
Cara Mencadangkan Data Universal Analytics Anda Ke BigQuery Dengan R
Diterbitkan: 2023-09-26Universal Analytics (UA) akhirnya dihentikan, dan data kami kini mengalir bebas ke properti Google Analytics 4 (GA4). Mungkin Anda tergoda untuk tidak pernah melihat pengaturan UA lagi, namun, sebelum meninggalkan UA, penting bagi kami untuk menyimpan data yang sudah diproses, jika kami perlu menganalisisnya di masa mendatang. Untuk menyimpan data Anda, tentu saja kami merekomendasikan BigQuery, layanan gudang data Google, dan di blog ini kami akan menunjukkan kepada Anda data apa saja yang perlu dicadangkan dari UA, dan cara melakukannya!
Untuk mengunduh data kami, kami akan menggunakan API Google Analytics. Kami akan menulis skrip yang akan mendownload data yang diperlukan dari UA dan mengunggahnya ke BigQuery, semuanya sekaligus. Untuk tugas ini, kami sangat menyarankan penggunaan R, karena paket googleAnalyticsR dan bigQueryR membuat pekerjaan ini sangat sederhana, dan kami telah menulis tutorial untuk R karena alasan ini!
Panduan ini tidak akan membahas langkah-langkah yang lebih rumit dalam menyiapkan autentikasi, seperti mengunduh file kredensial Anda. Untuk informasi tentang hal itu, dan informasi lebih lanjut tentang cara mengupload data ke BigQuery, lihat blog kami tentang mengupload data ke BigQuery dari R dan Python!
Mencadangkan Data UA Anda Dengan R
Seperti biasa untuk skrip R apa pun, langkah pertama adalah memuat perpustakaan kita. Untuk skrip ini kita memerlukan yang berikut ini:
perpustakaan(googleAuthR)
perpustakaan (googleAnalyticsR)
perpustakaan (bigQueryR)
Jika Anda belum pernah menggunakan pustaka ini sebelumnya, jalankan install.packages(<PACKAGE NAME>) di konsol untuk menginstalnya.
Kami kemudian perlu menyortir semua otorisasi kami. Untuk melakukan ini, Anda dapat menjalankan kode berikut dan mengikuti instruksi apa pun yang diberikan kepada Anda:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client(“C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json”)
bqr_auth(email = “<email Anda di sini>”)
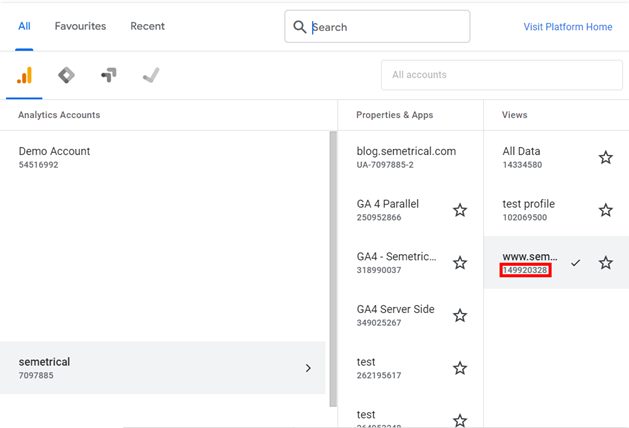
ga_id <- <GA LIHAT ID ANDA DI SINI>
Ga_id dapat ditemukan di bawah nama tampilan saat Anda memilihnya di UA, seperti yang ditunjukkan di bawah ini:
Selanjutnya, kita harus memutuskan data apa yang sebenarnya akan diambil dari UA. Kami merekomendasikan menarik yang berikut ini:
| Dimensi Cakupan Sesi | Dimensi Cakupan Peristiwa | Dimensi Cakupan Tampilan Halaman |
| ID Klien | ID Klien | Jalur Halaman |
| Stempel waktu | Stempel waktu | Stempel waktu |
| Sumber / Media | Kategori Acara | Sumber / Media |
| Kategori Perangkat | Aksi Peristiwa | Kategori Perangkat |
| Kampanye | Label Acara | Kampanye |
| Pengelompokan Saluran | Sumber / Media | Pengelompokan Saluran |
| Kampanye |
Menempatkannya ke dalam tiga tabel di BigQuery sudah cukup untuk semua potensi kebutuhan data UA Anda di masa mendatang. Untuk mengambil data ini dari UA, pertama-tama Anda harus menentukan rentang tanggal. Masuk ke platform UA dan lihat salah satu laporan Anda untuk mengetahui kapan pengumpulan data pertama kali dimulai. Lalu, tentukan rentang tanggal mulai saat itu hingga hari sebelum Anda menjalankan skrip, yang merupakan hari terakhir di mana Anda akan memiliki data selama 24 jam penuh (dan jika Anda melakukan ini setelah UA selesai matahari terbenam, akan tetap menyertakan 100% data Anda yang tersedia). Pengumpulan data kami dimulai pada Mei 2017, jadi saya menulis:

tanggal <- c(“01-05-2017”, Sys.Date()-1)
Sekarang, kita perlu menentukan apa saja yang perlu ditarik dari UA sesuai tabel di atas. Untuk melakukan ini, kita perlu menjalankan metode google_analytics() tiga kali, karena Anda tidak dapat mengkueri dimensi cakupan yang berbeda secara bersamaan. Anda dapat menyalin kode berikut dengan tepat:
sesi tarikan <- google_analytics(ga_id,
rentang_tanggal = tanggal,
metrik = c(“sesi”),
dimensi = c("Id Klien", "tanggalJamMenit",
“sourceMedium”, “deviceCategory”, “kampanye”, “pengelompokan saluran”),
anti_sample = BENAR)
tarikan acara <- google_analytics(ga_id,
rentang_tanggal = tanggal,
metrik = c(“totalEvents”, “eventValue”),
dimensi = c(“clientId”, “dateHourMinute”, “eventCategory”, “eventAction”, “eventLabel”, “sourceMedium”, “campaign”),
anti_sample = BENAR)
pvpull <- google_analytics(ga_id,
rentang_tanggal = tanggal,
metrik = c(“tayangan halaman”),
dimensi = c(“pagePath”, “dateHourMinute”, “sourceMedium”, “deviceCategory”, “campaign”, “channelGrouping”),
anti_sample = BENAR)
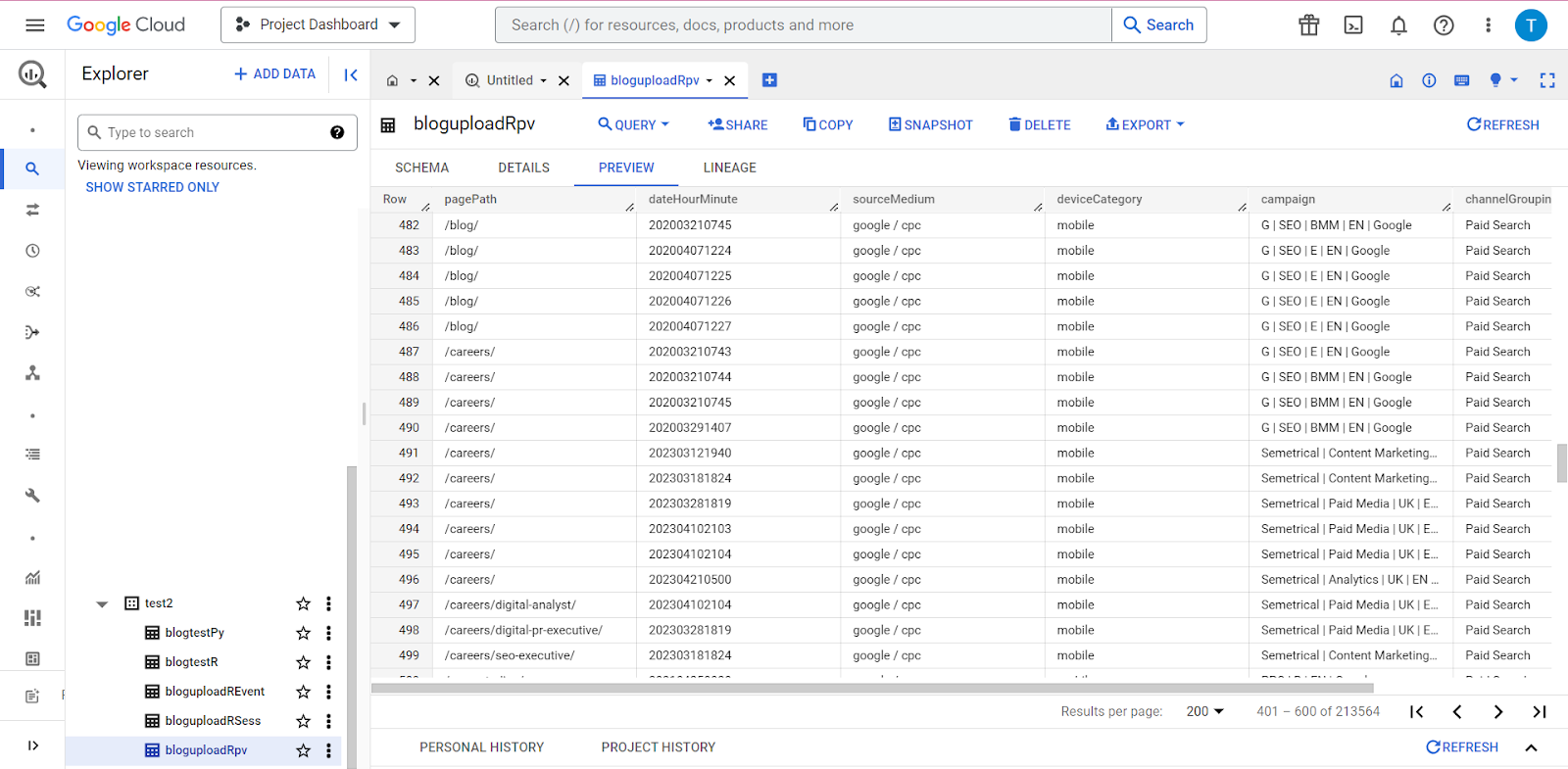
Ini akan menempatkan semua data Anda dengan rapi ke dalam tiga bingkai data berjudul sessionpull untuk dimensi cakupan sesi, eventspull untuk dimensi cakupan peristiwa, dan pvpull untuk dimensi cakupan tayangan laman.
Sekarang kita perlu mengunggah data ke BigQuery, kodenya akan terlihat seperti ini, diulang tiga kali untuk setiap kerangka data:
bqr_upload_data(“<proyek Anda>”, “<kumpulan data Anda>”, “<tabel Anda>”, <bingkai data Anda>)
Dalam kasus saya, ini berarti kode saya berbunyi:
bqr_upload_data("proyek saya", "test2", "bloguploadRSess", sessionpull)
bqr_upload_data("proyek saya", "test2", "bloguploadREvent", eventspull)
bqr_upload_data("proyek-saya", "test2", "bloguploadRpv", pvpull)
Setelah semuanya ditulis, Anda dapat mengatur skrip Anda untuk berjalan, duduk santai, dan bersantai! Setelah selesai, Anda dapat membuka BigQuery dan Anda akan melihat semua data Anda di tempatnya sekarang!
Dengan data UA yang disimpan dengan aman saat cuaca buruk, Anda dapat menaruh fokus penuh untuk memaksimalkan potensi penyiapan GA4 – dan Semetrical siap membantu dalam hal tersebut! Kunjungi blog kami untuk informasi selengkapnya tentang cara memaksimalkan data Anda. Atau, untuk dukungan lebih lanjut mengenai segala hal tentang analitik, lihat layanan analisis web kami untuk mengetahui bagaimana kami dapat membantu Anda.