
Apa itu pelabelan data dalam pembelajaran mesin dan bagaimana cara kerjanya?
Diterbitkan: 2022-04-29Data adalah kekayaan baru untuk bisnis saat ini. Dengan teknologi seperti kecerdasan buatan yang secara progresif mengambil alih sebagian besar aktivitas kita sehari-hari, penggunaan data apa pun yang tepat telah memengaruhi masyarakat secara positif. Dengan memisahkan dan melabeli data secara efisien, algoritme ML dapat menemukan masalah dan memberikan solusi yang praktis dan relevan.
Dengan bantuan pelabelan data, kami mengajarkan berbagai teknik mesin dan memasukkan informasi dalam berbagai format agar mereka berperilaku "pintar". Ilmu di balik pelabelan data melibatkan banyak pekerjaan rumah dalam bentuk anotasi atau pelabelan kumpulan data dengan berbagai variasi informasi yang sama. Meskipun hasil akhirnya mengejutkan dan memudahkan kehidupan kita sehari-hari, kerja keras di baliknya sangat besar dan dedikasinya patut dipuji.
Apa itu pelabelan data?
Dalam pembelajaran mesin, kualitas dan jenis data input menentukan kualitas dan jenis output. Kualitas data yang digunakan untuk melatih mesin menambah keakuratan model AI Anda.
Dengan kata lain, pelabelan data adalah proses melatih mesin untuk menemukan perbedaan dan persamaan antara kumpulan data tidak terstruktur atau terstruktur dengan memberi label atau memberi anotasi pada mereka.
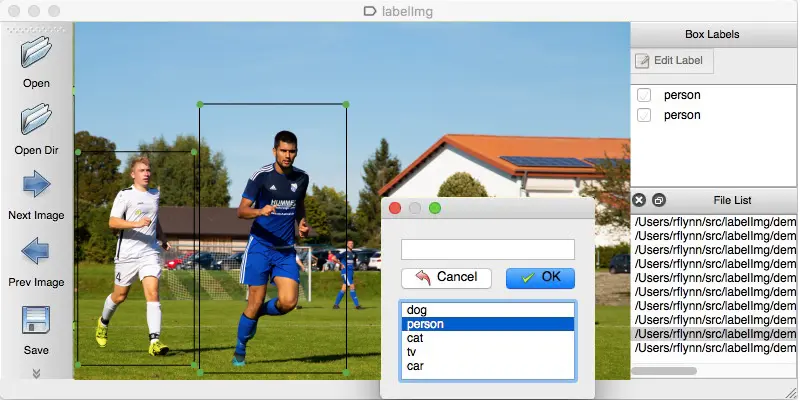
Mari kita pahami ini dengan sebuah contoh. Untuk melatih mesin bahwa lampu merah adalah tanda berhenti, Anda diharuskan menandai semua lampu merah dalam berbagai gambar agar mesin dapat memahami sinyal tersebut. Berdasarkan ini, AI membuat algoritma yang akan membaca lampu merah sebagai sinyal berhenti di setiap skenario yang diberikan. Contoh lain adalah bahwa genre musik dapat dipisahkan dengan beberapa kumpulan data di bawah label jazz, pop, rock, klasik, dan banyak lagi.
Tantangan dalam pelabelan data
Setiap perubahan/kemajuan baru dalam teknologi atau struktur membawa manfaat dan tantangannya. Hal ini tidak berbeda untuk pelabelan data. Meskipun pelabelan data dapat secara drastis mengurangi waktu untuk menskalakan bisnis , hal ini memerlukan biaya. Mari kita membahas beberapa tantangan yang dibawa oleh pelabelan data.
Biaya dalam hal waktu & usaha
Ini adalah tugas yang menantang dalam dirinya sendiri untuk mendapatkan data khusus niche dalam jumlah besar. Menambahkan tag secara manual untuk setiap item hanya menambah tugas yang sudah memakan waktu. Jika proyek ditangani sendiri, sebagian besar waktu proyek dihabiskan untuk tugas-tugas terkait data seperti pengumpulan, persiapan, dan pelabelan data.
Untuk mengelola tugas-tugas ini secara efektif, sehingga Anda mendapatkan pekerjaan dengan benar di perjalanan pertama, Anda akan memerlukan pelabel ahli dengan keahlian khusus ini. Ini juga merupakan usaha yang mahal, yang membuatnya mahal, tidak hanya dalam hal waktu tetapi juga uang.
inkonsistensi
Annotator dengan keahlian yang berbeda mungkin memiliki kriteria pelabelan yang berbeda. Akibatnya, ada kemungkinan besar penandaan yang tidak konsisten. Karena itu, ketika beberapa orang melabeli kumpulan data yang sama, tingkat akurasi data akan jauh lebih tinggi.
Keahlian domain
Untuk industri tertentu, Anda akan merasa perlu mempekerjakan pemberi label dengan keahlian domain tertentu. Misalnya, untuk membangun aplikasi ML untuk industri perawatan kesehatan , annotator tanpa keahlian domain yang relevan akan merasa sangat sulit untuk menandai elemen dengan benar.
ketidaksempurnaan
Setiap pekerjaan berulang yang dilakukan oleh manusia rentan terhadap kesalahan. Apa pun tingkat keahlian yang mungkin dimiliki oleh pemberi label manusia, penandaan manual akan selalu memiliki ruang lingkup ketidaksempurnaan. Memastikan nol kesalahan hampir tidak mungkin karena annotator harus berurusan dengan kumpulan besar data mentah untuk pelabelan.
Pendekatan untuk pelabelan data
Seperti disebutkan di atas, pelabelan data adalah tugas yang memakan waktu yang membutuhkan perhatian terhadap detail. Berdasarkan rumusan masalah, jumlah data yang akan ditandai, kompleksitas data, dan gaya, strategi yang diterapkan untuk membubuhi keterangan data akan bervariasi.
Mari kita tinjau berbagai pendekatan yang dapat dipilih perusahaan Anda berdasarkan sumber daya keuangan dan waktu yang tersedia.
Pelabelan data internal
Berdasarkan jenis industri, waktu yang tersedia untuk menyelesaikan proyek AI yang diberikan, dan ketersediaan sumber daya yang diperlukan, proses label data dapat dilakukan secara internal oleh organisasi.
Kelebihan:
- Akurasi tinggi
- Kualitas tinggi
- Pelacakan yang disederhanakan
Kontra:
- Memakan waktu/lambat
- Memerlukan sumber daya yang luas
Crowdsourcing
Kumpulan data sumber yang diberi label oleh pekerja lepas tersedia di berbagai platform crowdsourcing. Metode ini dapat digunakan untuk menganotasi data umum seperti gambar.
Contoh pelabelan data yang paling terkenal melalui crowdsourcing adalah Recaptcha. Pengguna diminta untuk mengidentifikasi jenis gambar tertentu untuk membuktikan bahwa mereka adalah manusia. Ini diverifikasi berdasarkan masukan yang diberikan oleh pengguna lain. Ini bertindak sebagai database label untuk array gambar.
Kelebihan:
- Cepat dan mudah
- Hemat biaya
Kontra:
- Tidak dapat digunakan untuk data yang membutuhkan keahlian domain
- Kualitas tidak terjamin
outsourcing
Outsourcing dapat bertindak sebagai jalan tengah antara pelabelan data internal dan crowdsourcing. Mempekerjakan organisasi pihak ketiga atau individu dengan keahlian domain dapat membantu organisasi dengan semua – proyek jangka panjang dan jangka pendek.
Kelebihan:
- Optimal untuk proyek sementara tingkat tinggi
- Perusahaan outsourcing pihak ketiga menyediakan staf yang diperiksa
- Menyediakan alat pelabelan data bawaan dan khusus sesuai kebutuhan bisnis Anda
- Bisa mendapatkan opsi dari pakar pelabelan data khusus niche
Kontra:
- Mengelola pihak ketiga bisa memakan waktu
Berbasis mesin
Salah satu bentuk terbaru dari pelabelan dan anotasi data yang banyak digunakan dan diterima oleh industri adalah anotasi berbasis mesin. Mengotomatiskan proses pelabelan data dengan bantuan perangkat lunak pelabelan data, mengurangi campur tangan manusia dan meningkatkan kecepatan pelabelan dapat dilakukan. Dengan teknik yang disebut pembelajaran aktif, data dapat diberi tag berdasarkan tag yang dapat ditambahkan ke set data pelatihan secara otomatis.
Kelebihan:
- Pemrosesan dan pelabelan data lebih cepat
- Melibatkan lebih sedikit intervensi manusia
Kontra:
- Meskipun kualitasnya lebih baik tetapi tidak setara dengan penandaan manusia
- Dalam kasus kesalahan, campur tangan manusia masih diperlukan

Bagaimana cara kerja pelabelan data?
Berdasarkan kebutuhan bisnis Anda, Anda dapat memilih pendekatan yang paling sesuai dengan kebutuhan Anda. Namun, proses pelabelan data bekerja dalam urutan berikut secara kronologis.
Pengumpulan data
Basis dari setiap proyek pembelajaran mesin adalah data. Mengumpulkan jumlah data mentah yang tepat dalam berbagai format terdiri dari langkah pertama pelabelan data. Pengumpulan data dapat dilakukan dalam dua bentuk – yang pertama dikumpulkan oleh perusahaan secara internal, dan lainnya, yang dikumpulkan dari sumber eksternal yang tersedia untuk umum.
Berada dalam bentuk mentah, data ini memerlukan pembersihan dan pemrosesan sebelum membuat label untuk kumpulan data. Data yang telah dibersihkan dan diproses ini kemudian diumpankan ke model untuk pelatihan. Semakin besar dan semakin beragam data, semakin akurat hasilnya.

Anotasi data
Setelah data dibersihkan, pakar domain menelusuri data dan menambahkan label dengan mengikuti berbagai pendekatan pelabelan data. Konteks bermakna dilampirkan pada model yang dapat digunakan sebagai kebenaran dasar Ini adalah variabel target seperti gambar yang Anda ingin model prediksi.
Kualitas asuransi
Keberhasilan pelatihan model ML sangat bergantung pada kualitas data yang harus dapat diandalkan, akurat, dan konsisten. Untuk memastikan label data yang tepat dan akurat ini, harus ada pemeriksaan QA secara teratur. Dengan menggunakan algoritme QA seperti Consensus dan uji alfa Cronbach, keakuratan anotasi ini dapat ditentukan. Pemeriksaan QA secara teratur sangat berkontribusi pada keakuratan hasil.
Pelatihan & pengujian model
Melakukan semua langkah di atas hanya masuk akal jika data diuji keakuratannya. Memasukkan kumpulan data tidak terstruktur untuk melihat apakah itu memberikan hasil yang diharapkan akan menguji prosesnya.
Kasus penggunaan berdasarkan industri untuk pelabelan data
Sekarang setelah kita mengetahui apa itu pelabelan data dan cara kerjanya, mari kita tinjau kasus penggunaan yang paling menonjol.
Visi Komputer (CV)
Ini adalah bagian dari AI yang memungkinkan mesin memperoleh interpretasi yang berarti dari input yang diberikan dalam bentuk visual dan video (gambar diam yang diekstraksi untuk penandaan).
Anotasi visi komputer dapat digunakan di berbagai industri untuk menerapkan manfaat praktis AI.
- Dalam industri otomotif, pelabelan gambar dan video untuk segmen jalan, bangunan, pejalan kaki, dan objek lain akan membantu kendaraan otonom membedakan antara entitas untuk menghindari kontak dalam kehidupan nyata.
- Dalam industri perawatan kesehatan, gejala penyakit dapat disegmentasi dalam X-ray, MRI, dan CT scan. Dengan bantuan gambar mikroskopis, sebagian besar penyakit kritis dapat didiagnosis pada tahap awal.
- Kode QR, kode batang label, dll. dapat digunakan sebagai label di industri transportasi dan logistik untuk melacak barang.
Pemrosesan bahasa alami (NLP)
Ini adalah subset yang memungkinkan mesin AI untuk menafsirkan bahasa dan statistik manusia. Berasal dari makna teks dan ucapan, algoritme dapat menganalisis berbagai aspek linguistik.
NLP semakin banyak digunakan di banyak solusi perusahaan .
- Ini biasanya digunakan di semua industri sebagai asisten email, fitur pelengkapan otomatis, pemeriksa ejaan, memisahkan email spam dan non-spam, dan banyak lagi.
- Dalam bentuk chatbots , pertanyaan dasar yang diajukan oleh pelanggan ditafsirkan dan dijawab tanpa campur tangan manusia secara real-time. Diperkirakan 70% interaksi pelanggan akan dikelola oleh chatbots dan aplikasi perpesanan seluler pada tahun 2023.
- Memahami polaritas negatif dan positif dari teks untuk menangkap sentimen pelanggan sedang dilakukan dengan pelabelan data dalam e-commerce.
Appinventiv telah berhasil membangun aplikasi media sosial untuk Vyrb yang memungkinkan pengguna mengirim dan menerima pesan audio yang dioptimalkan untuk perangkat yang dapat dikenakan Bluetooth.

Tinjauan pasar pelabelan data AI
Pelabelan data adalah industri berkembang yang lahir dari teknologi AI . Karena pelabelan data sangat bergantung pada data akurat yang diumpankan ke pembelajaran mesin, pelabelan ini pasti akan tumbuh dalam beberapa tahun ke depan.
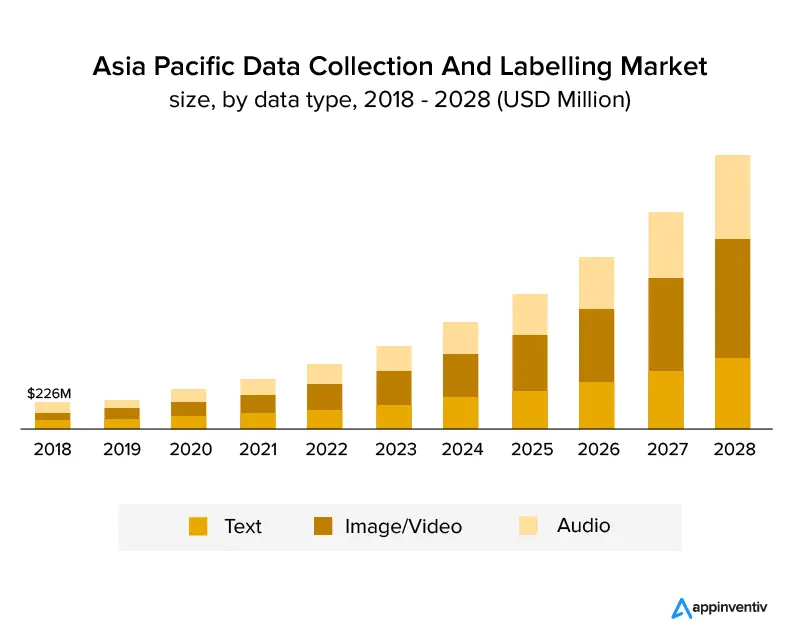
Grafik di bawah ini dengan jelas menunjukkan bahwa industri telah tumbuh dan akan terus tumbuh di tahun-tahun mendatang. Diperkirakan akan tumbuh pada pertumbuhan tahunan gabungan sebesar 25,6% dan mencapai ukuran pasar sebesar USD 8,22 miliar pada tahun 2028. Grafik di bawah ini menunjukkan pertumbuhan menurut tipe data.
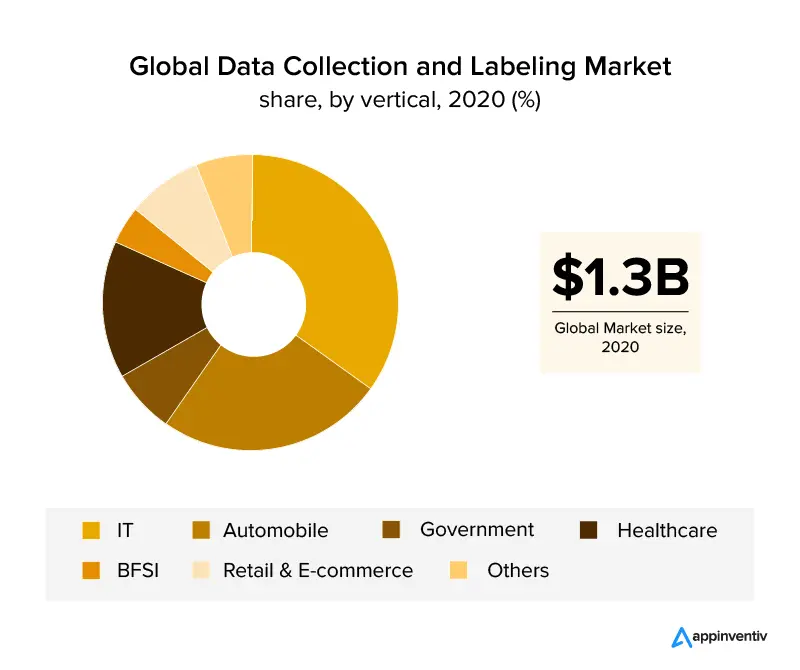
Tinjauan vertikal bisnis yang telah mengeksploitasi pelabelan data adalah sektor TI dan otomotif, yang mencakup lebih dari 30% pangsa pendapatan global. Dengan pertumbuhan industri perawatan kesehatan , diharapkan pelabelan data akan berkembang pesat karena persyaratan data yang akurat untuk aplikasi berbasis AI yang efisien di sektor ini. Dengan bantuan pelabelan gambar, industri ritel dan e-niaga juga telah mengamankan pangsa pasar yang signifikan dalam industri pelabelan data.
Memberi label data dengan Appinventiv
Secara strategis, perusahaan telah mengalihdayakan layanan pengumpulan dan pelabelan data untuk membangun model pembelajaran mesin yang kuat.
Appinventiv adalah perusahaan pengembangan AI dan ML yang telah membantu organisasi membuka peluang dengan solusi berbasis AI selama bertahun-tahun sekarang . Dengan pengalaman hampir satu dekade dalam mentransformasi bisnis, kami telah berhasil menyelesaikan banyak proyek AI yang kompleks untuk berbagai industri.
Misalnya, Appinventiv telah berhasil mengotomatisasi proses perbankan untuk bank terkemuka di Eropa. Proses otomatisasi membantu bank dalam meningkatkan akurasi sebesar 50% dan tingkat layanan ATM sebesar 92%.
Contoh lain di mana Appinventiv membantu YouCOMM membangun solusi revolusioner untuk mengubah komunikasi pasien di rumah sakit dengan menyediakan akses real-time ke bantuan medis. Dengan sistem pesan pasien yang dapat disesuaikan, pasien dapat dengan mudah memberi tahu staf tentang kebutuhan mereka melalui perintah suara, dan penggunaan gerakan kepala.
Dengan keahlian kami dan tim yang berfokus pada pelanggan, kami menyediakan layanan pelabelan data yang akan membantu Anda mengatasi tantangan dalam menyediakan layanan pelabelan data holistik berdasarkan kebutuhan dan persyaratan khusus Anda.
Dengan memanfaatkan beragam alat yang diperlukan untuk penandaan dan anotasi data, Appinventiv dapat meningkatkan proses pelatihan data Anda untuk menyederhanakan model yang kompleks. Hal ini memungkinkan kami untuk mengungguli dalam hal akurasi segmentasi, klasifikasi, dan selanjutnya pelabelan data yang akan cepat dan mudah.
Membungkus!
“Kekuatan kecerdasan buatan sangat luar biasa, itu akan mengubah masyarakat dalam beberapa hal yang sangat dalam.” - Bill Gates
Kecerdasan buatan memiliki potensi untuk membuat hidup manusia lebih mudah sehingga berbuat baik kepada masyarakat. Kemampuannya untuk menyortir sejumlah besar data menjadi instruksi yang bermakna dengan bantuan pelabelan data telah membantu industri untuk maju dan berkembang dengan pesat.
FAQ
T. Apa praktik terbaik untuk menyempurnakan pelabelan data?
A. Berdasarkan pendekatan yang Anda ambil untuk pelabelan data, ada beberapa praktik terbaik yang dapat Anda ikuti:
- Pastikan bahwa data yang dikumpulkan memadai, dibersihkan dengan benar, dan diproses.
- Berdasarkan industri, tetapkan pekerjaan hanya untuk pelabel data pakar domain.
- Pastikan pendekatan yang seragam diikuti oleh tim dengan memberi mereka kriteria teknik anotasi yang harus diikuti.
- Ikuti proses pembuat-pemeriksa dengan menetapkan beberapa annotator untuk pelabelan silang.
T. Apa manfaat pelabelan data?
A. Pelabelan data membantu memberikan kejelasan yang lebih baik tentang konteks, kualitas, dan kegunaan untuk membuat prediksi data yang tepat. Ini, pada gilirannya, membantu dalam meningkatkan kegunaan data variabel dalam model.
T. Apa saja berbagai elemen yang perlu dipertimbangkan saat memilih perusahaan pelabelan data?
A. Ada lima parameter yang perlu dipertimbangkan saat memilih layanan label data untuk pembelajaran mesin.
- Skalabilitas proses pelabelan data
- Biaya layanan pelabelan data
- Keamanan data
- Platform pelabelan data