalam bahasa Scala, yang hanya dipahami oleh sedikit insinyur. Oleh karena itu, sering kali diabaikan untuk perbaikan karena tidak ada yang mau menyentuhnya.
Hasilnya, sistem ini terus berkembang dengan cara yang tetap menyala. Setelah kami merancang ulang, itu berjalan pada satu instance x1e.8xlarge. Benda ini memiliki ram hampir satu terabyte dan biaya pengoperasiannya sekitar $5.000/bulan (tanpa syarat). Namun jangan khawatir, kami baru saja meluncurkan yang kedua untuk redundansi dan yang ketiga untuk QA.
Sistem ini mahal untuk dijalankan dan memiliki risiko kegagalan yang tinggi (satu model yang buruk dapat menghentikan seluruh layanan). Selain itu, basis kode belum dikembangkan secara aktif sehingga sudah ketinggalan zaman dengan paket ilmu data modern dan tidak mengikuti praktik standar kami untuk layanan yang ditulis dalam Scala.
Sebuah sistem baru
Saat mendesain ulang sistem ini, kami mempunyai tujuan yang jelas: menjadikannya terukur. Mengurangi biaya operasional adalah tujuan kedua, begitu pula pelonggaran manajemen model dan kode.
Desain baru yang kami buat diilustrasikan di bawah ini:

Pendekatan kami untuk menyelesaikan semua ini adalah dengan menempatkan setiap model pembelajaran mesin pada titik akhir SageMaker Tanpa Server yang terisolasi. Seperti fungsi AWS Lambda, titik akhir tanpa server akan mati saat tidak digunakan — sehingga menghemat biaya waktu proses untuk model yang jarang digunakan. Mereka juga dapat melakukan perluasan dengan cepat sebagai respons terhadap peningkatan lalu lintas.

Selain itu, kami memaparkan opsi klien ke satu layanan mikro yang merutekan konten ke model yang sesuai. Ini adalah sebagian besar kode baru yang harus kami tulis: API kecil yang mudah dipelihara dan memudahkan ilmuwan data kami memperbarui dan menerapkan model baru.
Pendekatan ini memiliki manfaat sebagai berikut:
- Mengurangi waktu untuk menilai lebih dari 6x. Secara khusus, perutean lalu lintas ke model yang ada dapat dilakukan secara instan, dan penerapan model baru dapat dilakukan dalam waktu kurang dari 5 menit, bukan 30 menit.
- Skalakan tanpa batas – saat ini kami memiliki 400 model namun berencana untuk meningkatkannya hingga ribuan untuk terus meningkatkan jumlah konten yang dapat kami moderasi secara otomatis
- Melihat pengurangan biaya sebesar 82% dengan beralih dari EC2 karena fungsinya dimatikan saat tidak digunakan, dan kami tidak membayar untuk mesin papan atas yang kurang dimanfaatkan
Namun, sekadar merancang arsitektur yang ideal bukanlah bagian tersulit yang menarik dalam membangun kembali sistem lama — Anda harus bermigrasi ke sana.
Tantangan pertama kami dalam migrasi adalah mencari tahu bagaimana cara memigrasikan model Java WEKA agar berjalan di SageMaker, apalagi SageMaker Tanpa Server.
Untungnya, SageMaker menerapkan model dalam container Docker, jadi setidaknya kami dapat membekukan Java dan versi dependensi agar sesuai dengan kode lama kami. Hal ini akan membantu memastikan model yang dihosting di sistem baru memberikan hasil yang sama seperti model lama.

Untuk membuat container kompatibel dengan SageMaker, yang perlu Anda lakukan hanyalah mengimplementasikan beberapa titik akhir HTTP tertentu:
-
POST /invocation— menerima masukan, melakukan inferensi, dan mengembalikan hasil. -
GET /ping— mengembalikan 200 jika server JVM sehat
(Kami memilih untuk mengabaikan semua masalah seputar wadah multimodel BYO dan perangkat inferensi SageMaker.)
Beberapa abstraksi singkat seputar com.sun.net.httpserver.HttpServer dan kami siap berangkat.
Dan tahukah Anda? Ini sebenarnya cukup menyenangkan. Bermain-main dengan kontainer Docker dan memaksakan sesuatu yang berumur 10 tahun ke dalam SageMaker Serverless memiliki sedikit kesan mengutak-atik. Sangat menyenangkan ketika kami membuatnya berfungsi — terutama ketika kami mendapatkan kode sistem lama untuk membangunnya di tumpukan sbt baru kami, bukan di maven.
Tumpukan sbt baru memudahkan pengerjaannya, dan containerisasi memastikan kami bisa mendapatkan perilaku yang tepat saat berjalan di lingkungan SageMaker.
Bermigrasi ke sistem baru
Jadi kita memiliki modelnya di dalam container dan dapat menerapkannya ke SageMaker — hampir selesai, bukan? Tidak terlalu.
Pelajaran sulit tentang migrasi ke arsitektur baru adalah Anda harus membangun tiga kali lipat sistem sebenarnya hanya untuk mendukung migrasi. Selain sistem baru, kami harus membangun:
- Pipeline pengambilan data di sistem lama untuk mencatat input dan output dari model. Kami menggunakan ini untuk mengonfirmasi bahwa sistem baru akan memberikan hasil yang sama
- Saluran pemrosesan data di sistem baru untuk menghitung hasil dan membandingkannya dengan data dari sistem lama. Hal ini melibatkan pengukuran dalam jumlah besar dengan Datadog dan diperlukan untuk menawarkan kemampuan memutar ulang data saat kami menemukan perbedaan
- Sistem penerapan model lengkap untuk menghindari dampak pada pengguna sistem lama (yang hanya akan mengunggah model ke S3). Kami tahu kami ingin memindahkannya ke API pada akhirnya, namun untuk rilis awal, kami harus melakukannya dengan lancar
Semua ini adalah kode sekali pakai yang kami tahu dapat kami buang setelah kami selesai memigrasikan semua pengguna, namun kami masih harus membuatnya dan memastikan bahwa output sistem baru cocok dengan yang lama.
Harapkan ini di muka.
Meskipun membangun alat dan sistem migrasi memerlukan lebih dari 60% waktu teknis kami dalam proyek ini, hal ini juga merupakan pengalaman yang menyenangkan. Pengujian unit menjadi lebih seperti eksperimen ilmu data: kami menulis seluruh rangkaian untuk memastikan bahwa keluaran kami sama persis . Cara berpikir yang berbeda itulah yang membuat pekerjaan menjadi lebih menyenangkan. Sebuah langkah di luar kotak normal kami, jika Anda mau.
Memodernisasi sistem warisan melalui re-arsitektur
Lain kali Anda tergoda untuk membangun kembali sistem dari kode ke atas, saya ingin mendorong Anda untuk mencoba memigrasikan arsitekturnya, bukan kodenya. Anda akan menemukan tantangan teknis yang menarik dan bermanfaat dan kemungkinan besar akan lebih menikmatinya daripada men-debug kasus edge yang tidak terduga pada kode baru Anda.
Ingin mempelajari lebih lanjut? Tonton ceramah yang saya berikan di AWS Data Summit di bawah ini yang mempelajari sisi MLOps.