
Panduan Langkah demi Langkah untuk Membangun Perayap Web
Diterbitkan: 2023-12-05Dalam permadani internet yang rumit, di mana informasi tersebar di banyak situs web, perayap web muncul sebagai pahlawan tanpa tanda jasa, yang dengan tekun bekerja untuk mengatur, mengindeks, dan membuat kekayaan data ini dapat diakses. Artikel ini memulai eksplorasi perayap web, menjelaskan cara kerja mendasarnya, membedakan antara perayapan web dan pengikisan web, dan memberikan wawasan praktis seperti panduan langkah demi langkah untuk membuat perayap web sederhana berbasis Python. Saat kami mempelajari lebih dalam, kami akan mengungkap kemampuan alat canggih seperti Scrapy dan menemukan bagaimana PromptCloud meningkatkan perayapan web ke skala industri.
Apa itu Perayap Web
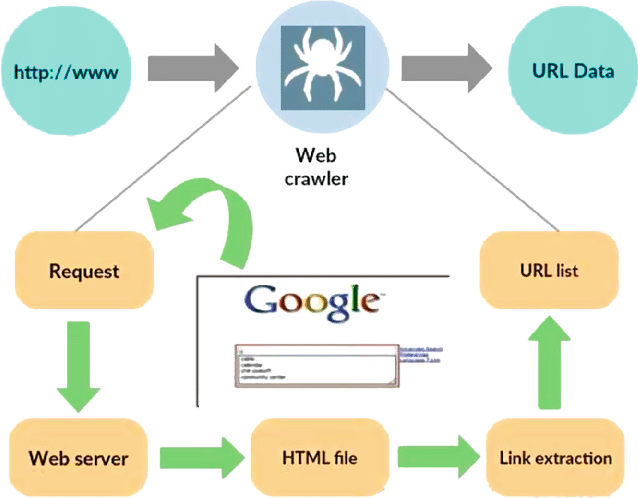
Sumber: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Perayap web, juga dikenal sebagai laba-laba atau bot, adalah program khusus yang dirancang untuk menavigasi hamparan luas World Wide Web secara sistematis dan mandiri. Fungsi utamanya adalah menjelajahi situs web, mengumpulkan data, dan mengindeks informasi untuk berbagai tujuan, seperti optimasi mesin pencari, pengindeksan konten, atau ekstraksi data.
Pada intinya, perayap web meniru tindakan pengguna manusia, tetapi dengan kecepatan yang jauh lebih cepat dan efisien. Ini memulai perjalanannya dari titik awal yang ditentukan, sering disebut sebagai URL awal, dan kemudian mengikuti hyperlink dari satu halaman web ke halaman web lainnya. Proses mengikuti tautan ini bersifat rekursif, sehingga memungkinkan perayap menjelajahi sebagian besar internet.
Saat perayap mengunjungi laman web, perayap secara sistematis mengekstrak dan menyimpan data relevan, yang dapat mencakup teks, gambar, metadata, dan lainnya. Data yang diekstraksi kemudian diorganisasikan dan diindeks, sehingga memudahkan mesin pencari untuk mengambil dan menyajikan informasi yang relevan kepada pengguna ketika ditanya.
Perayap web memainkan peran penting dalam fungsionalitas mesin pencari seperti Google, Bing, dan Yahoo. Dengan merayapi web secara terus menerus dan sistematis, mereka memastikan bahwa indeks mesin pencari selalu mutakhir, memberikan hasil pencarian yang akurat dan relevan kepada pengguna. Selain itu, perayap web digunakan dalam berbagai aplikasi lain, termasuk agregasi konten, pemantauan situs web, dan penambangan data.
Efektivitas perayap web bergantung pada kemampuannya menavigasi beragam struktur situs web, menangani konten dinamis, dan menghormati aturan yang ditetapkan oleh situs web melalui file robots.txt, yang menguraikan bagian situs mana yang dapat dirayapi. Memahami cara kerja perayap web merupakan hal mendasar untuk memahami pentingnya perayap web dalam membuat web informasi yang luas dapat diakses dan terorganisir.
Cara Kerja Perayap Web
Perayap web, juga dikenal sebagai laba-laba atau bot, beroperasi melalui proses sistematis dalam menavigasi World Wide Web untuk mengumpulkan informasi dari situs web. Berikut ini ikhtisar cara kerja perayap web:
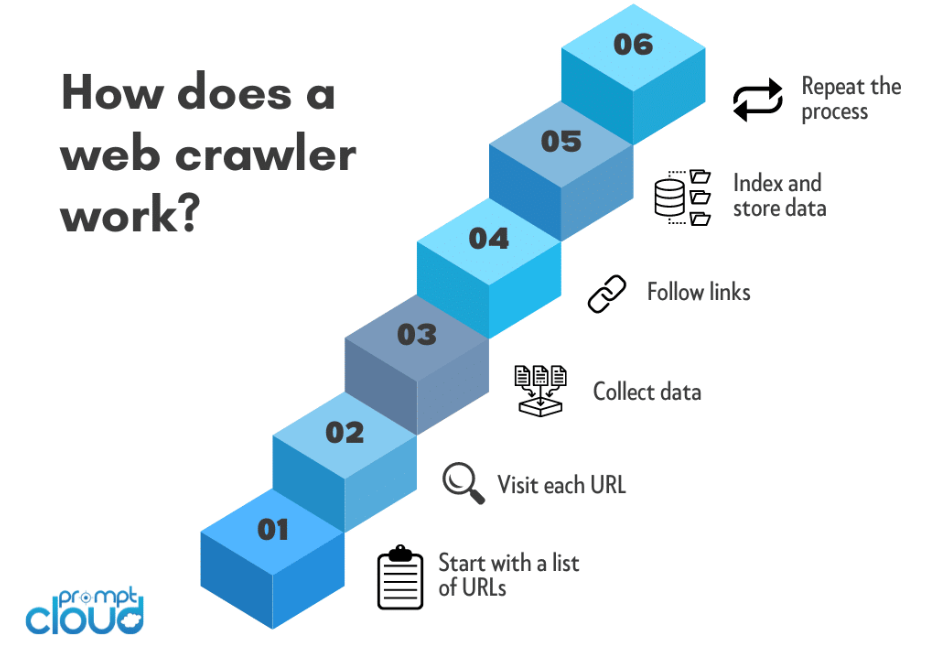
Pemilihan URL Benih:
Proses perayapan web biasanya dimulai dengan URL awal. Ini adalah laman web atau situs web awal tempat perayap memulai perjalanannya.
Permintaan HTTP:
Perayap mengirimkan permintaan HTTP ke URL benih untuk mengambil konten HTML halaman web. Permintaan ini mirip dengan permintaan yang dibuat oleh browser web saat mengakses suatu situs web.
Penguraian HTML:
Setelah konten HTML diambil, crawler menguraikannya untuk mengekstrak informasi yang relevan. Ini melibatkan pemecahan kode HTML menjadi format terstruktur yang dapat dinavigasi dan dianalisis oleh crawler.
Ekstraksi URL:
Perayap mengidentifikasi dan mengekstrak hyperlink (URL) yang ada dalam konten HTML. URL ini mewakili link ke halaman lain yang selanjutnya akan dikunjungi crawler.
Antrian dan Penjadwal:
URL yang diekstraksi ditambahkan ke antrean atau penjadwal. Antrean memastikan bahwa perayap mengunjungi URL dalam urutan tertentu, sering kali memprioritaskan URL baru atau yang belum dikunjungi terlebih dahulu.
Pengulangan:
Perayap mengikuti tautan dalam antrean, mengulangi proses pengiriman permintaan HTTP, penguraian konten HTML, dan mengekstraksi URL baru. Proses rekursif ini memungkinkan crawler menavigasi beberapa lapisan halaman web.
Ekstraksi Data:
Saat crawler melintasi web, crawler mengekstrak data yang relevan dari setiap halaman yang dikunjungi. Jenis data yang diekstraksi bergantung pada tujuan crawler dan dapat mencakup teks, gambar, metadata, atau konten spesifik lainnya.
Pengindeksan Konten:
Data yang dikumpulkan disusun dan diindeks. Pengindeksan melibatkan pembuatan database terstruktur yang memudahkan pencarian, pengambilan, dan penyajian informasi saat pengguna mengirimkan pertanyaan.
Menghormati Robots.txt:
Perayap web biasanya mematuhi aturan yang ditentukan dalam file robots.txt sebuah situs web. File ini memberikan pedoman tentang area situs mana yang dapat dirayapi dan mana yang harus dikecualikan.
Penundaan Perayapan dan Kesopanan:
Untuk menghindari server kelebihan beban dan menyebabkan gangguan, perayap sering kali menyertakan mekanisme penundaan perayapan dan kesopanan. Langkah-langkah ini memastikan bahwa crawler berinteraksi dengan situs web dengan cara yang terhormat dan tidak mengganggu.
Perayap web secara sistematis menavigasi web, mengikuti tautan, mengekstraksi data, dan membuat indeks terorganisir. Proses ini memungkinkan mesin telusur memberikan hasil yang akurat dan relevan kepada pengguna berdasarkan kueri mereka, menjadikan perayap web sebagai komponen fundamental ekosistem internet modern.

Perayapan Web vs. Pengikisan Web

Sumber: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Meskipun perayapan web dan pengikisan web sering kali digunakan secara bergantian, keduanya memiliki tujuan yang berbeda. Perayapan web melibatkan navigasi web secara sistematis untuk mengindeks dan mengumpulkan informasi, sementara pengikisan web berfokus pada penggalian data tertentu dari halaman web. Intinya, perayapan web adalah tentang menjelajahi dan memetakan web, sedangkan web scraping adalah tentang mengumpulkan informasi yang ditargetkan.
Membangun Perayap Web
Membangun perayap web sederhana dengan Python melibatkan beberapa langkah, mulai dari menyiapkan lingkungan pengembangan hingga mengkode logika perayap. Di bawah ini adalah panduan terperinci untuk membantu Anda membuat perayap web dasar menggunakan Python, memanfaatkan pustaka permintaan untuk membuat permintaan HTTP dan BeautifulSoup untuk penguraian HTML.
Langkah 1: Siapkan Lingkungan
Pastikan Anda telah menginstal Python di sistem Anda. Anda dapat mengunduhnya dari python.org. Selain itu, Anda harus menginstal perpustakaan yang diperlukan:
pip install requests beautifulsoup4
Langkah 2: Impor Perpustakaan
Buat file Python baru (misalnya, simple_crawler.py) dan impor perpustakaan yang diperlukan:
import requests from bs4 import BeautifulSoup
Langkah 3: Tentukan Fungsi Perayap
Buat fungsi yang mengambil URL sebagai masukan, mengirimkan permintaan HTTP, dan mengekstrak informasi relevan dari konten HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Langkah 4: Uji Perayap
Berikan contoh URL dan panggil fungsi simple_crawler untuk menguji crawler:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Langkah 5: Jalankan Perayap
Jalankan skrip Python di terminal atau command prompt Anda:
python simple_crawler.py
Perayap akan mengambil konten HTML dari URL yang disediakan, menguraikannya, dan mencetak judulnya. Anda dapat memperluas perayap dengan menambahkan lebih banyak fungsi untuk mengekstraksi berbagai jenis data.
Perayapan Web dengan Scrapy
Perayapan web dengan Scrapy membuka pintu ke kerangka kerja yang kuat dan fleksibel yang dirancang khusus untuk web scraping yang efisien dan terukur. Scrapy menyederhanakan kompleksitas pembuatan perayap web, menawarkan lingkungan terstruktur untuk membuat laba-laba yang dapat menavigasi situs web, mengekstrak data, dan menyimpannya secara sistematis. Berikut penjelasan lebih dekat tentang perayapan web dengan Scrapy:
Instalasi:
Sebelum memulai, pastikan Anda telah menginstal Scrapy. Anda dapat menginstalnya menggunakan:
pip install scrapy
Membuat Proyek Scrapy:
Memulai Proyek Scrapy:
Buka terminal dan navigasikan ke direktori tempat Anda ingin membuat proyek Scrapy. Jalankan perintah berikut:
scrapy startproject your_project_name
Ini menciptakan struktur proyek dasar dengan file yang diperlukan.
Definisikan Laba-laba:
Di dalam direktori proyek, navigasikan ke folder spiders dan buat file Python untuk spider Anda. Tentukan kelas laba-laba dengan membuat subkelas scrapy.Spider dan memberikan detail penting seperti nama, domain yang diizinkan, dan URL awal.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Mengekstrak Data:
Menggunakan Selector:
Scrapy menggunakan penyeleksi yang kuat untuk mengekstraksi data dari HTML. Anda dapat menentukan penyeleksi dalam metode parse laba-laba untuk menangkap elemen tertentu.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Contoh ini mengekstrak konten teks dari tag <title>.
Tautan Berikut:
Scrapy menyederhanakan proses tautan berikut. Gunakan metode ikuti untuk menavigasi ke halaman lain.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Menjalankan Laba-laba:
Jalankan laba-laba Anda menggunakan perintah berikut dari direktori proyek:
scrapy crawl your_spider
Scrapy akan memulai laba-laba, mengikuti tautan, dan menjalankan logika penguraian yang ditentukan dalam metode parse.
Perayapan web dengan Scrapy menawarkan kerangka kerja yang kuat dan dapat diperluas untuk menangani tugas-tugas pengikisan yang kompleks. Arsitektur modular dan fitur bawaannya menjadikannya pilihan utama bagi pengembang yang terlibat dalam proyek ekstraksi data web yang canggih.
Perayapan Web dalam Skala Besar
Perayapan web dalam skala besar menghadirkan tantangan unik, terutama ketika berhadapan dengan sejumlah besar data yang tersebar di berbagai situs web. PromptCloud adalah platform khusus yang dirancang untuk menyederhanakan dan mengoptimalkan proses perayapan web dalam skala besar. Berikut cara PromptCloud membantu menangani inisiatif perayapan web skala besar:
- Skalabilitas
- Ekstraksi dan Pengayaan Data
- Kualitas dan Akurasi Data
- Manajemen Infrastruktur
- Kemudahan penggunaan
- Kepatuhan dan Etika
- Pemantauan dan Pelaporan Waktu Nyata
- Dukungan dan Pemeliharaan
PromptCloud adalah solusi tangguh bagi organisasi dan individu yang ingin melakukan perayapan web dalam skala besar. Dengan mengatasi tantangan utama yang terkait dengan ekstraksi data skala besar, platform ini meningkatkan efisiensi, keandalan, dan pengelolaan inisiatif perayapan web.
Kesimpulan
Perayap web berdiri sebagai pahlawan tanpa tanda jasa dalam lanskap digital yang luas, dengan rajin menavigasi web untuk mengindeks, mengumpulkan, dan mengatur informasi. Seiring dengan meluasnya skala proyek perayapan web, PromptCloud hadir sebagai solusi, menawarkan skalabilitas, pengayaan data, dan kepatuhan etis untuk menyederhanakan inisiatif berskala besar. Hubungi kami di sales@promptcloud.com