
Valutazione degli strumenti di web scraping: cosa devono sapere le aziende
Pubblicato: 2024-05-15Il web scraping tramite strumenti automatizzati di web scraping è fondamentale per le organizzazioni che cercano di sfruttare i big data. Consente lo scraping automatizzato di informazioni rilevanti da varie fonti web, il che è essenziale per l'analisi basata sui dati.
Estraendo le attuali tendenze del mercato, le preferenze dei consumatori e le informazioni sulla concorrenza, le aziende possono:
- Fare scelte strategiche informate
- Prodotti su misura per le esigenze del cliente
- Ottimizzare i prezzi per la competitività sul mercato
- Aumentare l'efficienza operativa
Inoltre, se uniti agli strumenti di analisi, i dati raccolti supportano modelli predittivi, arricchendo i processi decisionali. Questa intelligenza competitiva spinge le imprese ad anticipare i cambiamenti del mercato e ad agire in modo proattivo, mantenendo un vantaggio critico nei rispettivi settori.
11 caratteristiche chiave degli strumenti di web scraping automatizzati che le aziende dovrebbero cercare
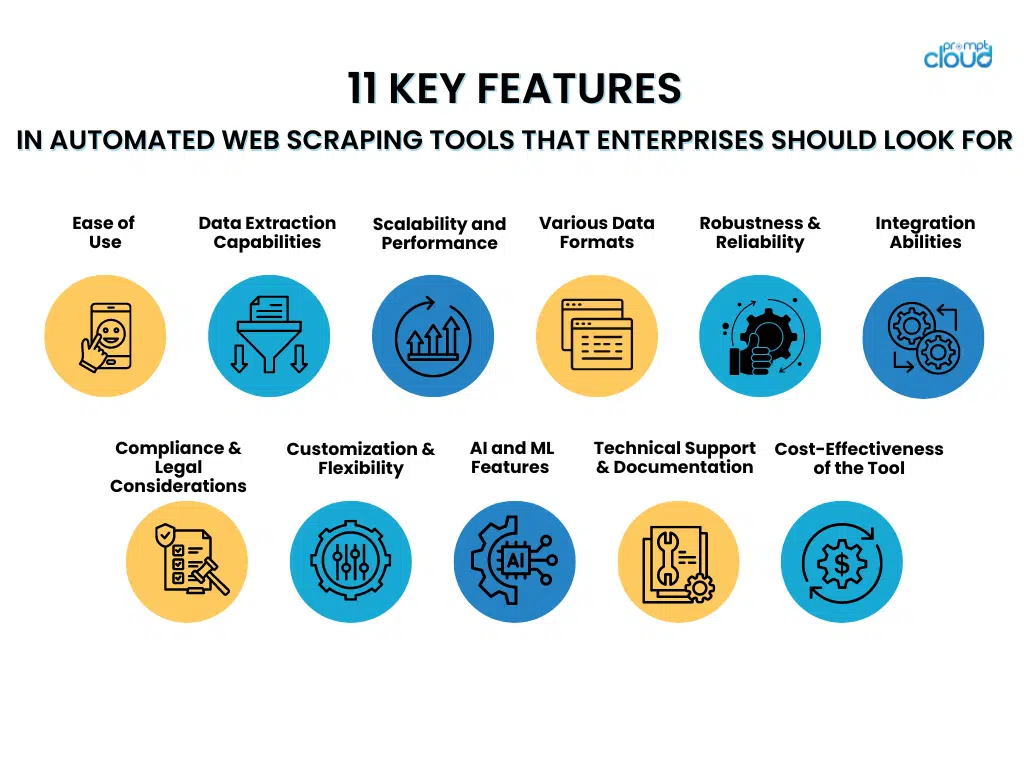
- Facilità d'uso
Quando si scelgono strumenti di web scraping automatizzati, le aziende dovrebbero dare la preferenza a quelli dotati di interfacce facili da usare e passaggi di configurazione semplici. Gli strumenti con interfacce intuitive consentono al personale di utilizzarli in modo efficiente senza una formazione approfondita, consentendo una maggiore concentrazione sul recupero dei dati invece che sulla padronanza di sistemi complessi.
D'altro canto, metodi di configurazione semplici facilitano la rapida implementazione di questi strumenti, riducendo al minimo i ritardi e accelerando il viaggio verso informazioni preziose. Le funzionalità che contribuiscono alla facilità d'uso includono:
- Menù di navigazione chiari e diretti
- Funzionalità drag-and-drop per la progettazione del flusso di lavoro
- Modelli predefiniti per attività di scraping comuni
- Procedure guidate dettagliate guidano la configurazione iniziale
- Documentazione completa ed esercitazioni per facilitare l'apprendimento
Uno strumento intuitivo massimizza l'efficienza dei dipendenti e aiuta a mantenere elevati livelli di produttività.
- Funzionalità di estrazione dati
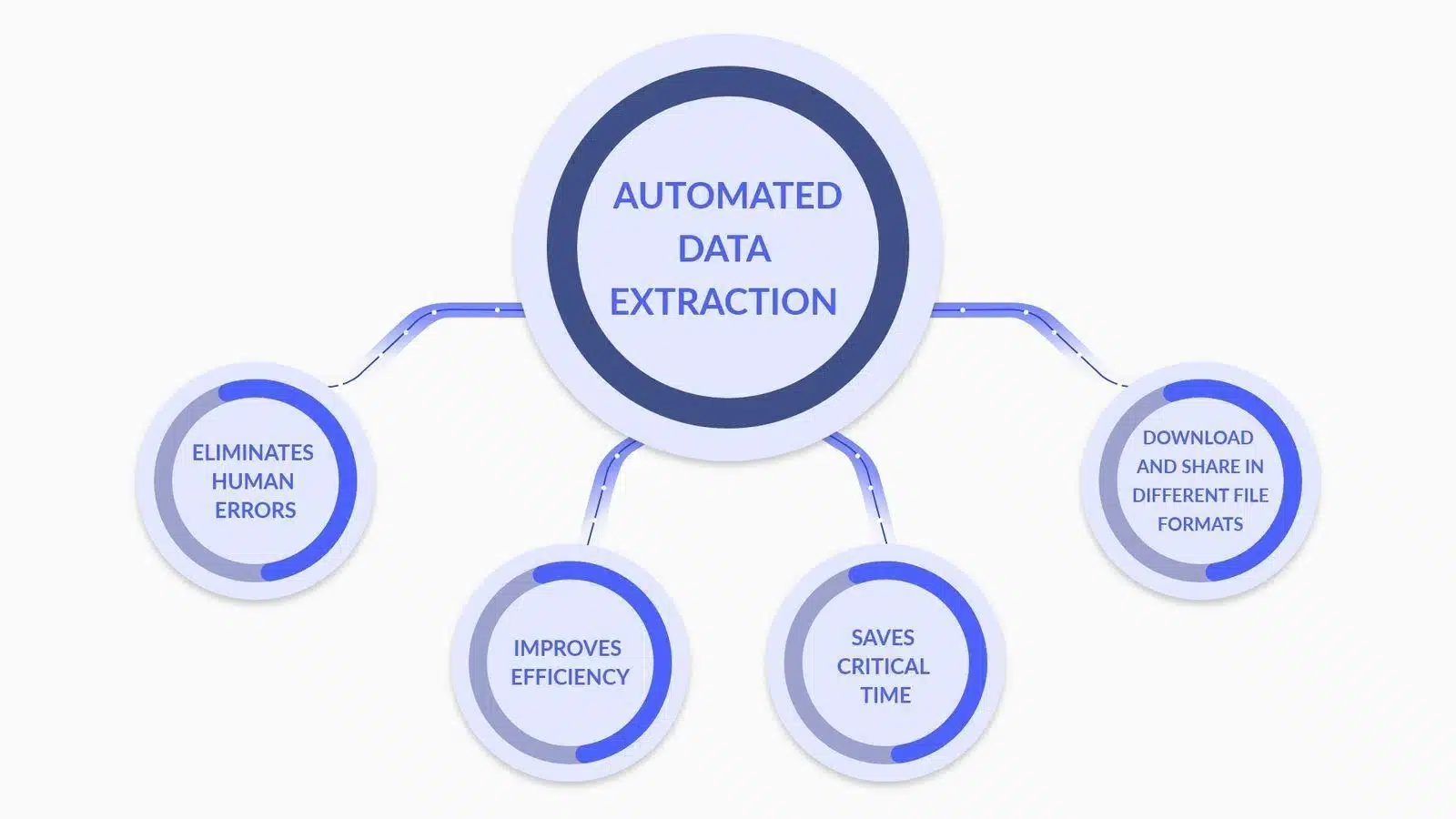
Fonte immagine: cos'è l'estrazione dei dati? Ecco cosa ti serve sapere
Nel valutare gli strumenti automatizzati di web scraping, le aziende dovrebbero dare priorità alle funzionalità avanzate di analisi e trasformazione dei dati come:
- Analisi personalizzata dei dati : capacità di personalizzare i parser per interpretare accuratamente strutture di dati complesse, inclusi contenuti nidificati e dinamici.
- Conversione del tipo di dati : strumenti che convertono automaticamente i dati estratti in formati utilizzabili (ad esempio, date, numeri, stringhe) per un'elaborazione dei dati più efficiente.
- Supporto per le espressioni regolari : inclusione di funzionalità regex per la corrispondenza di modelli sofisticati, consentendo un'estrazione precisa dei dati.
- Trasformazione condizionale : capacità di applicare la logica condizionale ai dati estratti, consentendo la trasformazione in base a criteri o modelli di dati specifici.
- Data Cleansing : funzioni che puliscono e standardizzano i dati nella fase post-estrazione per garantire qualità e coerenza dei dati.
- Integrazione API : strutture per una perfetta integrazione con le API per elaborare e analizzare ulteriormente i dati estratti, migliorando le capacità decisionali.
Ciascuna funzionalità contribuisce a un processo di estrazione dei dati più robusto e accurato, fondamentale per le attività di web scraping a livello aziendale.
- Scalabilità e prestazioni
Nel valutare gli strumenti automatizzati di web scraping, le aziende dovrebbero dare priorità alla scalabilità e agli attributi prestazionali che supportano l’elaborazione efficiente di vasti set di dati.
Uno strumento ideale può gestire abilmente un aumento significativo del carico di lavoro senza compromettere la velocità o la precisione. Le aziende devono cercare funzionalità come:
- Funzionalità multi-threading che consentono l'elaborazione simultanea dei dati
- Gestione efficiente della memoria per gestire attività di scraping su larga scala
- Allocazione dinamica delle risorse basata sulle richieste in tempo reale
- Infrastruttura robusta che può scalare orizzontalmente o verticalmente
- Meccanismi di caching avanzati per accelerare il recupero dei dati
La capacità dello strumento di mantenere le prestazioni sotto carico garantisce un'estrazione affidabile dei dati, anche durante le ore di punta o quando si aumentano le operazioni.
- Supporto per vari formati di dati
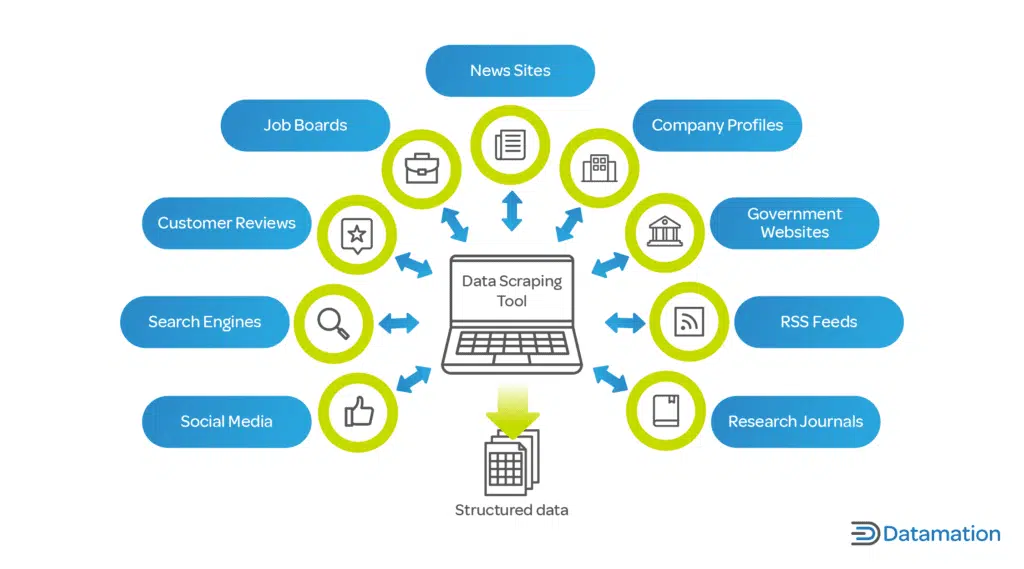
Fonte immagine: cos'è il data scraping? Definizione e come usarlo
Uno strumento di web scraping automatizzato deve gestire abilmente diversi formati di dati. Le aziende spesso lavorano con diversi tipi di dati e la flessibilità nell'estrazione dei dati è fondamentale:
- JSON: un formato leggero per lo scambio di dati che è facile da leggere e scrivere per gli esseri umani e facile da analizzare e generare per le macchine.
- CSV: il formato con valori separati da virgole è un formato di file semplice e comune utilizzato per i dati tabulari. La maggior parte degli strumenti di scraping dovrebbe fornire un'opzione di esportazione CSV.
- XML: Extensible Markup Language, un formato più complesso che include metadati e può essere utilizzato in un'ampia gamma di settori.
La capacità di estrarre ed esportare dati in questi formati garantisce la compatibilità con diversi strumenti e sistemi di analisi dei dati, offrendo una soluzione versatile per le esigenze aziendali.
- Robustezza e affidabilità
Quando le aziende scelgono strumenti automatizzati di web scraping, devono dare priorità alla robustezza e all'affidabilità. Le caratteristiche principali da considerare includono:
- Gestione completa degli errori : uno strumento superiore dovrebbe avere la capacità di rilevare e correggere automaticamente gli errori. Dovrebbe registrare i problemi e, quando possibile, riprovare le richieste non riuscite senza intervento manuale.
- Strategie di minimizzazione dei tempi di inattività : lo strumento dovrebbe includere meccanismi di failover, come server di backup o origini dati alternative, per mantenere le operazioni quando le fonti primarie falliscono.
- Sistemi di monitoraggio continuo : il monitoraggio in tempo reale garantisce che eventuali tempi di inattività vengano immediatamente identificati e risolti, riducendo al minimo le lacune nei dati.
- Manutenzione predittiva : l'utilizzo dell'apprendimento automatico per prevedere potenziali punti di guasto può prevenire preventivamente i tempi di inattività, rendendo il sistema più affidabile.
Investire in strumenti che enfatizzano questi aspetti di robustezza e affidabilità può ridurre significativamente i rischi operativi associati al web scraping.

- Capacità di integrazione
Nel valutare gli strumenti automatizzati di web scraping, le aziende devono garantire la loro capacità di integrarsi in modo fluido con le attuali pipeline di dati. Ciò è essenziale per mantenere la continuità del flusso di dati e ottimizzare il processo. Lo strumento dovrebbe:
- Offri API o connettori compatibili con i database e le piattaforme di analisi esistenti.
- Supporta vari formati di dati per un'importazione/esportazione senza interruzioni garantendo interruzioni minime.
- Fornire funzionalità di automazione che possono essere attivate da eventi all'interno della pipeline di dati.
- Facilita una facile scalabilità senza una riconfigurazione estesa man mano che le esigenze dei dati evolvono.
- Conformità e considerazioni legali
Quando si integra uno strumento di web scraping automatizzato nelle operazioni aziendali, è fondamentale garantire che lo strumento aderisca ai quadri legali. Le caratteristiche da considerare includono:
- Rispetto per Robots.txt : lo strumento dovrebbe riconoscere e rispettare automaticamente il file robots.txt del sito Web, che delinea le autorizzazioni di scraping.
- Limitazione della velocità : per evitare un carico distruttivo sui server host, gli strumenti devono includere una limitazione della velocità regolabile per controllare la frequenza delle richieste.
- Conformità alla privacy dei dati : lo strumento dovrebbe essere costruito in linea con le normative globali sulla protezione dei dati come GDPR o CCPA, garantendo che i dati personali siano gestiti legalmente.
- Consapevolezza della proprietà intellettuale : lo strumento dovrebbe disporre di meccanismi per evitare la violazione dei diritti d'autore durante lo scraping di contenuti protetti da copyright.
- Trasparenza utente-agente : la capacità dello strumento di scraping di identificarsi in modo accurato e trasparente per indirizzare i siti Web, riducendo il rischio di pratiche ingannevoli.
L'inclusione di queste funzionalità può aiutare a mitigare i rischi legali e facilitare una strategia di scraping responsabile che rispetti sia i contenuti proprietari che la privacy degli utenti.
- Personalizzazione e flessibilità
Per soddisfare in modo efficace le proprie specifiche esigenze di raccolta dati, le aziende devono considerare le capacità di personalizzazione e la flessibilità di uno strumento di web scraping automatizzato come fattori cruciali durante la valutazione. Uno strumento superiore dovrebbe:
- Offri un'interfaccia intuitiva per utenti non tecnici per personalizzare i parametri di estrazione dei dati.
- Fornisci opzioni avanzate agli sviluppatori per scrivere script personalizzati o utilizzare API.
- Consentire una facile integrazione con i sistemi e i flussi di lavoro esistenti all'interno dell'azienda.
- Abilita la pianificazione delle attività di scraping da eseguire durante le ore non di punta, riducendo il carico sui server ed evitando potenziali limitazioni del sito web.
- Adattarsi a diverse strutture di siti Web e tipi di dati, garantendo la possibilità di gestire un'ampia gamma di casi d'uso.
La personalizzazione e la flessibilità garantiscono che lo strumento possa evolversi con le mutevoli esigenze dell'azienda, massimizzando il valore e l'efficacia degli sforzi di web scraping.
- Funzionalità avanzate di intelligenza artificiale e apprendimento automatico
Quando si seleziona uno strumento di web scraping automatizzato, le aziende devono considerare l'integrazione dell'intelligenza artificiale avanzata e dell'apprendimento automatico per migliorare l'accuratezza dei dati. Queste funzionalità includono:
- Comprensione contestuale : l'applicazione dell'elaborazione del linguaggio naturale (NLP) consente allo strumento di discernere il contesto, riducendo gli errori nei contenuti estratti.
- Riconoscimento di modelli : gli algoritmi di apprendimento automatico identificano modelli di dati, facilitando l'estrazione accurata delle informazioni.
- Apprendimento adattivo : lo strumento apprende dalle attività di scraping precedenti per ottimizzare i processi di raccolta dati per attività future.
- Rilevamento delle anomalie : i sistemi di intelligenza artificiale possono rilevare e correggere valori anomali o anomalie nei dati raschiati, garantendo l'affidabilità.
- Convalida dei dati : l'uso dell'intelligenza artificiale per la verifica incrociata dei dati raccolti da più fonti migliora la validità delle informazioni.
Sfruttando queste capacità, le aziende possono ridurre sostanzialmente le imprecisioni nei propri set di dati, portando a un processo decisionale più informato.
- Supporto tecnico e documentazione
È consigliabile che le aziende diano la preferenza agli strumenti automatizzati di web scraping forniti con un'ampia assistenza tecnica e una documentazione approfondita. Questo è fondamentale per:
- Riduzione al minimo dei tempi di inattività : il supporto rapido e professionale garantisce che eventuali problemi vengano risolti rapidamente.
- Facilità d'uso : la documentazione ben organizzata aiuta nella formazione degli utenti e nella padronanza degli strumenti.
- Risoluzione dei problemi : guide e risorse accessibili consentono agli utenti di risolvere i problemi comuni in modo indipendente.
- Aggiornamenti e upgrade : un supporto coerente e una documentazione chiara sono fondamentali per navigare in modo efficace tra gli aggiornamenti del sistema e le nuove funzionalità.
La scelta di uno strumento con un solido supporto tecnico e una documentazione chiara è essenziale per un funzionamento senza interruzioni e un'efficiente risoluzione dei problemi.
- Valutazione del rapporto costo-efficacia dello strumento
Le imprese dovrebbero tenere conto sia delle spese iniziali che del possibile ROI nel valutare il software di automazione per il web scraping. I principali fattori di prezzo includono:
- Canoni di licenza o costi di abbonamento
- Spese di manutenzione e supporto
- Potenziale risparmio sui costi derivante dall'automazione
- Scalabilità e adattabilità alle esigenze future
Una valutazione approfondita del ritorno sull’investimento (ROI) di uno strumento dovrebbe tenere conto del suo potenziale nel ridurre il lavoro manuale, migliorare la precisione dei dati e accelerare il processo di acquisizione di informazioni approfondite. Inoltre, le aziende dovrebbero valutare vantaggi duraturi come il miglioramento della competitività derivante da scelte basate sui dati. Il confronto di queste misurazioni con la spesa dello strumento offrirà una visione distinta della sua efficienza in termini di costi.
Conclusione
Quando si sceglie uno strumento di web scraping automatizzato, le aziende dovrebbero considerare meticolosamente ciascuna funzionalità in relazione alle loro esigenze specifiche. È essenziale enfatizzare aspetti come la scalabilità, la precisione dei dati, la velocità, la legalità e l’efficienza in termini di costi. Lo strumento ideale supporterà gli obiettivi aziendali e si integrerà perfettamente con i sistemi attuali. Alla fine, una scelta illuminata deriva da un esame approfondito delle funzionalità dello strumento e da una solida comprensione delle future esigenze di dati dell'azienda.