
Migliori pratiche e casi d'uso per lo scraping dei dati dal sito web
Pubblicato: 2023-12-28Quando si estraggono dati dal sito Web, è essenziale rispettare le normative e la struttura del sito di destinazione. L’adesione alle migliori pratiche non è solo una questione di etica, ma serve anche a evitare complicazioni legali e a garantire l’affidabilità dell’estrazione dei dati. Ecco le considerazioni chiave:
- Aderisci a robots.txt : controlla sempre prima questo file per capire cosa il proprietario del sito ha impostato come vietato per lo scraping.
- Utilizza le API : se disponibile, utilizza l'API ufficiale del sito, che è un metodo più stabile e approvato per accedere ai dati.
- Fai attenzione ai tassi di richiesta : uno scraping eccessivo di dati può gravare sui server dei siti web, quindi calibra le tue richieste in modo ponderato.
- Identificati : attraverso la stringa del tuo user agent, sii trasparente riguardo alla tua identità e al tuo scopo durante lo scraping.
- Gestisci i dati in modo responsabile : archivia e utilizza i dati raschiati secondo le leggi sulla privacy e le normative sulla protezione dei dati.
Il rispetto di queste pratiche garantisce lo scraping etico, mantenendo l'integrità e la disponibilità dei contenuti online.
Comprendere il quadro giuridico
Quando si recuperano dati dal sito Web, è fondamentale navigare tra le restrizioni legali intrecciate. I principali testi legislativi includono:
- Il Computer Fraud and Abuse Act (CFAA): legislazione negli Stati Uniti rende illegale l'accesso a un computer senza la dovuta autorizzazione.
- Regolamento generale sulla protezione dei dati (GDPR) dell'Unione Europea : impone il consenso per l'utilizzo dei dati personali e garantisce alle persone il controllo sui propri dati.
- Il Digital Millennium Copyright Act (DMCA) : protegge dalla distribuzione di contenuti protetti da copyright senza autorizzazione.
Gli scraper devono inoltre rispettare gli accordi sui "termini di utilizzo" dei siti Web, che spesso limitano l'estrazione dei dati. Garantire il rispetto di queste leggi e politiche è essenziale per eliminare in modo etico e legale i dati dei siti Web.
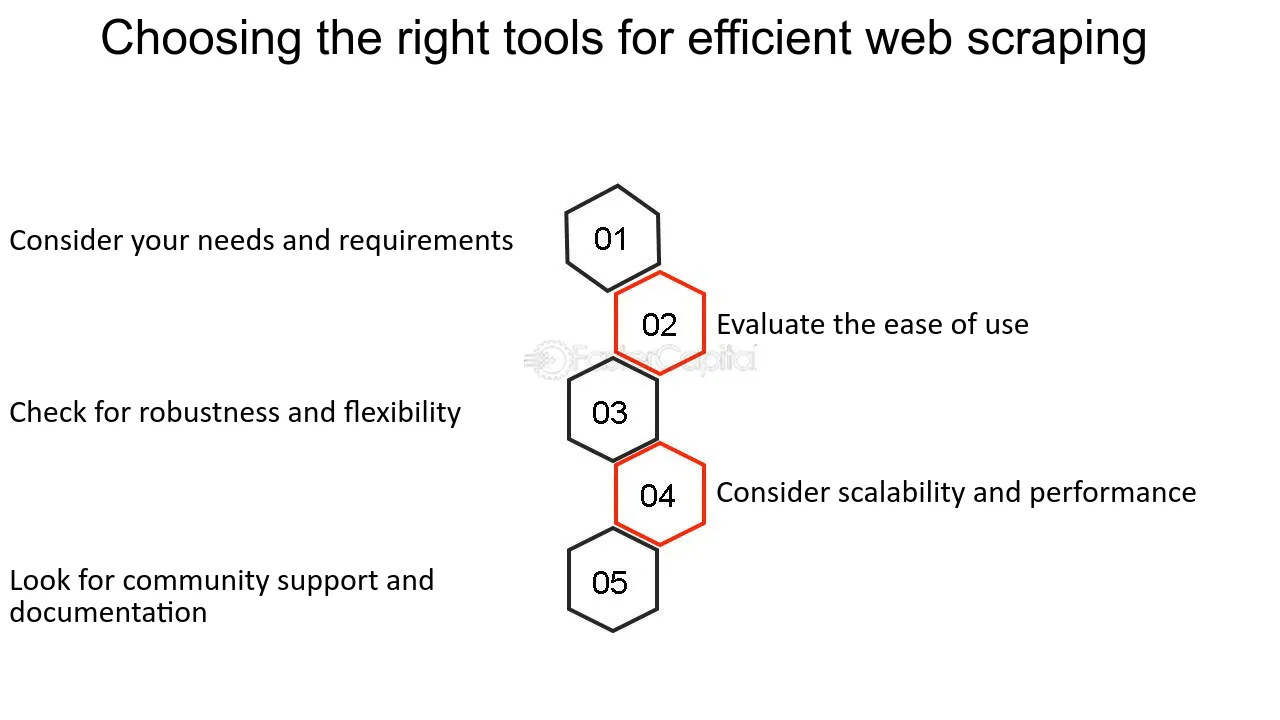
Selezionare gli strumenti giusti per la raschiatura
La scelta degli strumenti corretti è fondamentale quando si avvia un progetto di web scraping. I fattori da considerare includono:
- Complessità del sito Web : i siti dinamici possono richiedere strumenti come Selenium in grado di interagire con JavaScript.
- Quantità di dati : per lo scraping su larga scala, sono consigliabili strumenti con funzionalità di scraping distribuite come Scrapy.
- Legalità ed etica : seleziona strumenti con funzionalità per rispettare robots.txt e imposta stringhe dello user agent.
- Facilità d'uso : i principianti potrebbero preferire le interfacce user-friendly presenti in software come Octoparse.
- Conoscenza di programmazione : i non programmatori potrebbero orientarsi verso software con una GUI, mentre i programmatori potrebbero optare per librerie come BeautifulSoup.
Fonte immagine: https://fastercapital.com/
Migliori pratiche per eliminare in modo efficace i dati dal sito Web
Per estrarre i dati dal sito Web in modo efficiente e responsabile, seguire queste linee guida:
- Rispetta i file robots.txt e i termini del sito web per evitare problemi legali.
- Utilizza le intestazioni e ruota gli user agent per imitare il comportamento umano.
- Implementare il ritardo tra le richieste per ridurre il carico del server.
- Utilizza i proxy per prevenire i divieti IP.
- Effettua lo scraping durante le ore non di punta per ridurre al minimo l'interruzione del sito web.
- Archivia sempre i dati in modo efficiente, evitando voci doppie.
- Garantire l'accuratezza dei dati raschiati con controlli regolari.
- Prestare attenzione alle leggi sulla privacy dei dati durante l'archiviazione e l'utilizzo dei dati.
- Mantieni aggiornati i tuoi strumenti di scraping per gestire le modifiche del sito web.
- Sii sempre pronto ad adattare le strategie di scraping se i siti web aggiornano la loro struttura.
Casi d'uso del data scraping in tutti i settori
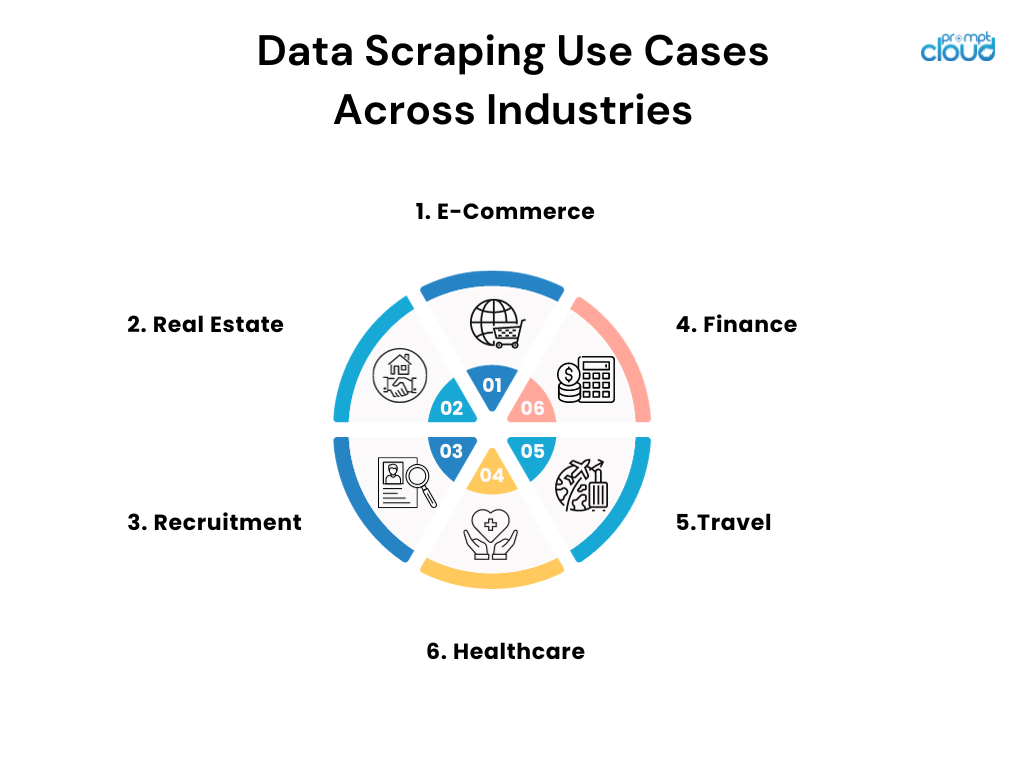
- E-commerce: i rivenditori online utilizzano lo scraping per monitorare i prezzi della concorrenza e adattare di conseguenza le proprie strategie di prezzo.
- Settore immobiliare: agenti e aziende raccolgono elenchi per aggregare informazioni, tendenze e dati sui prezzi sulle proprietà da varie fonti.
- Reclutamento: le aziende raccolgono bacheche di lavoro e social media per trovare potenziali candidati e analizzare le tendenze del mercato del lavoro.
- Finanza: gli analisti analizzano registri pubblici e documenti finanziari per informare le strategie di investimento e tenere traccia dei sentimenti del mercato.
- Viaggi: le agenzie racimolano i prezzi delle compagnie aeree e degli hotel per offrire ai clienti le migliori offerte e pacchetti possibili.
- Sanità: i ricercatori raccolgono database e riviste mediche per rimanere aggiornati sulle ultime scoperte e studi clinici.
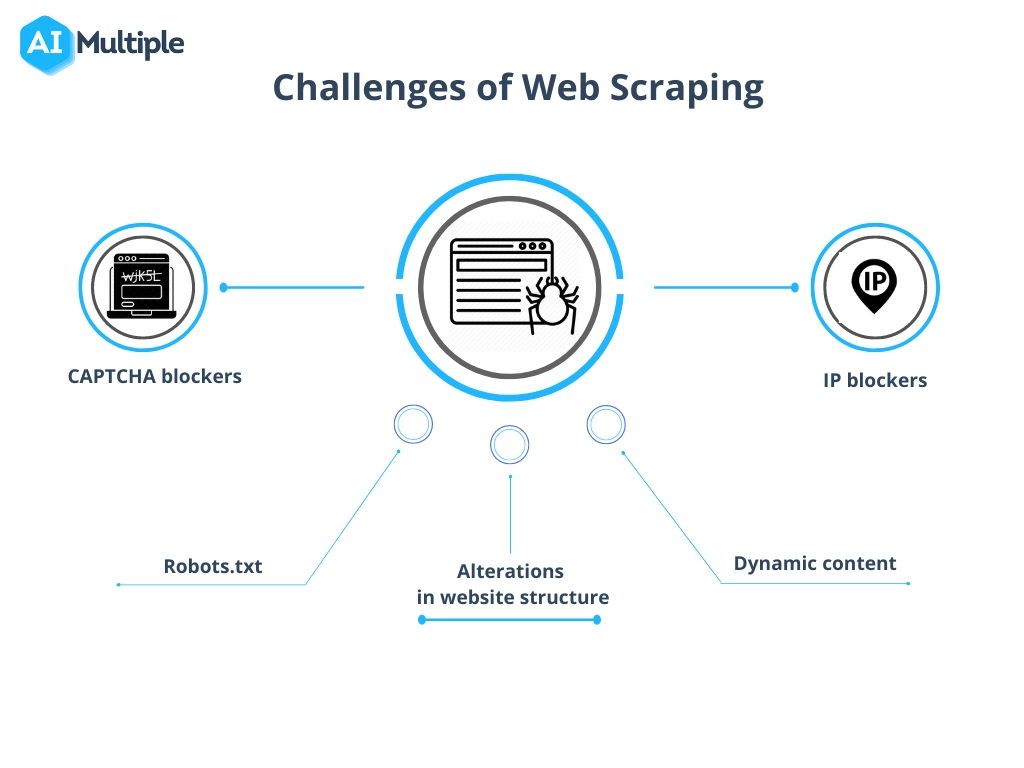
Affrontare le sfide comuni nello scraping dei dati
Il processo di raschiamento dei dati dal sito Web, sebbene estremamente prezioso, spesso comporta il superamento di ostacoli come alterazioni nella struttura del sito Web, misure anti-scraping e preoccupazioni relative alla qualità dei dati.

Fonte immagine: https://research.aimultiple.com/
Per esplorarli in modo efficace:
- Rimani adattivo : aggiorna regolarmente gli script di scraping per adattarli agli aggiornamenti del sito web. L’uso dell’apprendimento automatico può aiutare ad adattarsi dinamicamente ai cambiamenti strutturali.
- Rispettare i confini legali : comprendere e rispettare gli aspetti legali dello scraping per evitare controversie. Assicurati di rivedere il file robots.txt e i termini di servizio su un sito web.
- Parte superiore del modulo
- Mimare l'interazione umana : i siti Web potrebbero bloccare gli scraper che inviano richieste troppo rapidamente. Implementa ritardi e intervalli casuali tra le richieste per sembrare meno robotici.
- Gestire i CAPTCHA : sono disponibili strumenti e servizi in grado di risolvere o aggirare i CAPTCHA, sebbene il loro utilizzo debba essere considerato rispetto alle implicazioni etiche e legali.
- Mantenere l'integrità dei dati : garantire l'accuratezza dei dati estratti. Convalidare regolarmente i dati e pulirli per mantenerne la qualità e l'utilità.
Queste strategie aiutano a superare gli ostacoli comuni allo scraping e facilitano l’estrazione di dati preziosi.
Conclusione
L'estrazione efficiente dei dati dai siti Web è un metodo prezioso con diverse applicazioni, che vanno dalle ricerche di mercato all'analisi competitiva. È essenziale aderire alle migliori pratiche, garantire la legalità, rispettare le linee guida del file robots.txt e controllare attentamente la frequenza di scraping per evitare il sovraccarico del server.
L’applicazione responsabile di questi metodi apre le porte a ricche fonti di dati in grado di fornire informazioni utili e guidare un processo decisionale informato sia per le aziende che per i privati. Una corretta implementazione, unita a considerazioni etiche, garantisce che lo scraping dei dati rimanga uno strumento potente nel panorama digitale.
Pronto a potenziare le tue informazioni estraendo dati dal sito web? Non guardare oltre! PromptCloud offre servizi di web scraping etici e affidabili su misura per le tue esigenze. Connettiti con noi all'indirizzo sales@promptcloud.com per trasformare i dati grezzi in informazioni utilizzabili. Miglioriamo insieme il tuo processo decisionale!
Domande frequenti
È accettabile estrarre dati dai siti Web?
Assolutamente, lo scraping dei dati va bene, ma devi rispettare le regole. Prima di tuffarti in qualsiasi avventura di scraping, dai un'occhiata ai termini di servizio e al file robots.txt del sito web in questione. Mostrare un certo rispetto per il layout del sito web, attenersi ai limiti di frequenza e mantenere le cose etiche sono tutti elementi fondamentali per pratiche responsabili di raccolta dei dati.
Come posso estrarre i dati utente da un sito web tramite scraping?
L'estrazione dei dati degli utenti tramite lo scraping richiede un approccio meticoloso in linea con le norme legali ed etiche. Ove possibile, per il recupero dei dati si consiglia di sfruttare le API disponibili pubblicamente fornite dal sito Web. In assenza di un'API, è imperativo garantire che i metodi di scraping utilizzati aderiscano alle leggi sulla privacy, ai termini di utilizzo e alle politiche stabilite dal sito Web per mitigare potenziali conseguenze legali
Lo scraping dei dati dei siti Web è considerato illegale?
La legalità del web scraping dipende da diversi fattori, tra cui lo scopo, la metodologia e il rispetto delle leggi pertinenti. Sebbene il web scraping in sé non sia intrinsecamente illegale, l'accesso non autorizzato, la violazione dei termini di servizio di un sito Web o il mancato rispetto delle leggi sulla privacy possono portare a conseguenze legali. Una condotta responsabile ed etica nelle attività di web scraping è fondamentale e implica una profonda consapevolezza dei limiti legali e delle considerazioni etiche.
I siti web possono rilevare istanze di web scraping?
I siti Web hanno implementato meccanismi per rilevare e prevenire attività di web scraping, monitorando elementi come stringhe dello user-agent, indirizzi IP e modelli di richiesta. Per mitigare il rilevamento, le migliori pratiche includono l'impiego di tecniche come la rotazione degli agenti utente, l'utilizzo di proxy e l'implementazione di ritardi casuali tra le richieste. Tuttavia, è fondamentale notare che i tentativi di eludere le misure di rilevamento possono violare i termini di servizio di un sito Web e potenzialmente comportare conseguenze legali. Le pratiche responsabili ed etiche di web scraping danno priorità alla trasparenza e al rispetto degli standard legali ed etici.