
Mengatasi Tantangan Teknis dalam Web Scraping: Solusi Pakar
Diterbitkan: 2024-03-29Pengikisan web adalah praktik yang memiliki banyak tantangan teknis, bahkan bagi penambang data berpengalaman. Hal ini memerlukan penggunaan teknik pemrograman untuk memperoleh dan mengambil data dari situs web, yang tidak selalu mudah karena sifat teknologi web yang rumit dan beragam.
Selain itu, banyak situs web yang menerapkan langkah-langkah perlindungan untuk mencegah pengambilan data, sehingga penting bagi scraper untuk menegosiasikan mekanisme anti-scraping, konten dinamis, dan struktur situs yang rumit.
Meskipun tujuan untuk memperoleh informasi yang berguna dengan cepat tampak sederhana, untuk mencapainya memerlukan mengatasi beberapa hambatan yang berat, menuntut kemampuan analitis dan teknis yang kuat.
Menangani Konten Dinamis
Konten dinamis, yang mengacu pada informasi halaman web yang diperbarui berdasarkan tindakan pengguna atau dimuat setelah tampilan halaman awal, biasanya menimbulkan tantangan bagi alat pengikis web.
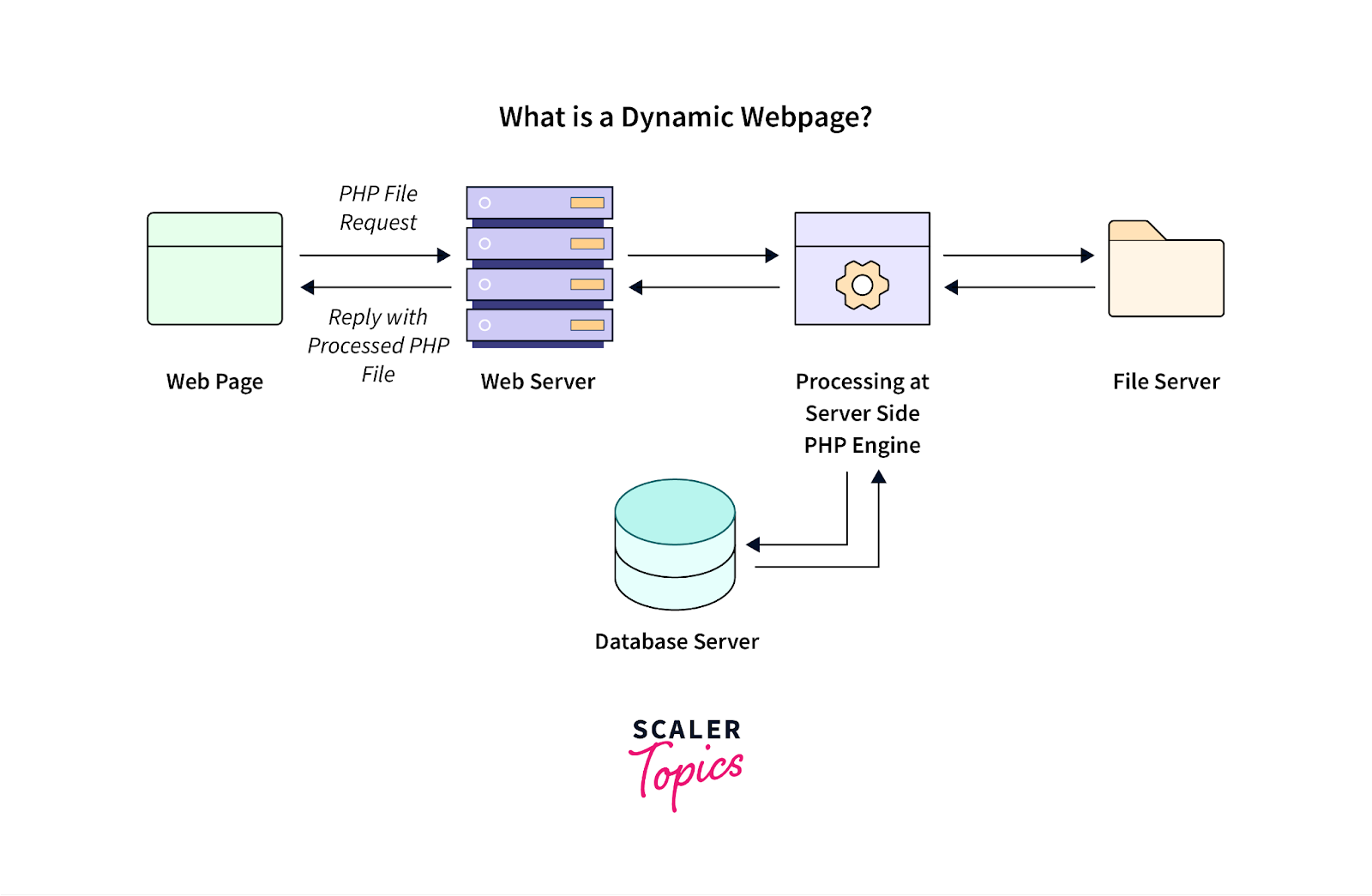
Sumber Gambar: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Konten dinamis seperti ini sering digunakan dalam aplikasi web kontemporer yang dibangun menggunakan kerangka JavaScript. Agar berhasil mengelola dan mengekstrak data dari konten yang dihasilkan secara dinamis, pertimbangkan praktik terbaik berikut:
- Pertimbangkan untuk menggunakan alat otomatisasi web seperti Selenium, Puppeteer, atau Playwright, yang memungkinkan web scraper Anda berperilaku di halaman web serupa dengan yang dilakukan pengguna asli.
- Terapkan teknik penanganan WebSockets atau AJAX jika situs web menggunakan teknologi ini untuk memuat konten secara dinamis.
- Tunggu hingga elemen dimuat dengan menggunakan menunggu eksplisit dalam kode pengikisan Anda untuk memastikan bahwa konten dimuat sepenuhnya sebelum mencoba mengikisnya.
- Jelajahi menggunakan browser tanpa kepala yang dapat menjalankan JavaScript dan merender halaman penuh termasuk konten yang dimuat secara dinamis.
Dengan menguasai strategi ini, scraper dapat secara efektif mengekstraksi data bahkan dari situs web yang paling interaktif dan berubah secara dinamis.
Teknologi Anti Goresan
Merupakan hal yang umum bagi pengembang web untuk menerapkan langkah-langkah yang bertujuan mencegah pengambilan data yang tidak disetujui untuk melindungi situs web mereka. Langkah-langkah ini dapat menimbulkan tantangan yang signifikan bagi web scraper. Berikut adalah beberapa metode dan strategi untuk menavigasi teknologi anti-goresan:

Sumber Gambar: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Anjak Piutang Dinamis : Situs web dapat menghasilkan konten secara dinamis, sehingga lebih sulit untuk memprediksi URL atau struktur HTML. Memanfaatkan alat yang dapat mengeksekusi JavaScript dan menangani permintaan AJAX.
- Pemblokiran IP : Permintaan yang sering dari IP yang sama dapat menyebabkan pemblokiran. Gunakan kumpulan server proxy untuk merotasi IP dan meniru pola lalu lintas manusia.
- CAPTCHA : Ini dirancang untuk membedakan antara manusia dan bot. Terapkan layanan penyelesaian CAPTCHA atau pilih entri manual jika memungkinkan.
- Pembatasan Tarif : Untuk menghindari batas tarif yang tersandung, batasi tarif permintaan Anda dan terapkan penundaan acak antar permintaan.
- Agen Pengguna : Situs web mungkin memblokir agen pengguna scraper yang dikenal. Putar agen pengguna untuk meniru browser atau perangkat yang berbeda.
Mengatasi tantangan ini memerlukan pendekatan canggih yang menghormati persyaratan layanan situs web sekaligus mengakses data yang dibutuhkan secara efisien.
Berurusan dengan CAPTCHA dan Perangkap Honeypot
Pencakar web sering kali menghadapi tantangan CAPTCHA yang dirancang untuk membedakan pengguna manusia dan bot. Untuk mengatasinya diperlukan:
- Memanfaatkan layanan penyelesaian CAPTCHA yang memanfaatkan kemampuan manusia atau AI.
- Menerapkan penundaan dan mengacak permintaan untuk meniru perilaku manusia.
Untuk jebakan honeypot, yang tidak terlihat oleh pengguna tetapi menjebak skrip otomatis:
- Periksa dengan cermat kode situs web untuk menghindari interaksi dengan tautan tersembunyi.
- Menerapkan praktik pengikisan yang tidak terlalu agresif agar tidak terdeteksi.
Pengembang harus secara etis menyeimbangkan efektivitas dengan menghormati persyaratan situs web dan pengalaman pengguna.
Efisiensi Pengikisan dan Optimasi Kecepatan
Proses pengikisan web dapat ditingkatkan dengan mengoptimalkan efisiensi dan kecepatan. Untuk mengatasi tantangan dalam domain ini:
- Manfaatkan multi-threading untuk memungkinkan ekstraksi data secara simultan, sehingga meningkatkan throughput.
- Manfaatkan browser tanpa kepala untuk eksekusi lebih cepat dengan menghilangkan pemuatan konten grafis yang tidak perlu.
- Optimalkan kode scraping untuk dieksekusi dengan latensi minimal.
- Terapkan pembatasan permintaan yang sesuai untuk mencegah larangan IP sambil mempertahankan kecepatan yang stabil.
- Cache konten statis untuk menghindari pengunduhan berulang, menghemat bandwidth dan waktu.
- Gunakan teknik pemrograman asinkron untuk mengoptimalkan operasi I/O jaringan.
- Pilih penyeleksi dan parsing pustaka yang efisien untuk mengurangi overhead manipulasi DOM.
Dengan menggabungkan strategi ini, web scraper dapat mencapai kinerja yang kuat dengan meminimalkan gangguan operasional.

Ekstraksi dan Parsing Data
Pengikisan web memerlukan ekstraksi dan penguraian data yang tepat, sehingga menghadirkan tantangan tersendiri. Berikut cara untuk mengatasinya:
- Gunakan perpustakaan tangguh seperti BeautifulSoup atau Scrapy, yang dapat menangani berbagai struktur HTML.
- Terapkan ekspresi reguler dengan hati-hati untuk menargetkan pola tertentu dengan tepat.
- Manfaatkan alat otomatisasi browser seperti Selenium untuk berinteraksi dengan situs web yang banyak menggunakan JavaScript, memastikan data dirender sebelum ekstraksi.
- Gunakan pemilih XPath atau CSS untuk menentukan elemen data dalam DOM secara akurat.
- Tangani penomoran halaman dan pengguliran tak terbatas dengan mengidentifikasi dan memanipulasi mekanisme yang memuat konten baru (misalnya, memperbarui parameter URL atau menangani panggilan AJAX).
Menguasai Seni Mengikis Web
Pengikisan web adalah keterampilan yang sangat berharga di dunia berbasis data. Mengatasi tantangan teknis—mulai dari konten dinamis hingga deteksi bot—membutuhkan ketekunan dan kemampuan beradaptasi. Pengikisan web yang sukses melibatkan perpaduan pendekatan berikut:
- Terapkan perayapan cerdas untuk menghormati sumber daya situs web dan bernavigasi tanpa deteksi.
- Memanfaatkan penguraian tingkat lanjut untuk menangani konten dinamis, memastikan ekstraksi data kuat terhadap perubahan.
- Gunakan layanan penyelesaian CAPTCHA secara strategis untuk mempertahankan akses tanpa mengganggu aliran data.
- Kelola alamat IP dengan cermat dan header permintaan untuk menyamarkan aktivitas pengikisan.
- Tangani perubahan struktur situs web dengan memperbarui skrip parser secara rutin.
Dengan menguasai teknik-teknik ini, seseorang dapat dengan mahir menavigasi seluk-beluk perayapan web dan membuka penyimpanan data berharga yang sangat besar.
Mengelola Proyek Pengikisan Skala Besar
Proyek web scraping skala besar memerlukan manajemen yang kuat untuk memastikan efisiensi dan kepatuhan. Bermitra dengan penyedia layanan web scraping menawarkan beberapa keuntungan:

Mempercayakan proyek scraping kepada profesional dapat mengoptimalkan hasil dan meminimalkan beban teknis pada tim internal Anda.
FAQ
Apa batasan dari web scraping?
Pengikisan web menghadapi kendala tertentu yang harus dipertimbangkan sebelum memasukkannya ke dalam operasi mereka. Secara hukum, beberapa situs web melarang pengikisan melalui syarat dan ketentuan atau file robot.txt; mengabaikan pembatasan ini dapat mengakibatkan konsekuensi yang parah.
Secara teknis, situs web dapat menerapkan tindakan pencegahan terhadap pengikisan seperti CAPTCHA, blok IP, dan honey pot, sehingga mencegah akses tidak sah. Keakuratan data yang diekstraksi juga dapat menjadi masalah karena rendering dinamis dan sumber yang sering diperbarui. Terakhir, web scraping memerlukan pengetahuan teknis, investasi sumber daya, dan upaya berkelanjutan – yang menghadirkan tantangan, terutama bagi orang-orang non-teknis.
Mengapa pengikisan data menjadi masalah?
Masalah muncul terutama ketika pengikisan data terjadi tanpa izin yang diperlukan atau perilaku etis. Mengekstraksi informasi rahasia melanggar norma privasi dan melanggar undang-undang yang dirancang untuk melindungi kepentingan individu.
Penggunaan scraping yang berlebihan akan membebani server target, sehingga berdampak negatif terhadap kinerja dan ketersediaan. Pencurian kekayaan intelektual merupakan kekhawatiran lain yang timbul dari pengikisan ilegal karena kemungkinan tuntutan hukum pelanggaran hak cipta yang diprakarsai oleh pihak-pihak yang dirugikan.
Oleh karena itu, mematuhi ketentuan kebijakan, menjunjung tinggi standar etika, dan mencari persetujuan jika diperlukan tetap menjadi hal yang penting saat melakukan tugas pengumpulan data.
Mengapa web scraping mungkin tidak akurat?
Pengikisan web, yang memerlukan ekstraksi data secara otomatis dari situs web melalui perangkat lunak khusus, tidak menjamin keakuratan penuh karena berbagai faktor. Misalnya, modifikasi struktur situs web dapat menyebabkan alat pengikis tidak berfungsi atau menangkap informasi yang salah.
Selain itu, situs web tertentu menerapkan tindakan anti-scraping seperti pengujian CAPTCHA, pemblokiran IP, atau rendering JavaScript, yang menyebabkan data hilang atau terdistorsi. Terkadang, pengawasan pengembang selama pembuatan juga berkontribusi terhadap hasil yang kurang optimal.
Namun, bermitra dengan penyedia layanan web scraping yang ahli dapat meningkatkan presisi karena mereka memberikan pengetahuan dan aset yang diperlukan untuk membuat scraper yang tangguh dan gesit yang mampu mempertahankan tingkat akurasi tinggi meskipun tata letak situs web berubah. Para ahli yang terampil menguji dan memvalidasi scraper ini dengan cermat sebelum penerapannya, untuk memastikan kebenarannya selama proses ekstraksi.
Apakah pengikisan web itu membosankan?
Memang benar, terlibat dalam aktivitas web scraping terbukti melelahkan dan menuntut, terutama bagi mereka yang tidak memiliki keahlian coding atau pemahaman tentang platform digital. Tugas-tugas tersebut memerlukan pembuatan kode khusus, memperbaiki scraper yang rusak, mengelola arsitektur server, dan terus mengikuti perubahan yang terjadi dalam situs web yang ditargetkan – semuanya memerlukan kemampuan teknis yang besar serta investasi besar dalam hal pengeluaran waktu.
Memperluas upaya web scraping dasar menjadi semakin rumit mengingat pertimbangan seputar kepatuhan terhadap peraturan, manajemen bandwidth, dan penerapan sistem komputasi terdistribusi.
Sebaliknya, memilih layanan web scraping profesional secara signifikan mengurangi beban terkait melalui penawaran siap pakai yang dirancang sesuai dengan permintaan spesifik pengguna. Akibatnya, pelanggan berkonsentrasi terutama pada pemanfaatan data yang dikumpulkan sambil menyerahkan logistik pengumpulan kepada tim khusus yang terdiri dari pengembang terampil dan spesialis TI yang bertanggung jawab atas optimalisasi sistem, alokasi sumber daya, dan menangani pertanyaan hukum, sehingga secara nyata mengurangi kebosanan secara keseluruhan terkait inisiatif web scraping.