
Memahami Arsitektur GPU untuk Optimasi Inferensi LLM
Diterbitkan: 2024-04-02Pengantar LLM dan Pentingnya Optimasi GPU
Di era kemajuan pemrosesan bahasa alami (NLP) saat ini, Model Bahasa Besar (LLM) telah muncul sebagai alat yang ampuh untuk berbagai tugas, mulai dari pembuatan teks hingga menjawab pertanyaan dan meringkas. Ini lebih dari sekedar generator token yang mungkin terjadi berikutnya. Namun, meningkatnya kompleksitas dan ukuran model ini menimbulkan tantangan yang signifikan dalam hal efisiensi dan kinerja komputasi.
Di blog ini, kami mempelajari seluk-beluk arsitektur GPU, mengeksplorasi bagaimana berbagai komponen berkontribusi pada inferensi LLM. Kami akan membahas metrik performa utama, seperti bandwidth memori dan pemanfaatan inti tensor, serta menjelaskan perbedaan antara berbagai kartu GPU, sehingga memungkinkan Anda membuat keputusan yang tepat saat memilih perangkat keras untuk tugas model bahasa besar Anda.
Dalam lanskap yang berkembang pesat di mana tugas-tugas NLP menuntut sumber daya komputasi yang terus meningkat, mengoptimalkan throughput inferensi LLM adalah hal yang sangat penting. Bergabunglah bersama kami saat kami memulai perjalanan ini untuk membuka potensi penuh LLM melalui teknik pengoptimalan GPU, dan mempelajari berbagai alat yang memungkinkan kami meningkatkan kinerja secara efektif.
Esensi Arsitektur GPU untuk LLM – Kenali Internal GPU Anda
Dengan sifat melakukan komputasi paralel yang sangat efisien, GPU menjadi perangkat pilihan untuk menjalankan semua tugas pembelajaran mendalam, sehingga penting untuk memahami gambaran umum arsitektur GPU tingkat tinggi untuk memahami hambatan mendasar yang muncul selama tahap inferensi. Kartu Nvidia lebih disukai karena CUDA (Compute Unified Device Architecture), platform komputasi paralel berpemilik dan API yang dikembangkan oleh NVIDIA, yang memungkinkan pengembang menentukan paralelisme tingkat thread dalam bahasa pemrograman C, menyediakan akses langsung ke set instruksi virtual GPU dan paralel elemen komputasi.
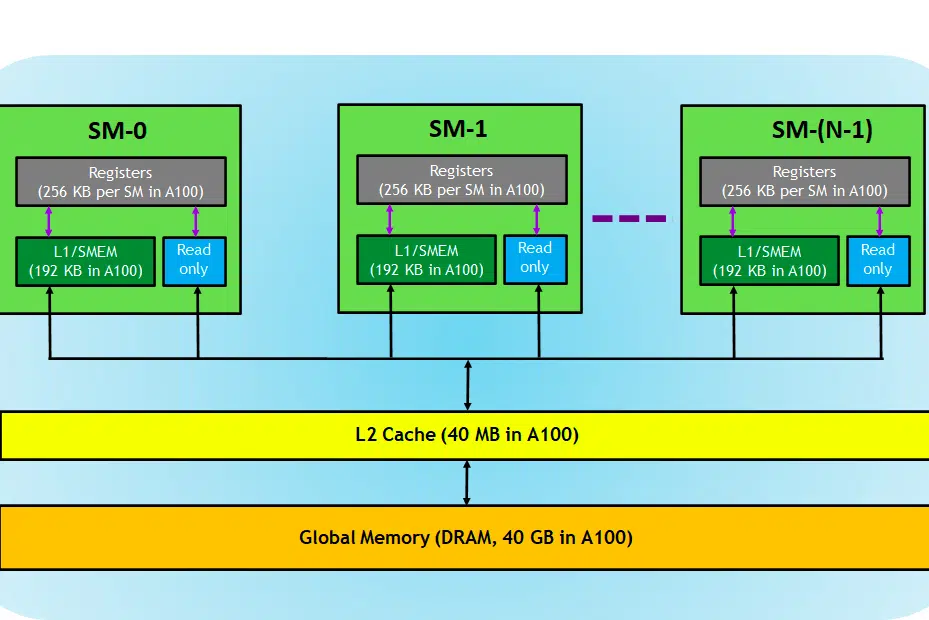
Untuk konteksnya, kami menggunakan kartu NVIDIA sebagai penjelasan karena kartu ini lebih disukai untuk tugas Pembelajaran Mendalam seperti yang telah dinyatakan dan beberapa istilah lain seperti Tensor Cores dapat diterapkan untuk itu.
Mari kita lihat kartu GPU, di sini pada gambar, kita dapat melihat tiga bagian utama dan (satu lagi bagian utama yang tersembunyi) dari perangkat GPU
- SM (Streaming Multiprosesor)
- cache L2
- Bandwidth Memori
- Memori Global (DRAM)
Sama seperti CPU-RAM Anda yang bermain bersama, RAM menjadi tempat tinggal data (yaitu memori) dan CPU untuk tugas pemrosesan (yaitu proses). Dalam GPU, Memori Global Bandwidth Tinggi (DRAM) menampung bobot model (misalnya LLAMA 7B) yang dimuat ke dalam memori dan bila diperlukan, bobot ini ditransfer ke unit pemrosesan (yaitu prosesor SM) untuk penghitungan.
Streaming Multiprosesor
Multiprosesor streaming atau SM adalah kumpulan unit eksekusi yang lebih kecil yang disebut inti CUDA (Platform komputasi paralel milik NVIDIA), bersama dengan unit fungsional tambahan yang bertanggung jawab untuk pengambilan instruksi, dekode, penjadwalan, dan pengiriman. Setiap SM beroperasi secara independen dan berisi file registernya sendiri, memori bersama, cache L1, dan unit tekstur. SM sangat paralel, memungkinkan mereka memproses ribuan thread secara bersamaan, yang penting untuk mencapai throughput tinggi dalam tugas komputasi GPU. Kinerja prosesor umumnya diukur dalam FLOPS, no. operasi mengambang yang dapat dilakukannya setiap detik.
Tugas pembelajaran mendalam sebagian besar terdiri dari operasi tensor yaitu perkalian matriks-matriks, nvidia memperkenalkan inti tensor pada GPU generasi baru, yang dirancang khusus untuk melakukan operasi tensor ini dengan cara yang sangat efisien. Seperti disebutkan, inti tensor berguna untuk tugas pembelajaran mendalam dan alih-alih inti CUDA, kita harus memeriksa inti Tensor untuk menentukan seberapa efisien GPU dapat melakukan pelatihan/inferensi LLM.
L2 Tembolok
L2 cache adalah memori bandwidth tinggi yang dibagikan antar SM yang bertujuan untuk mengoptimalkan akses memori dan efisiensi transfer data dalam sistem. Ini adalah jenis memori yang lebih kecil dan lebih cepat yang berada lebih dekat dengan unit pemrosesan (seperti Streaming Multiprosesor) dibandingkan dengan DRAM. Ini membantu meningkatkan efisiensi akses memori secara keseluruhan dengan mengurangi kebutuhan untuk mengakses DRAM yang lebih lambat untuk setiap permintaan memori.
Bandwidth Memori
Jadi, performanya bergantung pada seberapa cepat kita dapat mentransfer bobot dari memori ke prosesor dan seberapa efisien dan cepat prosesor dapat memproses perhitungan yang diberikan.
Ketika kapasitas komputasi lebih tinggi/lebih cepat dari kecepatan transfer data antara memori ke SM, SM akan kekurangan data untuk diproses dan dengan demikian komputasi kurang dimanfaatkan, situasi ini ketika bandwidth memori lebih rendah dari tingkat konsumsi dikenal sebagai fase terikat memori. . Hal ini sangat penting untuk diperhatikan karena ini merupakan hambatan yang umum terjadi dalam proses inferensi.
Sebaliknya, jika komputasi memerlukan lebih banyak waktu untuk diproses dan jika lebih banyak data yang diantrekan untuk komputasi, keadaan ini merupakan fase terikat komputasi .
Untuk memanfaatkan GPU sepenuhnya, kita harus berada dalam kondisi terikat komputasi sambil melakukan komputasi seefisien mungkin.
Memori DRAM
DRAM berfungsi sebagai memori utama dalam GPU, menyediakan kumpulan memori yang besar untuk menyimpan data dan instruksi yang diperlukan untuk komputasi. Biasanya diatur dalam hierarki, dengan beberapa bank memori dan saluran untuk memungkinkan akses berkecepatan tinggi.

Untuk tugas inferensi, DRAM GPU menentukan seberapa besar model yang dapat kita muat dan FLOPS komputasi serta bandwidth menentukan throughput yang dapat kita peroleh.
Membandingkan Kartu GPU untuk Tugas LLM
Untuk mendapatkan info mengenai jumlah tensor core, kecepatan bandwidth, dapat dilihat pada whitepaper yang dirilis oleh produsen GPU. Ini contohnya,
| RTX A6000 | RTX4090 | RTX3090 | |
| Ukuran memori | 48 GB | 24 GB | 24 GB |
| Tipe Memori | GDDR6 | GDDR6X | |
| Bandwidth | 768,0 GB/dtk | 1008 GB/detik | 936,2 GB/dtk |
| Inti CUDA / GPU | 10752 | 16384 | 10496 |
| Inti Tensor | 336 | 512 | 328 |
| L1 Tembolok | 128 KB (per SM) | 128 KB (per SM) | 128 KB (per SM) |
| FP16 Non-Tensor | 38,71 TFLOPS (1:1) | 82.6 | 35,58 TFLOPS (1:1) |
| FP32 Non-Tensor | 38,71 TFLOPS | 82.6 | 35,58 TFLOPS |
| FP64 Non-Tensor | 1.210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| TFLOPS Tensor FP16 Puncak dengan Akumulasi FP16 | 154.8/309.6 | 330.3/660.6 | 142/284 |
| TFLOPS Tensor FP16 Puncak dengan Akumulasi FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| TFLOPS Tensor BF16 Puncak dengan FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| TFLOPS Tensor TF32 Puncak | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| Puncak Tensor INT8 | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| TOPS Tensor INT4 Puncak | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| L2 Tembolok | 6 MB | 72 MB | 6 MB |
| Bus Memori | 384 sedikit | 384 sedikit | 384 sedikit |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| Jumlah SM | 84 | 128 | 82 |
| Inti RT | 84 | 128 | 82 |
Di sini kita dapat melihat FLOPS disebutkan secara khusus untuk operasi Tensor, data ini akan membantu kita membandingkan kartu GPU yang berbeda dan memilih kartu yang cocok untuk kasus penggunaan kita. Dari tabel, meskipun A6000 memiliki memori dua kali lipat dari 4090, tensore flop dan bandwidth memori 4090 jumlahnya lebih baik sehingga lebih kuat untuk inferensi model bahasa besar.
Bacaan lebih lanjut: Nvidia CUDA dalam 100 Detik
Kesimpulan
Di bidang NLP yang berkembang pesat, optimalisasi Model Bahasa Besar (LLM) untuk tugas inferensi telah menjadi area fokus yang penting. Seperti yang telah kita bahas, arsitektur GPU memainkan peran penting dalam mencapai kinerja tinggi dan efisiensi dalam tugas-tugas ini. Memahami komponen internal GPU, seperti Streaming Multiprocessors (SM), cache L2, bandwidth memori, dan DRAM, sangat penting untuk mengidentifikasi potensi hambatan dalam proses inferensi LLM.
Perbandingan antara kartu GPU NVIDIA yang berbeda—RTX A6000, RTX 4090, dan RTX 3090 – menunjukkan perbedaan yang signifikan dalam hal ukuran memori, bandwidth, jumlah CUDA dan Tensor Core, serta faktor lainnya. Perbedaan ini sangat penting untuk membuat keputusan yang tepat tentang GPU mana yang paling cocok untuk tugas LLM tertentu. Misalnya, meskipun RTX A6000 menawarkan ukuran memori yang lebih besar, RTX 4090 unggul dalam hal Tensor FLOPS dan bandwidth memori, menjadikannya pilihan yang lebih tepat untuk tugas inferensi LLM yang menuntut.
Mengoptimalkan inferensi LLM memerlukan pendekatan seimbang yang mempertimbangkan kapasitas komputasi GPU dan persyaratan spesifik tugas LLM yang ada. Memilih GPU yang tepat melibatkan pemahaman trade-off antara kapasitas memori, kekuatan pemrosesan, dan bandwidth untuk memastikan bahwa GPU dapat menangani bobot model secara efisien dan melakukan penghitungan tanpa menjadi hambatan. Seiring dengan terus berkembangnya bidang NLP, tetap mendapatkan informasi tentang teknologi GPU terbaru dan kemampuannya akan menjadi hal yang sangat penting bagi mereka yang ingin mendobrak batasan tentang apa yang mungkin dilakukan dengan Model Bahasa Besar.
Terminologi yang Digunakan
- Keluaran:
Dalam hal inferensi, throughput adalah ukuran berapa banyak permintaan/perintah yang diproses untuk jangka waktu tertentu. Throughput biasanya diukur dengan dua cara:
- Permintaan per Detik (RPS) :
- RPS mengukur jumlah permintaan inferensi yang dapat ditangani suatu model dalam satu detik. Permintaan inferensi biasanya melibatkan pembuatan respons atau prediksi berdasarkan data masukan.
- Untuk pembuatan LLM, RPS menunjukkan seberapa cepat model dapat merespons perintah atau kueri yang masuk. Nilai RPS yang lebih tinggi menunjukkan respons dan skalabilitas yang lebih baik untuk aplikasi real-time atau mendekati real-time.
- Untuk mencapai nilai RPS yang tinggi sering kali memerlukan strategi penerapan yang efisien, seperti mengelompokkan beberapa permintaan secara bersamaan untuk mengamortisasi overhead dan memaksimalkan pemanfaatan sumber daya komputasi.
- Token per Detik (TPS) :
- TPS mengukur kecepatan model dalam memproses dan menghasilkan token (kata atau subkata) selama pembuatan teks.
- Dalam konteks pembuatan LLM, TPS mencerminkan throughput model dalam hal menghasilkan teks. Hal ini menunjukkan seberapa cepat model dapat menghasilkan respons yang koheren dan bermakna.
- Nilai TPS yang lebih tinggi berarti pembuatan teks lebih cepat, sehingga model dapat memproses lebih banyak data masukan dan menghasilkan respons yang lebih lama dalam jangka waktu tertentu.
- Pencapaian nilai TPS yang tinggi sering kali melibatkan pengoptimalan arsitektur model, paralelisasi komputasi, dan memanfaatkan akselerator perangkat keras seperti GPU untuk mempercepat pembuatan token.
- Latensi:
Latensi dalam LLM mengacu pada waktu tunda antara input dan output selama inferensi. Meminimalkan latensi sangat penting untuk meningkatkan pengalaman pengguna dan memungkinkan interaksi real-time dalam aplikasi yang memanfaatkan LLM. Penting untuk mencapai keseimbangan antara throughput dan latensi berdasarkan layanan yang perlu kami sediakan. Latensi rendah diinginkan untuk kasus seperti chatbot/kopilot interaksi waktu nyata, tetapi tidak diperlukan untuk kasus pemrosesan data massal seperti pemrosesan ulang data internal.
Baca lebih lanjut tentang Teknik Tingkat Lanjut untuk Meningkatkan Throughput LLM di sini.