
Perayap Web Python – Tutorial Langkah demi Langkah
Diterbitkan: 2023-12-07Perayap web adalah alat menarik dalam dunia pengumpulan data dan pengikisan web. Mereka mengotomatiskan proses navigasi web untuk mengumpulkan data, yang dapat digunakan untuk berbagai tujuan, seperti pengindeksan mesin pencari, penambangan data, atau analisis persaingan. Dalam tutorial ini, kita akan memulai perjalanan informatif untuk membangun perayap web dasar menggunakan Python, bahasa yang dikenal karena kesederhanaannya dan kemampuannya yang hebat dalam menangani data web.
Python, dengan ekosistem perpustakaannya yang kaya, menyediakan platform luar biasa untuk mengembangkan perayap web. Baik Anda seorang pengembang pemula, penggemar data, atau sekadar ingin tahu tentang cara kerja perayap web, panduan langkah demi langkah ini dirancang untuk memperkenalkan Anda pada dasar-dasar perayapan web dan membekali Anda dengan keterampilan membuat perayap sendiri .
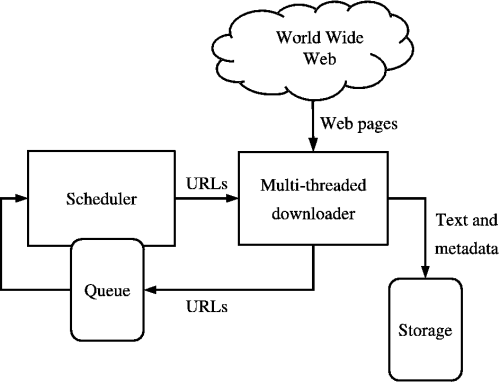
Sumber: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Perayap Web Python – Cara Membuat Perayap Web
Langkah 1: Memahami Dasar-dasarnya
Perayap web, juga dikenal sebagai laba-laba, adalah program yang menelusuri World Wide Web dengan cara yang metodis dan otomatis. Untuk crawler kami, kami akan menggunakan Python karena kesederhanaan dan perpustakaannya yang kuat.
Langkah 2: Siapkan Lingkungan Anda
Instal Python : Pastikan Anda telah menginstal Python. Anda dapat mengunduhnya dari python.org.
Instal Perpustakaan : Anda memerlukan permintaan untuk membuat permintaan HTTP dan BeautifulSoup dari bs4 untuk menguraikan HTML. Instal menggunakan pip:
permintaan instalasi pip pip install beautifulsoup4
Langkah 3: Tulis Perayap Dasar
Impor Perpustakaan :
impor permintaan dari bs4 impor BeautifulSoup
Ambil Halaman Web :
Di sini, kita akan mengambil konten halaman web. Ganti 'URL' dengan halaman web yang ingin Anda jelajahi.
url = 'URL' respon = permintaan.get(url) konten = respon.konten
Parsing Konten HTML :
sup = BeautifulSoup(konten, 'html.parser')
Ekstrak Informasi :
Misalnya, untuk mengekstrak semua hyperlink, Anda dapat melakukan:
untuk tautan di sup.find_all('a'): print(link.get('href'))
Langkah 4: Perluas Perayap Anda
Menangani URL Relatif :
Gunakan urljoin untuk menangani URL relatif.
dari urllib.parse impor urljoin
Hindari Merayapi Halaman yang Sama Dua Kali :
Pertahankan sekumpulan URL yang dikunjungi untuk menghindari redundansi.
Menambah Penundaan :
Perayapan yang baik mencakup penundaan antar permintaan. Gunakan waktu.tidur().
Langkah 5: Hormati Robots.txt
Pastikan perayap Anda mematuhi file robots.txt situs web, yang menunjukkan bagian situs mana yang tidak boleh dirayapi.
Langkah 6: Penanganan Kesalahan
Terapkan blok coba-kecuali untuk menangani potensi kesalahan seperti waktu tunggu koneksi habis atau akses ditolak.
Langkah 7: Mendalami Lebih Dalam
Anda dapat menyempurnakan crawler untuk menangani tugas yang lebih kompleks, seperti pengiriman formulir atau rendering JavaScript. Untuk situs web yang banyak menggunakan JavaScript, pertimbangkan untuk menggunakan Selenium.
Langkah 8: Simpan Data
Putuskan bagaimana cara menyimpan data yang telah Anda jelajahi. Pilihannya mencakup file sederhana, database, atau bahkan pengiriman data langsung ke server.
Langkah 9: Bersikaplah Etis
- Jangan membebani server secara berlebihan; tambahkan penundaan dalam permintaan Anda.
- Ikuti persyaratan layanan situs web.
- Jangan mengikis atau menyimpan data pribadi tanpa izin.
Diblokir adalah tantangan umum saat melakukan perayapan web, terutama ketika berhadapan dengan situs web yang memiliki langkah-langkah untuk mendeteksi dan memblokir akses otomatis. Berikut beberapa strategi dan pertimbangan untuk membantu Anda mengatasi masalah ini dengan Python:
Memahami Mengapa Anda Diblokir
Permintaan yang Sering: Permintaan yang cepat dan berulang dari IP yang sama dapat memicu pemblokiran.
Pola Non-Manusia: Bot sering kali menunjukkan perilaku yang berbeda dari pola penelusuran manusia, seperti mengakses halaman terlalu cepat atau dalam urutan yang dapat diprediksi.
Kesalahan Pengelolaan Header: Header HTTP yang hilang atau salah dapat membuat permintaan Anda terlihat mencurigakan.
Mengabaikan robots.txt: Tidak mematuhi arahan dalam file robots.txt situs dapat menyebabkan pemblokiran.
Strategi untuk Menghindari Pemblokiran
Hormati robots.txt : Selalu periksa dan patuhi file robots.txt situs web. Ini adalah praktik etis dan dapat mencegah pemblokiran yang tidak diperlukan.
Agen Pengguna Bergilir : Situs web dapat mengidentifikasi Anda melalui agen pengguna Anda. Dengan merotasinya, Anda mengurangi risiko ditandai sebagai bot. Gunakan perpustakaan fake_useragent untuk mengimplementasikan ini.

dari fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
Menambahkan Penundaan : Menerapkan penundaan antar permintaan dapat meniru perilaku manusia. Gunakan time.sleep() untuk menambahkan penundaan acak atau tetap.
import time time.sleep(3) # Menunggu selama 3 detik
Rotasi IP : Jika memungkinkan, gunakan layanan proxy untuk merotasi alamat IP Anda. Ada layanan gratis dan berbayar yang tersedia untuk ini.
Menggunakan Sessions : Objek request.Session dengan Python dapat membantu menjaga koneksi yang konsisten dan berbagi header, cookie, dll., di seluruh permintaan, membuat crawler Anda tampak lebih seperti sesi browser biasa.
dengan permintaan.Session() sebagai sesi: session.headers = {'Agen-Pengguna': ua.random} respon = session.get(url)
Menangani JavaScript : Beberapa situs web sangat bergantung pada JavaScript untuk memuat konten. Alat seperti Selenium atau Puppeteer dapat meniru browser sebenarnya, termasuk rendering JavaScript.
Penanganan Kesalahan : Menerapkan penanganan kesalahan yang kuat untuk mengelola dan merespons pemblokiran atau masalah lainnya dengan baik.
Pertimbangan Etis
- Selalu hormati persyaratan layanan situs web. Jika suatu situs secara eksplisit melarang web scraping, sebaiknya patuhi.
- Perhatikan dampak perayap Anda terhadap sumber daya situs web. Server yang kelebihan beban dapat menyebabkan masalah bagi pemilik situs.
Teknik Tingkat Lanjut
- Kerangka Kerja Scraping Web : Pertimbangkan untuk menggunakan kerangka kerja seperti Scrapy, yang memiliki fitur bawaan untuk menangani berbagai masalah perayapan.
- Layanan Penyelesaian CAPTCHA : Untuk situs dengan tantangan CAPTCHA, terdapat layanan yang dapat menyelesaikan CAPTCHA, meskipun penggunaannya menimbulkan masalah etika.
Praktik Perayapan Web Terbaik dengan Python
Terlibat dalam aktivitas perayapan web memerlukan keseimbangan antara efisiensi teknis dan tanggung jawab etis. Saat menggunakan Python untuk perayapan web, penting untuk mematuhi praktik terbaik yang menghormati data dan situs web asal data tersebut. Berikut beberapa pertimbangan utama dan praktik terbaik untuk perayapan web dengan Python:
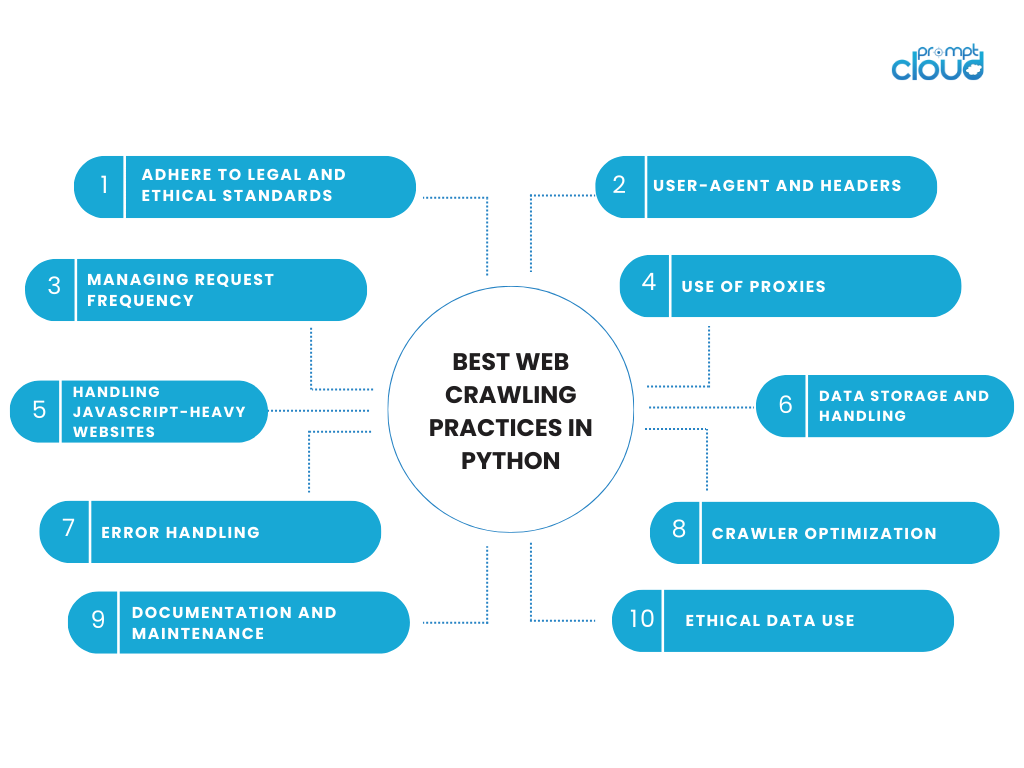
Patuhi Standar Hukum dan Etika
- Hormati robots.txt: Selalu periksa file robots.txt situs web. File ini menguraikan area situs yang tidak ingin dirayapi oleh pemilik situs web.
- Ikuti Persyaratan Layanan: Banyak situs web menyertakan klausul tentang web scraping dalam persyaratan layanannya. Mematuhi ketentuan-ketentuan ini adalah tindakan yang etis dan bijaksana secara hukum.
- Hindari Server yang Berlebihan: Buat permintaan dengan kecepatan yang wajar untuk menghindari beban berlebihan pada server situs web.
Agen Pengguna dan Header
- Identifikasi Diri Anda: Gunakan string agen pengguna yang menyertakan informasi kontak Anda atau tujuan perayapan Anda. Transparansi ini dapat membangun kepercayaan.
- Gunakan Header dengan Tepat: Header HTTP yang dikonfigurasi dengan baik dapat mengurangi kemungkinan pemblokiran. Mereka dapat menyertakan informasi seperti agen pengguna, bahasa yang diterima, dll.
Mengelola Frekuensi Permintaan
- Tambahkan Penundaan: Terapkan penundaan antar permintaan untuk meniru pola penelusuran manusia. Gunakan fungsi time.sleep() Python.
- Pembatasan Tarif: Waspadai berapa banyak permintaan yang Anda kirim ke situs web dalam jangka waktu tertentu.
Penggunaan Proxy
- Rotasi IP: Menggunakan proxy untuk merotasi alamat IP Anda dapat membantu menghindari pemblokiran berbasis IP, namun hal ini harus dilakukan secara bertanggung jawab dan etis.
Menangani Situs Web yang Banyak JavaScript
- Konten Dinamis: Untuk situs yang memuat konten secara dinamis dengan JavaScript, alat seperti Selenium atau Puppeteer (dikombinasikan dengan Pyppeteer untuk Python) dapat merender halaman seperti browser.
Penyimpanan dan Penanganan Data
- Penyimpanan Data: Simpan data yang dirayapi secara bertanggung jawab, dengan mempertimbangkan undang-undang dan peraturan privasi data.
- Minimalkan Ekstraksi Data: Hanya ekstrak data yang Anda perlukan. Hindari mengumpulkan informasi pribadi atau sensitif kecuali benar-benar diperlukan dan sah.
Penanganan Kesalahan
- Penanganan Kesalahan yang Kuat: Menerapkan penanganan kesalahan yang komprehensif untuk mengelola masalah seperti waktu habis, kesalahan server, atau konten yang gagal dimuat.
Optimasi Perayap
- Skalabilitas: Rancang perayap Anda untuk menangani peningkatan skala, baik dalam hal jumlah laman yang dirayapi maupun jumlah data yang diproses.
- Efisiensi: Optimalkan kode Anda untuk efisiensi. Kode yang efisien mengurangi beban pada sistem Anda dan server target.
Dokumentasi dan Pemeliharaan
- Simpan Dokumentasi: Dokumentasikan kode dan logika perayapan Anda untuk referensi dan pemeliharaan di masa mendatang.
- Pembaruan Reguler: Selalu perbarui kode perayapan Anda, terutama jika struktur situs web target berubah.
Penggunaan Data yang Etis
- Pemanfaatan Etis: Gunakan data yang Anda kumpulkan dengan cara yang etis, dengan menghormati privasi pengguna dan norma penggunaan data.
Kesimpulannya
Sebagai penutup eksplorasi kami dalam membuat perayap web dengan Python, kami telah mempelajari seluk-beluk pengumpulan data otomatis dan pertimbangan etis yang menyertainya. Upaya ini tidak hanya meningkatkan keterampilan teknis kami namun juga memperdalam pemahaman kami tentang penanganan data yang bertanggung jawab dalam lanskap digital yang luas.
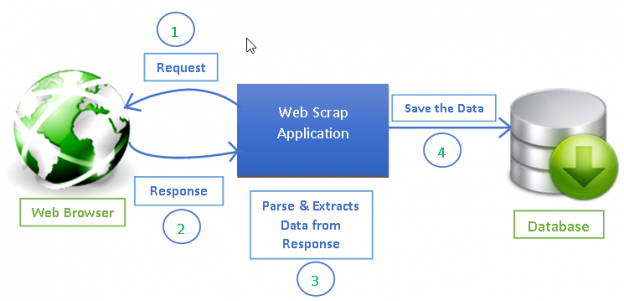
Sumber: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Namun, membuat dan memelihara web crawler bisa menjadi tugas yang rumit dan memakan waktu, terutama untuk bisnis dengan kebutuhan data spesifik dan berskala besar. Di sinilah layanan pengikisan web khusus PromptCloud berperan. Jika Anda mencari solusi yang disesuaikan, efisien, dan etis untuk kebutuhan data web Anda, PromptCloud menawarkan serangkaian layanan untuk memenuhi kebutuhan unik Anda. Mulai dari menangani situs web yang kompleks hingga menyediakan data yang bersih dan terstruktur, mereka memastikan bahwa proyek web scraping Anda tidak merepotkan dan selaras dengan tujuan bisnis Anda.
Bagi bisnis dan individu yang mungkin tidak memiliki waktu atau keahlian teknis untuk mengembangkan dan mengelola perayap web mereka sendiri, menyerahkan tugas ini kepada para ahli seperti PromptCloud dapat menjadi terobosan baru. Layanan mereka tidak hanya menghemat waktu dan sumber daya tetapi juga memastikan bahwa Anda mendapatkan data yang paling akurat dan relevan, sekaligus mematuhi standar hukum dan etika.
Tertarik untuk mempelajari lebih lanjut tentang bagaimana PromptCloud dapat memenuhi kebutuhan data spesifik Anda? Hubungi mereka di sales@promptcloud.com untuk informasi lebih lanjut dan diskusikan bagaimana solusi web scraping khusus mereka dapat membantu memajukan bisnis Anda.
Dalam dunia data web yang dinamis, memiliki mitra yang dapat diandalkan seperti PromptCloud dapat memberdayakan bisnis Anda, memberi Anda keunggulan dalam pengambilan keputusan berdasarkan data. Ingat, dalam bidang pengumpulan dan analisis data, mitra yang tepat akan membuat perbedaan.
Selamat berburu data!