
Cara Mengunggah Data ke BigQuery dengan R dan Python
Diterbitkan: 2023-06-06Dunia analisis web terus meluncur menuju tanggal 1 Juli yang menentukan saat Universal Analytics berhenti memproses data dan digantikan oleh Google Analytics 4 (GA4). Salah satu perubahan utamanya adalah di GA4, Anda hanya dapat menyimpan data di platform maksimal selama 14 bulan. Ini adalah perubahan besar dari UA, tetapi sebagai gantinya, Anda dapat mendorong data GA4 ke BigQuery secara gratis, hingga batas tertentu.
BigQuery adalah sumber daya yang sangat berguna untuk penyimpanan data di luar GA4. Dengan itu menjadi lebih penting dari sebelumnya dalam beberapa bulan, ini adalah waktu yang tepat untuk mulai menggunakannya untuk semua kebutuhan penyimpanan data Anda. Seringkali, akan lebih baik untuk memanipulasi data dengan cara tertentu sebelum mengunggah. Untuk ini, kami merekomendasikan penggunaan skrip yang ditulis dalam R atau Python, terutama jika manipulasi semacam ini perlu dilakukan berulang kali. Anda juga dapat mengunggah data ke BigQuery langsung dari skrip ini, dan itulah yang akan dipandu oleh blog ini.
Mengunggah ke BigQuery dari R
R adalah bahasa yang sangat canggih untuk ilmu data dan paling mudah digunakan untuk mengupload data ke BigQuery. Langkah pertama adalah mengimpor semua pustaka yang diperlukan. Untuk tutorial ini, kita memerlukan pustaka berikut:
library(googleAuthR)
library(bigQueryR)
Jika Anda belum pernah menggunakan pustaka ini sebelumnya, jalankan install.packages(<PACKAGE NAME>) di konsol untuk memasangnya.
Selanjutnya, kita harus menangani bagian yang sering kali paling sulit dan paling membuat frustrasi saat bekerja dengan API – otorisasi. Untungnya, dengan R, ini relatif sederhana. Anda memerlukan file JSON yang berisi kredensial otorisasi. Ini dapat ditemukan di Google Cloud Console, tempat yang sama di mana BigQuery berada. Pertama, navigasikan ke Google Cloud Console, dan klik 'API dan Layanan'.
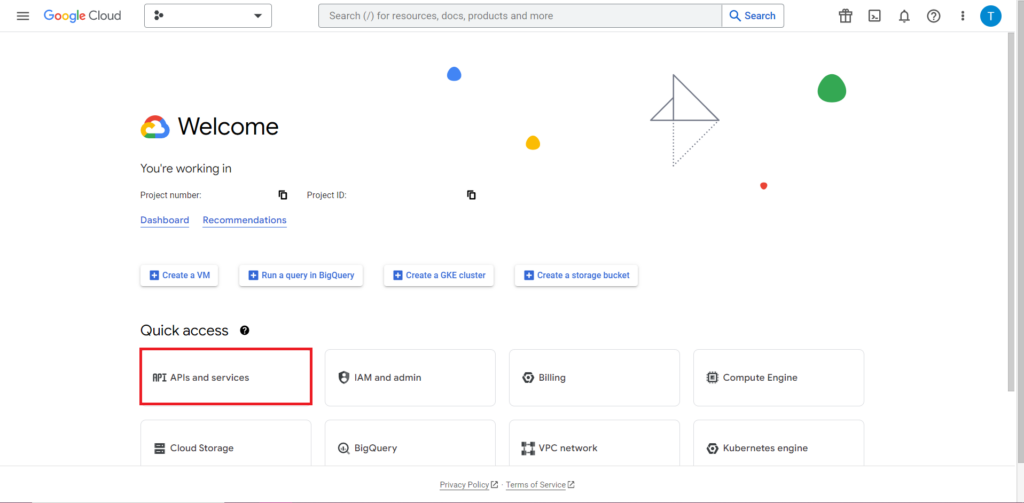
Selanjutnya, klik 'Kredensial' di sidebar.
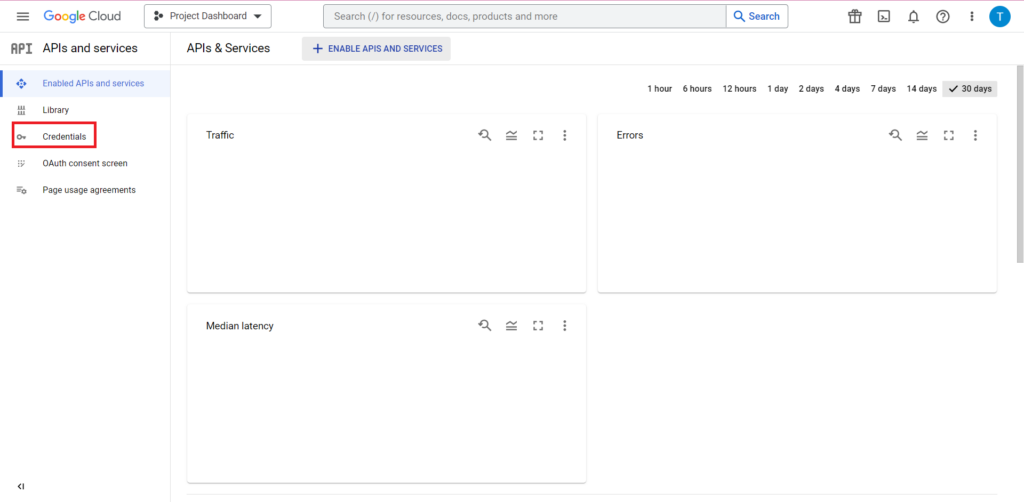
Di halaman Kredensial, Anda dapat melihat kunci API, ID Klien OAuth 2.0, dan Akun Layanan yang ada. Anda memerlukan ID Klien OAuth 2.0 untuk ini, jadi tekan tombol unduh di bagian paling akhir baris yang relevan untuk ID Anda, atau buat ID baru dengan mengklik 'Buat Kredensial' di bagian atas halaman. Pastikan ID Anda memiliki izin untuk melihat dan mengedit project BigQuery yang relevan – untuk melakukannya, buka sidebar, arahkan kursor ke 'IAM dan Admin', lalu klik 'IAM'. Di halaman ini, Anda dapat memberikan akses akun layanan Anda ke proyek yang relevan dengan menggunakan tombol 'Berikan Akses' di bagian atas halaman.
Dengan file JSON yang diperoleh dan disimpan, Anda dapat meneruskan jalur ke sana dengan fungsi gar_set_client() untuk menyetel kredensial Anda. Kode lengkap untuk otorisasi di bawah ini:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Tentunya, Anda ingin mengganti jalur di fungsi gar_set_client() dengan jalur ke file JSON Anda sendiri, dan memasukkan alamat email yang Anda gunakan untuk mengakses BigQuery ke dalam fungsi bqr_auth().
Setelah semua otorisasi disiapkan, kami memerlukan beberapa data untuk diupload ke BigQuery. Kita perlu memasukkan data ini ke dalam kerangka data. Untuk keperluan artikel ini, saya akan membuat beberapa data fiktif dengan sejumlah lokasi dan jumlah penjualan, tetapi kemungkinan besar, Anda akan membaca data nyata dari file .csv atau spreadsheet. Untuk membaca data dari file .csv, Anda cukup menggunakan fungsi read.csv() , meneruskan jalur ke file sebagai argumen:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternatifnya, jika data Anda disimpan dalam spreadsheet, metode Anda akan bervariasi tergantung di mana spreadsheet ini berada. Jika spreadsheet Anda disimpan di Google Sheets, Anda dapat membaca datanya ke dalam R menggunakan pustaka googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Seperti sebelumnya, jika Anda belum pernah menggunakan paket ini sebelumnya, Anda harus menjalankan install.packages(“googlesheets4”) di konsol sebelum menjalankan kode Anda.
Jika spreadsheet Anda ada di Excel, Anda harus menggunakan perpustakaan readxl, yang merupakan bagian dari perpustakaan rapi - sesuatu yang saya sarankan untuk digunakan. Ini berisi sejumlah besar fungsi yang membuat manipulasi data di R menjadi lebih mudah:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Dan sekali lagi, pastikan untuk menjalankan install.package(“tidyverse”) jika Anda belum pernah melakukannya!
Langkah terakhir adalah mengupload data ke BigQuery. Untuk itu, Anda memerlukan tempat di BigQuery untuk menguploadnya. Tabel Anda akan ditempatkan di dalam kumpulan data, yang akan ditempatkan di dalam proyek, dan Anda memerlukan nama ketiganya dalam format berikut:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
Dalam kasus saya, ini berarti kode saya berbunyi:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
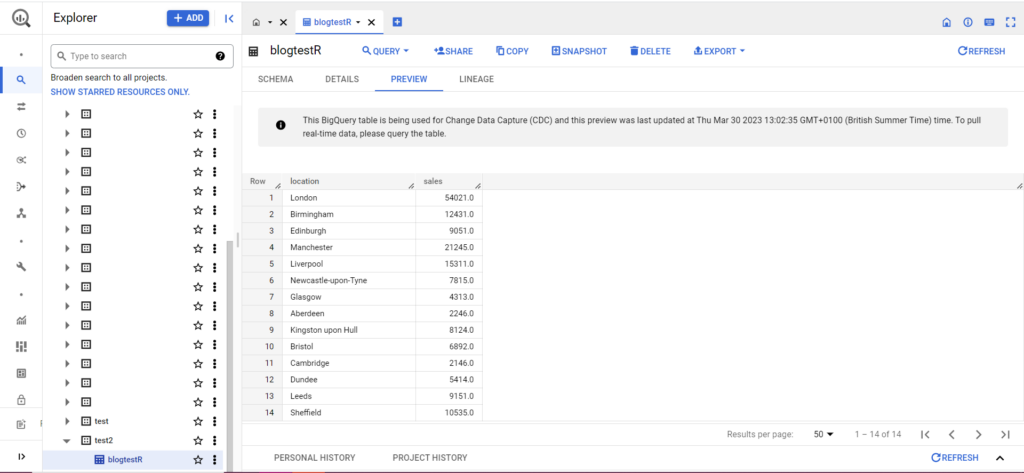
Jika tabel Anda belum ada, jangan khawatir, kode akan membuatnya untuk Anda. Jangan lupa untuk memasukkan nama proyek, kumpulan data, dan tabel Anda ke dalam kode di atas (dalam tanda kutip) dan pastikan Anda mengunggah kerangka data yang benar! Setelah ini selesai, Anda akan melihat data Anda di BigQuery, seperti di bawah ini:

Sebagai langkah terakhir, misalkan Anda memiliki data tambahan yang ingin ditambahkan ke BigQuery. Misalnya, dalam data saya di atas, katakanlah saya lupa menyertakan beberapa lokasi dari benua, dan saya ingin mengupload ke BigQuery, tetapi saya tidak ingin menimpa data yang ada. Untuk ini, bqr_upload_data memiliki parameter yang disebut writeDisposition. writeDisposition memiliki dua pengaturan, “WRITE_TRUNCATE” dan “WRITE_APPEND”. Yang pertama memberi tahu bqr_upload_data() untuk menimpa data yang ada di tabel, sedangkan yang kedua memberi tahu untuk menambahkan data baru. Jadi, untuk mengunggah data baru ini, saya akan menulis:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
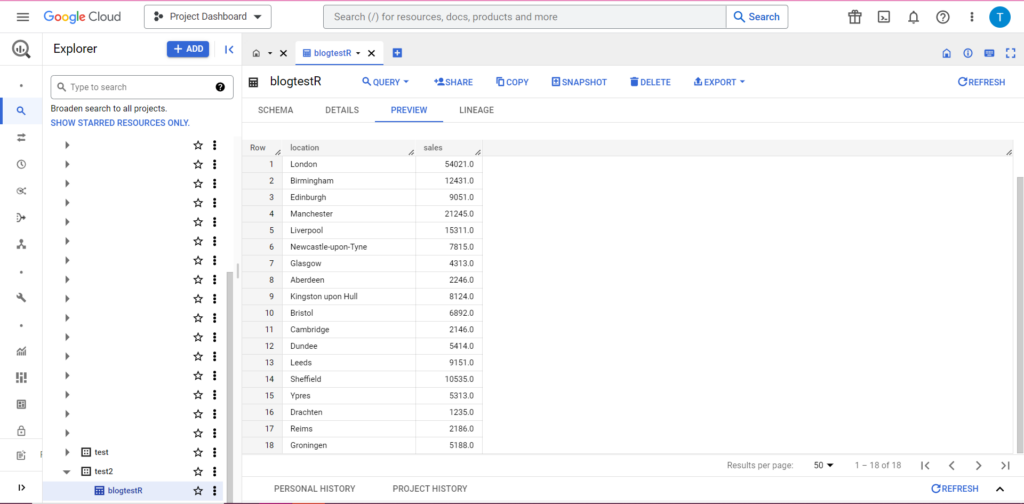
Dan tentu saja, di BigQuery kami dapat melihat data kami memiliki beberapa teman sekamar baru:
Mengupload ke BigQuery dari Python
Dalam Python, segalanya sedikit berbeda. Sekali lagi, kita perlu mengimpor beberapa paket, jadi mari kita mulai dengan ini:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Otorisasi rumit. Sekali lagi kita membutuhkan file JSON yang berisi kredensial. Seperti di atas, kita akan menavigasi ke Google Cloud Console dan mengklik 'API dan Layanan', lalu mengklik 'Kredensial' di sidebar. Kali ini, di bagian bawah halaman, akan ada bagian bernama 'Akun Layanan'.
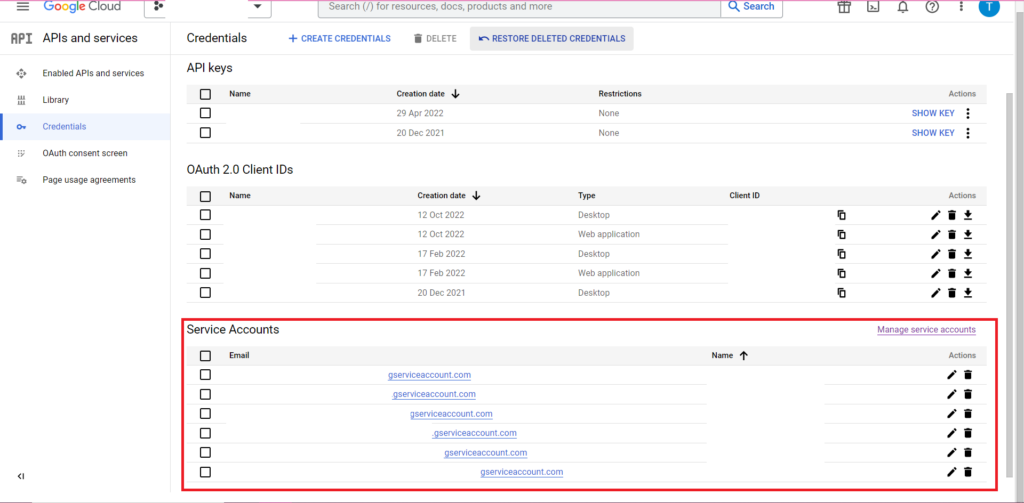
Di sana Anda dapat mengunduh kunci akun layanan Anda, atau dengan mengeklik 'Kelola Akun Layanan' Anda dapat membuat kunci baru atau akun layanan baru tempat Anda dapat mengunduh kredensialnya.
Anda kemudian ingin memastikan bahwa akun layanan Anda memiliki izin untuk mengakses dan mengedit proyek BigQuery Anda. Sekali lagi, navigasikan ke halaman IAM di bawah 'IAM & Admin' di sidebar, dan di sana Anda dapat memberikan akses akun layanan Anda ke proyek yang relevan dengan menggunakan tombol 'Berikan Akses' di bagian atas halaman.
Segera setelah Anda menyelesaikannya, Anda dapat menulis kode otorisasi:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Selanjutnya, Anda harus memasukkan data Anda ke dalam kerangka data. Dataframe termasuk dalam paket pandas, dan sangat mudah dibuat. Untuk membaca dari CSV, ikuti contoh ini:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Jelas, Anda harus mengganti jalur di atas dengan itu ke file CSV Anda sendiri. Untuk membaca dari file Excel, ikuti contoh ini:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Membaca dari Google Sheets itu rumit, dan membutuhkan putaran otorisasi lagi. Kita perlu mengimpor beberapa paket baru, dan menggunakan file kredensial JSON yang kita ambil selama tutorial R di atas. Anda dapat mengikuti kode ini untuk mengotorisasi dan membaca data Anda:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Setelah Anda memiliki data dalam kerangka data, saatnya mengupload ke BigQuery sekali lagi! Anda dapat melakukannya dengan mengikuti templat ini:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Sebagai contoh, berikut adalah kode yang baru saja saya tulis untuk mengunggah data yang saya buat sebelumnya:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Setelah ini selesai, data akan segera muncul di BigQuery!
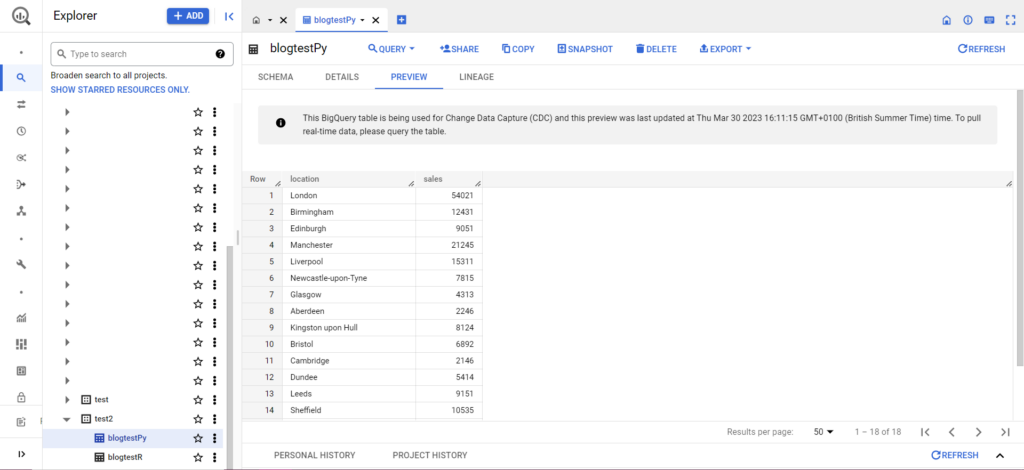
Masih banyak lagi yang dapat Anda lakukan dengan fungsi-fungsi ini setelah Anda menguasainya. Jika Anda ingin mengambil kendali lebih besar atas penyiapan analitik Anda, Semetrical siap membantu! Lihat blog kami untuk informasi lebih lanjut tentang cara memaksimalkan data Anda. Atau, untuk dukungan lebih lanjut tentang semua analitik, kunjungi Web Analytics untuk mencari tahu bagaimana kami dapat membantu Anda.