
Apa itu Robots.txt dalam SEO: Cara Membuat dan Mengoptimalkannya
Diterbitkan: 2022-04-22Topik hari ini tidak terkait langsung dengan monetisasi lalu lintas. Tetapi robots.txt dapat memengaruhi SEO situs web Anda dan, pada akhirnya, jumlah lalu lintas yang diterimanya. Banyak admin web telah merusak peringkat situs web mereka karena entri robots.txt yang gagal. Panduan ini akan membantu Anda menghindari semua jebakan itu. Pastikan untuk membaca sampai akhir!
- Apa itu file robots.txt?
- Bagaimana tampilan file robots.txt?
- Bagaimana menemukan file robots.txt Anda
- Bagaimana cara kerja file Robots.txt?
- Sintaks robots.txt
- Arahan yang didukung
- Agen pengguna*
- Mengizinkan
- Melarang
- peta situs
- Arahan yang tidak didukung
- Penundaan perayapan
- indeks no
- Tidak mengikuti
- Apakah Anda memerlukan file robots.txt?
- Membuat file robots.txt
- File robots.txt: praktik terbaik SEO
- Gunakan baris baru untuk setiap arahan
- Gunakan wildcard untuk menyederhanakan instruksi
- Gunakan tanda dolar "$" untuk menentukan akhir URL
- Gunakan setiap agen pengguna hanya sekali
- Gunakan instruksi khusus untuk menghindari kesalahan yang tidak disengaja
- Masukkan komentar di file robots.txt dengan hash
- Gunakan file robots.txt yang berbeda untuk setiap subdomain
- Jangan blokir konten bagus
- Jangan terlalu sering menggunakan penundaan perayapan
- Perhatikan sensitivitas kasus
- Praktik terbaik lainnya:
- Menggunakan robots.txt untuk mencegah pengindeksan konten
- Menggunakan robots.txt untuk melindungi konten pribadi
- Menggunakan robots.txt untuk menyembunyikan konten duplikat berbahaya
- Semua akses untuk semua bot
- Tidak ada akses untuk semua bot
- Blokir satu subdirektori untuk semua bot
- Blokir satu subdirektori untuk semua bot (dengan satu file diperbolehkan)
- Blokir satu file untuk semua bot
- Blokir satu jenis file (PDF) untuk semua bot
- Blokir semua URL berparameter hanya untuk Googlebot
- Cara menguji file robots.txt Anda untuk kesalahan
- URL yang dikirimkan diblokir oleh robots.txt
- Diblokir oleh robots.txt
- Diindeks, meskipun diblokir oleh robots.txt
- Robots.txt vs robot meta vs robot x
- Bacaan lebih lanjut
- Membungkus
Apa itu file robots.txt?
Robots.txt, atau protokol pengecualian robot, adalah seperangkat standar web yang mengontrol cara robot mesin telusur merayapi setiap laman web, hingga markup skema pada laman tersebut. Ini adalah file teks standar yang bahkan dapat mencegah perayap web mendapatkan akses ke seluruh situs web Anda atau sebagiannya.
Sambil menyesuaikan SEO dan memecahkan masalah teknis, Anda bisa mulai mendapatkan penghasilan pasif dari iklan. Satu baris kode di situs web Anda mengembalikan pembayaran reguler!
Ke IsiBagaimana tampilan file robots.txt?
Sintaksnya sederhana: Anda memberikan aturan bot dengan menentukan agen pengguna dan arahannya. File memiliki format dasar berikut:
Peta Situs: [URL lokasi peta situs]
Agen-pengguna: [pengidentifikasi bot]
[petunjuk 1]
[petunjuk 2]
[pengarahan …]
Agen-pengguna: [pengidentifikasi bot lain]
[petunjuk 1]
[petunjuk 2]
[pengarahan …]
Bagaimana menemukan file robots.txt Anda
Jika situs web Anda sudah memiliki file robot.txt, Anda dapat menemukannya dengan membuka URL ini: https://namadomainanda.com/robots.txt di browser Anda. Sebagai contoh, inilah file kami
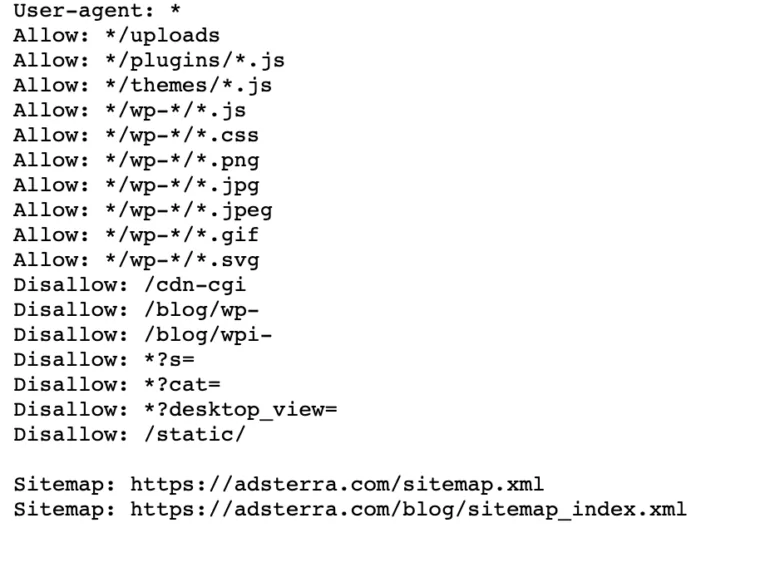
Bagaimana cara kerja file Robots.txt?
File robots.txt adalah file teks biasa yang tidak berisi kode markup HTML (maka ekstensi .txt). File ini, seperti semua file lain di situs web, disimpan di server web. Pengguna tidak mungkin mengunjungi halaman ini karena tidak tertaut ke halaman Anda, tetapi sebagian besar bot perayap web mencarinya sebelum merayapi seluruh situs web.
File robots.txt dapat memberikan instruksi bot tetapi tidak dapat menjalankan instruksi tersebut. Bot yang baik, seperti perayap web atau bot umpan berita, akan memeriksa file dan mengikuti petunjuk sebelum mengunjungi halaman domain mana pun. Tetapi bot jahat akan mengabaikan atau memproses file untuk menemukan halaman web terlarang.
Dalam situasi ketika file robots.txt berisi perintah yang bertentangan, bot akan menggunakan rangkaian instruksi yang paling spesifik.
Ke IsiSintaks robots.txt
File robots.txt terdiri dari beberapa bagian 'directives', masing-masing dimulai dengan user-agent. Agen pengguna menentukan bot perayapan yang digunakan untuk berkomunikasi dengan kode. Anda dapat menangani semua mesin telusur sekaligus atau mengelola mesin telusur individual.
Setiap kali bot merayapi situs web, ia bertindak pada bagian situs yang memanggilnya.
Agen pengguna: *
Larang: /
Agen-pengguna: Googlebot
Melarang:
Agen-pengguna: Bingbot
Larang: /tidak-untuk-bing/
Arahan yang didukung
Arahan adalah panduan yang Anda inginkan agar diikuti oleh agen pengguna yang Anda nyatakan. Google saat ini mendukung arahan berikut.
Agen pengguna*
Ketika sebuah program terhubung ke server web (robot atau browser web biasa), ia mengirimkan header HTTP yang disebut "agen pengguna" yang berisi informasi dasar tentang identitasnya. Setiap mesin pencari memiliki agen pengguna. Robot Google dikenal sebagai Googlebot, Yahoo — sebagai Slurp, dan Bing — sebagai BingBot. Agen pengguna memulai urutan arahan, yang dapat diterapkan ke agen pengguna tertentu atau semua agen pengguna.
Mengizinkan
Perintah izinkan memberi tahu mesin pencari untuk merayapi halaman atau subdirektori, bahkan direktori terbatas. Misalnya, jika Anda ingin mesin telusur tidak dapat mengakses semua entri blog Anda kecuali satu, file robots.txt Anda mungkin terlihat seperti ini:
Agen pengguna: *
Larang: /blog
Izinkan: /blog/allowed-posting
Namun, mesin telusur dapat mengakses /blog/allowed-post tetapi tidak dapat mengakses:
/blog/postingan lain
/blog/yet-another-post
/blog/download-me.pd
Melarang
Arahan disallow (yang ditambahkan ke file robots.txt situs web) memberi tahu mesin telusur untuk tidak merayapi laman tertentu. Dalam kebanyakan kasus, ini juga akan mencegah halaman muncul di hasil pencarian.
Anda dapat menggunakan arahan ini untuk menginstruksikan mesin pencari agar tidak merayapi file dan halaman di folder tertentu yang Anda sembunyikan dari masyarakat umum. Misalnya, konten yang masih Anda kerjakan tetapi salah dipublikasikan. File robots.txt Anda mungkin terlihat seperti ini jika Anda ingin mencegah semua mesin pencari mengakses blog Anda:
Agen pengguna: *
Larang: /blog
Ini berarti semua subdirektori dari direktori /blog juga tidak akan dirayapi. Ini juga akan memblokir Google dari mengakses URL yang berisi /blog.
Ke Isipeta situs
Peta Situs adalah daftar halaman yang Anda inginkan untuk dirayapi dan diindeks oleh mesin telusur. Jika Anda menggunakan arahan peta situs, mesin pencari akan mengetahui lokasi peta situs XML Anda. Pilihan terbaik adalah mengirimkannya ke alat webmaster mesin pencari karena masing-masing dapat memberikan informasi berharga tentang situs web Anda kepada pengunjung.
Penting untuk dicatat bahwa pengulangan arahan peta situs untuk setiap agen pengguna tidak diperlukan, dan itu tidak berlaku untuk satu agen pencarian. Tambahkan arahan peta situs Anda di awal atau akhir file robots.txt Anda.
Contoh arahan peta situs dalam file:
Peta Situs: https://www.domain.com/sitemap.xml
Agen-pengguna: Googlebot
Larang: /blog/
Izinkan: /blog/post-title/
Agen-pengguna: Bingbot
Larang: /services/
Ke IsiArahan yang tidak didukung
Berikut ini adalah arahan yang tidak lagi didukung oleh Google — beberapa di antaranya secara teknis tidak pernah didukung.
Penundaan perayapan
Yahoo, Bing, dan Yandex dengan cepat merespons pengindeksan situs web dan bereaksi terhadap arahan penundaan perayapan, yang membuat mereka tetap terkendali untuk sementara waktu.
Terapkan baris ini ke blok Anda:
Agen-pengguna: Bingbot
Penundaan perayapan: 10
Artinya mesin pencari dapat menunggu selama sepuluh detik sebelum merayapi situs web atau sepuluh detik sebelum mengakses kembali situs web setelah merayapi, yang merupakan hal yang sama tetapi sedikit berbeda tergantung pada agen pengguna yang digunakan.
indeks no
Tag meta noindex adalah cara yang bagus untuk mencegah mesin pencari mengindeks salah satu halaman Anda. Tag memungkinkan bot untuk mengakses halaman web, tetapi juga memberi tahu robot untuk tidak mengindeksnya.
- Header Respons HTTP dengan tag noindex. Anda dapat menerapkan tag ini dengan dua cara: header respons HTTP dengan X-Robots-Tag atau tag <meta> yang ditempatkan di bagian <head>. Beginilah tampilan tag <meta> Anda:
<meta name="robots" content="noindex">
- 404 & 410 kode status HTTP. Kode status 404 dan 410 menunjukkan bahwa halaman tidak lagi tersedia. Setelah merayapi dan memproses halaman 404/410, mereka secara otomatis menghapusnya dari indeks Google. Untuk mengurangi risiko halaman kesalahan 404 dan 410, jelajahi situs web Anda secara teratur dan gunakan pengalihan 301 untuk mengarahkan lalu lintas ke halaman yang ada jika diperlukan.
Tidak mengikuti
Nofollow mengarahkan mesin pencari untuk tidak mengikuti tautan pada halaman dan file di bawah jalur tertentu. Sejak 1 Maret 2020, Google tidak lagi menganggap atribut nofollow sebagai arahan. Sebaliknya, mereka akan menjadi petunjuk, seperti tag kanonik. Jika Anda menginginkan atribut “nofollow” untuk semua tautan di halaman, gunakan tag meta robot, header x-robots, atau atribut tautan rel= “nofollow” .
Sebelumnya Anda dapat menggunakan arahan berikut untuk mencegah Google mengikuti semua tautan di blog Anda:
Agen-pengguna: Googlebot
Tidak mengikuti: /blog/
Apakah Anda memerlukan file robots.txt?
Banyak situs web yang tidak terlalu rumit tidak memerlukannya. Meskipun Google biasanya tidak mengindeks halaman web yang diblokir oleh robots.txt, tidak ada jaminan bahwa halaman ini tidak muncul di hasil pencarian. Memiliki file ini memberi Anda lebih banyak kontrol dan keamanan konten di situs web Anda di atas mesin telusur.
File robots juga membantu Anda mencapai hal berikut:
- Cegah konten duplikat agar tidak dirayapi.
- Pertahankan privasi untuk bagian situs web yang berbeda.
- Batasi perayapan hasil penelusuran internal.
- Mencegah kelebihan server.
- Cegah pemborosan "anggaran perayapan".
- Jauhkan gambar, video, dan file sumber daya dari hasil penelusuran Google.
Langkah-langkah ini pada akhirnya memengaruhi taktik SEO Anda. Misalnya, duplikat konten membingungkan mesin telusur dan memaksa mereka untuk memilih mana dari dua halaman yang akan mendapat peringkat pertama. Terlepas dari siapa yang membuat konten, Google tidak boleh memilih halaman asli untuk hasil pencarian teratas.

Jika Google mendeteksi konten duplikat yang dimaksudkan untuk menipu pengguna atau memanipulasi peringkat, mereka akan menyesuaikan pengindeksan dan peringkat situs web Anda. Akibatnya, peringkat situs Anda mungkin terganggu atau dihapus seluruhnya dari indeks Google, menghilang dari hasil penelusuran.
Menjaga privasi untuk bagian situs web yang berbeda juga meningkatkan keamanan situs web Anda dan melindunginya dari peretas. Dalam jangka panjang, langkah-langkah ini akan membuat situs web Anda lebih aman, dapat dipercaya, dan menguntungkan.
Apakah Anda pemilik situs web yang ingin mendapat untung dari lalu lintas? Dengan Adsterra, Anda akan mendapatkan penghasilan pasif dari situs web mana pun!
Ke IsiMembuat file robots.txt
Anda memerlukan editor teks seperti Notepad.
- Buat lembar baru, simpan halaman kosong sebagai 'robots.txt,' dan mulailah mengetik arahan di dokumen .txt kosong.
- Login ke cPanel Anda, arahkan ke direktori root situs, cari folder public_html .
- Seret file Anda ke folder ini, lalu periksa kembali apakah izin file telah disetel dengan benar.
Anda dapat menulis, membaca, dan mengedit file sebagai pemiliknya, tetapi pihak ketiga tidak diizinkan. Kode izin "0644" akan muncul di file. Jika tidak, klik kanan file dan pilih "izin file."
File robots.txt: praktik terbaik SEO
Gunakan baris baru untuk setiap arahan
Anda perlu mendeklarasikan setiap arahan pada baris terpisah. Jika tidak, mesin pencari akan bingung.
Agen pengguna: *
Larang: /direktori/
Larang: /another-directory/
Gunakan wildcard untuk menyederhanakan instruksi
Anda dapat menggunakan karakter pengganti (*) untuk semua agen pengguna dan mencocokkan pola URL saat mendeklarasikan arahan. Wildcard berfungsi dengan baik untuk URL yang memiliki pola seragam. Misalnya, Anda mungkin ingin mencegah semua halaman filter dengan tanda tanya (?) di URL-nya agar tidak dirayapi.
Agen pengguna: *
Larang: /*?
Gunakan tanda dolar "$" untuk menentukan akhir URL
Mesin telusur tidak dapat mengakses URL yang diakhiri dengan ekstensi seperti .pdf. Itu berarti mereka tidak akan dapat mengakses /file.pdf, tetapi mereka akan dapat mengakses /file.pdf?id=68937586, yang tidak diakhiri dengan “.pdf.” Misalnya, jika Anda ingin mencegah mesin telusur mengakses semua file PDF di situs web Anda, file robots.txt Anda mungkin terlihat seperti ini:
Agen pengguna: *
Larang: /*.pdf$
Gunakan setiap agen pengguna hanya sekali
Di Google, tidak masalah jika Anda menggunakan agen pengguna yang sama lebih dari sekali. Itu hanya akan mengkompilasi semua aturan dari berbagai deklarasi menjadi satu arahan dan mengikutinya. Namun, mendeklarasikan setiap agen pengguna hanya sekali masuk akal karena tidak terlalu membingungkan.
Menjaga arahan Anda rapi dan sederhana mengurangi risiko kesalahan kritis. Misalnya, jika file robots.txt Anda berisi agen-pengguna dan arahan berikut.
Agen-pengguna: Googlebot
Larang: /a/
Agen-pengguna: Googlebot
Larang: /b/
Gunakan instruksi khusus untuk menghindari kesalahan yang tidak disengaja
Saat mengatur arahan, gagal memberikan instruksi khusus dapat membuat kesalahan yang dapat membahayakan SEO Anda. Asumsikan Anda memiliki situs multibahasa dan sedang mengerjakan versi Jerman untuk subdirektori /de/.
Anda tidak ingin mesin pencari dapat mengaksesnya karena belum siap. File robots.txt berikut akan mencegah mesin pencari mengindeks subfolder itu dan isinya:
Agen pengguna: *
Larang: /de
Namun, ini akan membatasi mesin pencari untuk merayapi halaman atau file apa pun yang dimulai dengan /de. Dalam hal ini, menambahkan garis miring adalah solusi sederhana.
Agen pengguna: *
Larang: /de/
Ke IsiMasukkan komentar di file robots.txt dengan hash
Komentar membantu pengembang dan bahkan mungkin Anda untuk memahami file robots.txt Anda. Mulai baris dengan hash (#) untuk menyertakan komentar. Crawler mengabaikan baris yang dimulai dengan hash.
# Ini menginstruksikan bot Bing untuk tidak merayapi situs kita.
Agen-pengguna: Bingbot
Larang: /
Gunakan file robots.txt yang berbeda untuk setiap subdomain
Robots.txt hanya memengaruhi perayapan di domain inangnya. Anda memerlukan file lain untuk membatasi perayapan pada subdomain yang berbeda. Misalnya, jika Anda menghosting situs web utama Anda di example.com dan blog Anda di blog.example.com, Anda memerlukan dua file robots.txt. Tempatkan satu di direktori root domain utama, sedangkan file lainnya harus di direktori root blog.
Jangan blokir konten bagus
Jangan gunakan file robots.txt atau tag noindex untuk memblokir konten berkualitas apa pun yang ingin Anda publikasikan untuk menghindari efek negatif pada hasil SEO. Periksa tag noindex dan aturan larang secara menyeluruh di halaman Anda.
Jangan terlalu sering menggunakan penundaan perayapan
Kami telah menjelaskan penundaan perayapan, tetapi Anda tidak boleh sering menggunakannya karena membatasi bot untuk merayapi semua halaman. Ini mungkin berhasil untuk beberapa situs web, tetapi Anda mungkin akan merusak peringkat dan lalu lintas Anda jika Anda memiliki situs web yang besar.
Perhatikan sensitivitas huruf
File robots.txt peka huruf besar/kecil, jadi Anda perlu memastikan bahwa Anda membuat file robots dalam format yang benar. File robot harus diberi nama 'robots.txt' dengan huruf kecil semua. Lain, itu tidak akan berhasil.
Praktik terbaik lainnya:
- Pastikan Anda tidak memblokir konten atau bagian situs web Anda dari perayapan.
- Jangan gunakan robots.txt untuk menyimpan data sensitif (informasi pengguna pribadi) dari hasil SERP. Gunakan metode yang berbeda, seperti enkripsi data atau arahan meta noindex , untuk membatasi akses jika halaman lain tertaut langsung ke halaman pribadi.
- Beberapa mesin pencari memiliki lebih dari satu agen pengguna. Google, misalnya, menggunakan Googlebot untuk pencarian organik dan Googlebot-Image untuk gambar. Menentukan arahan untuk beberapa perayap mesin telusur tidak diperlukan karena sebagian besar agen pengguna dari mesin telusur yang sama mengikuti aturan yang sama.
- Mesin pencari menyimpan konten robots.txt tetapi memperbaruinya setiap hari. Jika Anda mengubah file dan ingin memperbaruinya lebih cepat, Anda dapat mengirimkan URL file ke Google.
Menggunakan robots.txt untuk mencegah pengindeksan konten
Menonaktifkan halaman adalah cara paling efektif untuk mencegah bot merayapinya secara langsung. Namun, itu tidak akan berfungsi dalam situasi berikut:
- Jika sumber lain memiliki tautan ke halaman tersebut, bot akan tetap merayapi dan mengindeksnya.
- Bot tidak sah akan terus merayapi dan mengindeks konten.
Menggunakan robots.txt untuk melindungi konten pribadi
Beberapa konten pribadi, seperti PDF atau halaman terima kasih, masih dapat diindeks meskipun Anda memblokir bot. Menempatkan semua halaman eksklusif Anda di belakang login adalah salah satu cara terbaik untuk memperkuat arahan disallow. Konten Anda akan tetap tersedia, tetapi pengunjung Anda akan mengambil langkah ekstra untuk mengaksesnya.
Menggunakan robots.txt untuk menyembunyikan konten duplikat berbahaya
Konten duplikat identik atau sangat mirip dengan konten lain dalam bahasa yang sama. Google mencoba mengindeks dan menampilkan halaman dengan konten unik. Misalnya, jika situs Anda memiliki versi "reguler" dan "printer" dari setiap artikel dan tag noindex tidak memblokir keduanya, mereka akan mencantumkan salah satunya.
Contoh file robots.txt
Berikut ini adalah beberapa contoh file robots.txt. Ini terutama untuk ide, tetapi jika salah satunya memenuhi kebutuhan Anda, salin dan tempel ke dokumen teks, simpan sebagai "robots.txt," dan unggah ke direktori yang tepat.
Semua akses untuk semua bot
Ada beberapa cara untuk memberitahu mesin pencari untuk mengakses semua file, termasuk memiliki file robots.txt kosong atau tidak sama sekali.
Agen pengguna: *
Melarang:
Tidak ada akses untuk semua bot
File robots.txt berikut menginstruksikan semua mesin pencari untuk menghindari mengakses seluruh situs:
Agen pengguna: *
Larang: /
Blokir satu subdirektori untuk semua bot
Agen pengguna: *
Larang: /folder/
Blokir satu subdirektori untuk semua bot (dengan satu file diperbolehkan)
Agen pengguna: *
Larang: /folder/
Izinkan: /folder/page.html
Blokir satu file untuk semua bot
Agen pengguna: *
Larang: /this-is-a-file.pdf
Blokir satu jenis file (PDF) untuk semua bot
Agen pengguna: *
Larang: /*.pdf$
Blokir semua URL berparameter hanya untuk Googlebot
Agen-pengguna: Googlebot
Larang: /*?
Cara menguji file robots.txt Anda untuk kesalahan
Kesalahan di Robots.txt bisa parah, jadi penting untuk memantaunya. Periksa laporan “Cakupan” di Search Console secara berkala untuk mengetahui masalah yang terkait dengan robot.txt. Beberapa kesalahan yang mungkin Anda temui, apa artinya, dan cara memperbaikinya tercantum di bawah ini.
URL yang dikirimkan diblokir oleh robots.txt
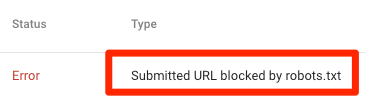
Ini menunjukkan bahwa robots.txt telah memblokir setidaknya satu URL di peta situs Anda. Jika peta situs Anda benar dan tidak menyertakan laman yang dikanonikalisasi, tidak diindeks, atau dialihkan, robots.txt tidak boleh memblokir laman apa pun yang Anda kirim. Jika ya, identifikasi halaman yang terpengaruh dan hapus blokir dari file robots.txt Anda.
Anda dapat menggunakan penguji robots.txt Google untuk mengidentifikasi perintah pemblokiran. Berhati-hatilah saat mengedit file robots.txt Anda karena kesalahan dapat memengaruhi halaman atau file lain.
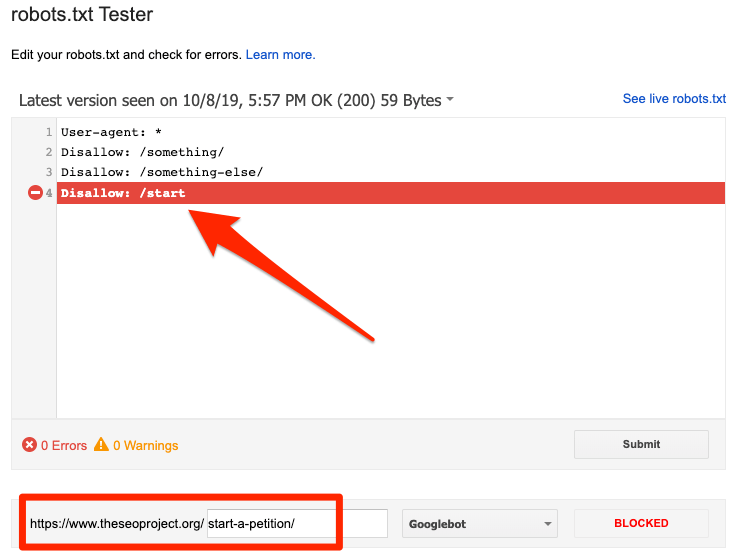
Diblokir oleh robots.txt
Kesalahan ini menunjukkan bahwa robots.txt telah memblokir konten yang tidak dapat diindeks oleh Google. Hapus blok perayapan di robots.txt jika konten ini penting dan harus diindeks. (Juga, periksa apakah konten tidak diindeks.)
Jika Anda ingin mengecualikan konten dari indeks Google, gunakan tag meta robot atau x-robots-header dan hapus blok perayapan. Itulah satu-satunya cara untuk menjauhkan konten dari indeks Google.
Diindeks, meskipun diblokir oleh robots.txt
Artinya Google masih mengindeks beberapa konten yang diblokir oleh robots.txt. Robots.txt bukanlah solusi untuk mencegah konten Anda ditampilkan di hasil pencarian Google.
Untuk mencegah pengindeksan, hapus blok perayapan dan ganti dengan tag meta robots atau header HTTP x-robots-tag. Jika Anda tidak sengaja memblokir konten ini dan ingin Google mengindeksnya, hapus blok perayapan di robots.txt. Ini dapat membantu dalam meningkatkan visibilitas konten dalam pencarian Google.
Robots.txt vs robot meta vs robot x
Apa yang membedakan ketiga perintah robot ini? Robots.txt adalah file teks sederhana, sedangkan meta dan x-robot adalah arahan meta. Di luar peran mendasar mereka, ketiganya memiliki fungsi yang berbeda. Robots.txt menentukan perilaku perayapan untuk seluruh situs web atau direktori, sedangkan meta dan robot x menentukan perilaku pengindeksan untuk setiap halaman (atau elemen halaman).
Bacaan lebih lanjut
Sumber daya yang berguna
- Wikipedia: Protokol Pengecualian Robot
- Dokumentasi Google di Robots.txt
- Dokumentasi Bing (dan Yahoo) di Robots.txt
- Petunjuk dijelaskan
- Dokumentasi Yandex di Robots.txt
Membungkus
Kami harap Anda sepenuhnya memahami pentingnya file robot.txt dan kontribusinya terhadap praktik SEO dan profitabilitas situs web Anda secara keseluruhan. Jika Anda masih berjuang untuk mendapatkan penghasilan dari situs web Anda, Anda tidak perlu coding untuk mulai menghasilkan dengan iklan Adsterra. Letakkan kode iklan di situs HTML, WordPress, atau Blogger Anda dan mulailah menghasilkan keuntungan hari ini!