
Estrazione dati da siti Web dinamici: sfide e soluzioni
Pubblicato: 2023-11-23Internet ospita un vasto serbatoio di dati in continua espansione, offrendo un enorme valore ad aziende, ricercatori e individui alla ricerca di approfondimenti, processi decisionali informati o soluzioni innovative. Tuttavia, una parte sostanziale di queste preziose informazioni risiede all'interno di siti Web dinamici.
A differenza dei siti Web statici convenzionali, i siti Web dinamici generano dinamicamente contenuti in risposta alle interazioni dell'utente o a eventi esterni. Questi siti sfruttano tecnologie come JavaScript per manipolare il contenuto delle pagine web, ponendo una sfida formidabile alle tradizionali tecniche di web scraping per estrarre efficacemente i dati.
In questo articolo, approfondiremo il regno dello scraping dinamico delle pagine web. Esamineremo le sfide tipiche legate a questo processo e presenteremo strategie efficaci e migliori pratiche per superare questi ostacoli.
Comprendere i siti Web dinamici
Prima di addentrarsi nelle complessità dello scraping di pagine web dinamiche, è essenziale stabilire una chiara comprensione di ciò che caratterizza un sito web dinamico. A differenza delle controparti statiche che forniscono contenuti uniformi universalmente, i siti Web dinamici generano dinamicamente contenuti in base a vari parametri come le preferenze dell'utente, le query di ricerca o i dati in tempo reale.
I siti Web dinamici spesso sfruttano sofisticati framework JavaScript per modificare e aggiornare dinamicamente il contenuto della pagina Web sul lato client. Sebbene questo approccio migliori significativamente l'interattività dell'utente, introduce delle sfide quando si tenta di estrarre i dati a livello di codice.
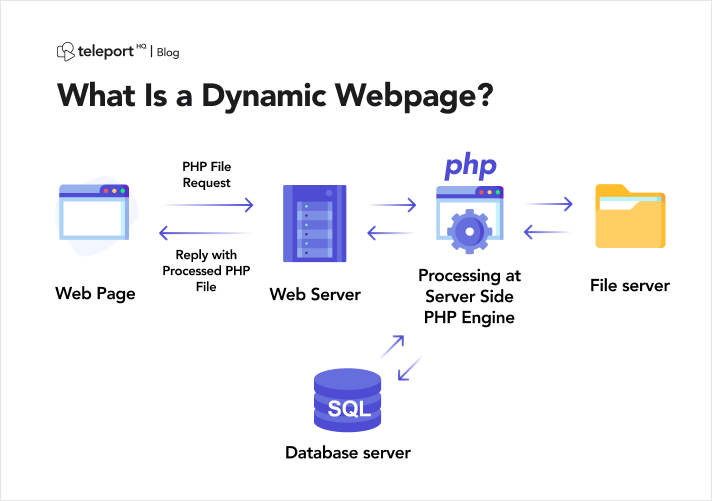
Fonte immagine: https://teleporthq.io/
Sfide comuni nello scraping di pagine Web dinamiche
Lo scraping dinamico delle pagine Web pone diverse sfide a causa della natura dinamica del contenuto. Alcune delle sfide più comuni includono:
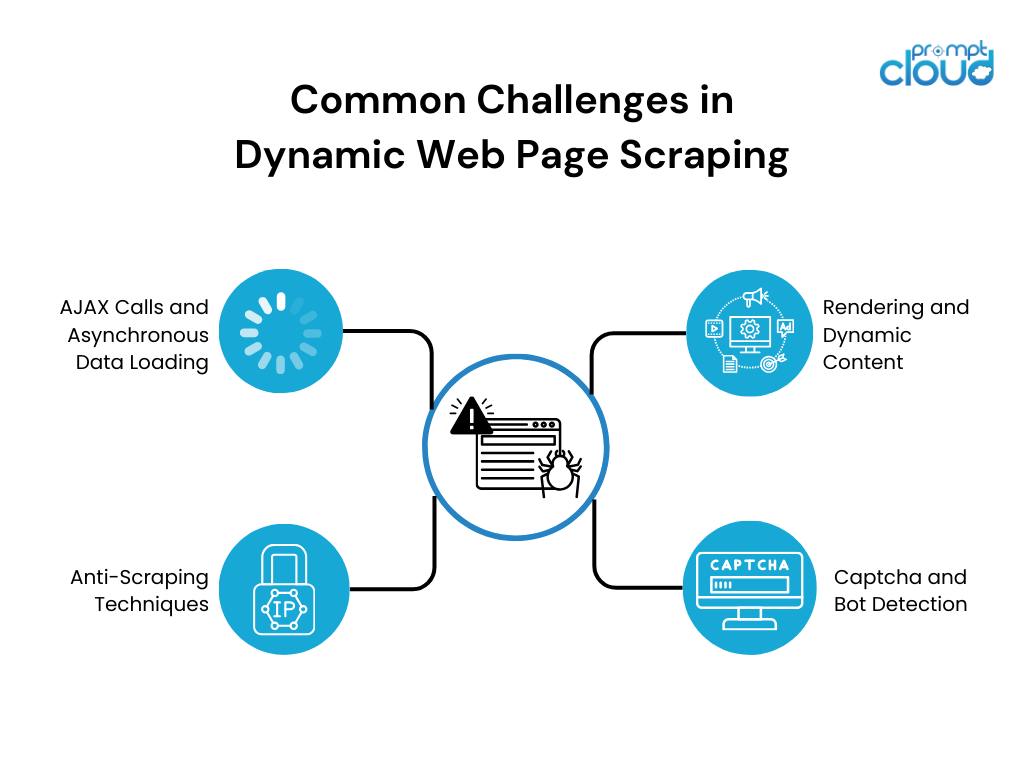
- Rendering e contenuto dinamico: i siti Web dinamici fanno molto affidamento su JavaScript per eseguire il rendering dinamico dei contenuti. Gli strumenti tradizionali di web scraping faticano a interagire con i contenuti basati su JavaScript, con conseguente estrazione dei dati incompleta o errata.
- Chiamate AJAX e caricamento asincrono dei dati: molti siti Web dinamici utilizzano chiamate JavaScript asincrone e XML (AJAX) per recuperare dati dai server Web senza ricaricare l'intera pagina. Questo caricamento asincrono dei dati può rendere difficile il recupero del set di dati completo, poiché potrebbe essere caricato progressivamente o attivato dalle interazioni dell'utente.
- Rilevamento di captcha e bot: per impedire lo scraping e la protezione dei dati, i siti Web utilizzano varie contromisure come captcha e meccanismi di rilevamento dei bot. Queste misure di sicurezza ostacolano gli sforzi di raschiamento e richiedono strategie aggiuntive per superarle.
- Tecniche anti-scraping: i siti Web utilizzano varie tecniche anti-scraping come il blocco IP, la limitazione della velocità o strutture HTML offuscate per scoraggiare gli scraper. Queste tecniche richiedono strategie di scraping adattive per eludere il rilevamento e recuperare con successo i dati desiderati.
Strategie per il successo dello scraping di pagine Web dinamiche
Nonostante le sfide, esistono diverse strategie e tecniche che possono essere impiegate per superare gli ostacoli incontrati durante lo scraping di pagine Web dinamiche. Queste strategie includono:
- Utilizzo di browser headless: i browser headless come Puppeteer o Selenium consentono l'esecuzione di JavaScript e il rendering di contenuti dinamici, consentendo l'estrazione accurata dei dati dai siti Web dinamici.
- Ispezione del traffico di rete: l'analisi del traffico di rete può fornire informazioni dettagliate sul flusso di dati all'interno di un sito Web dinamico. Questa conoscenza può essere utilizzata per identificare le chiamate AJAX, intercettare le risposte ed estrarre i dati richiesti.
- Analisi del contenuto dinamico: l'analisi del DOM HTML dopo che il contenuto dinamico è stato reso da JavaScript può aiutare a estrarre i dati desiderati. Strumenti come Beautiful Soup o Cheerio possono essere utilizzati per analizzare ed estrarre dati dal DOM aggiornato.
- Rotazione IP e proxy: la rotazione degli indirizzi IP e l'utilizzo dei proxy possono aiutare a superare le sfide legate al blocco IP e alla limitazione della velocità. Consente lo scraping distribuito e impedisce ai siti Web di identificare lo scraper come un'unica fonte.
- Gestire i Captcha e le tecniche anti-scraping: di fronte ai Captcha, l'utilizzo di servizi di risoluzione dei captcha o l'implementazione dell'emulazione umana può aiutare a bypassare queste misure. Inoltre, le strutture HTML offuscate possono essere decodificate utilizzando tecniche come l'attraversamento del DOM o il riconoscimento di modelli.
Migliori pratiche per il web scraping dinamico
Durante lo scraping di pagine Web dinamiche, è importante seguire alcune migliori pratiche per garantire un processo di scraping etico e di successo. Alcune migliori pratiche includono:

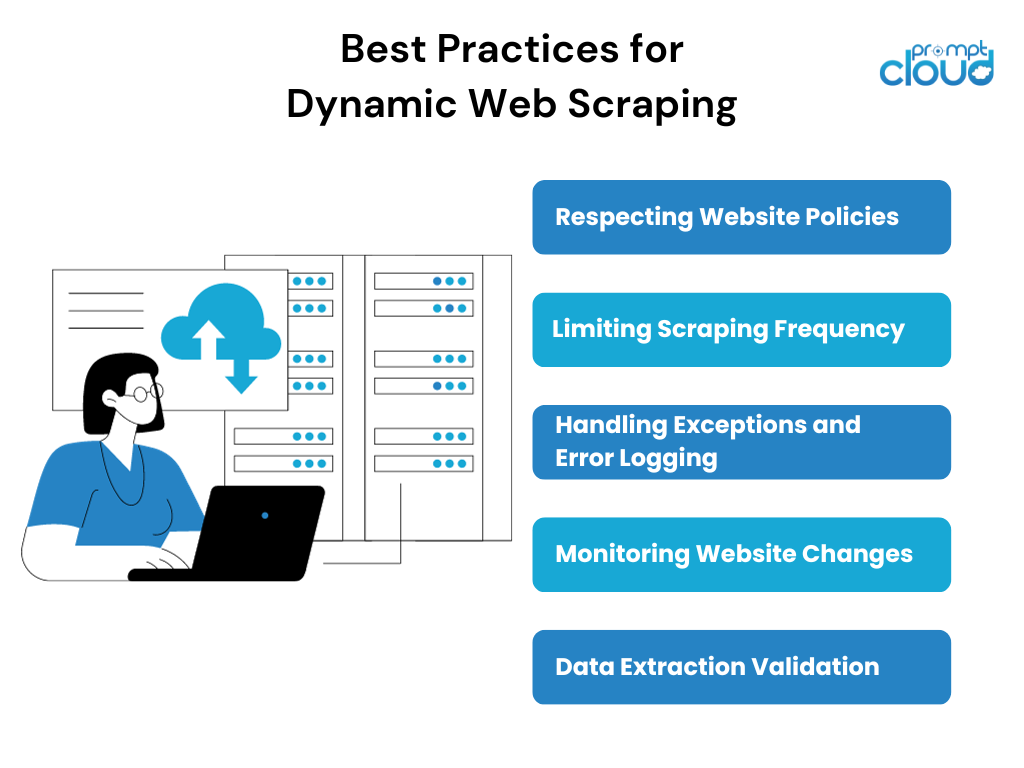
- Rispetto delle politiche del sito web: prima di effettuare lo scraping di qualsiasi sito web, è essenziale rivedere e rispettare i termini di servizio del sito web, il file robots.txt e tutte le linee guida specifiche sullo scraping menzionate.
- Limitare la frequenza di scraping: uno scraping eccessivo può mettere a dura prova sia le risorse dello scraper che il sito web sottoposto a scraping. L'implementazione di limiti di frequenza di scraping ragionevoli e il rispetto dei limiti di velocità stabiliti dal sito Web possono aiutare a mantenere un processo di scraping armonioso.
- Gestione delle eccezioni e registrazione degli errori: il web scraping dinamico implica la gestione di scenari imprevedibili come errori di rete, richieste captcha o cambiamenti nella struttura del sito web. L'implementazione di meccanismi adeguati di gestione delle eccezioni e di registrazione degli errori aiuterà a identificare e risolvere questi problemi.
- Monitoraggio delle modifiche del sito Web: i siti Web dinamici vengono spesso sottoposti ad aggiornamenti o riprogettazioni, che possono interrompere gli script di scraping esistenti. Il monitoraggio regolare del sito Web di destinazione per eventuali modifiche e l'adeguamento tempestivo della strategia di scraping possono garantire un'estrazione dei dati ininterrotta.
- Convalida dell'estrazione dei dati: la convalida e il riferimento incrociato dei dati estratti con l'interfaccia utente del sito Web possono aiutare a garantire l'accuratezza e la completezza delle informazioni raccolte. Questo passaggio di convalida è particolarmente cruciale quando si creano pagine Web dinamiche con contenuti in evoluzione.
Conclusione
La potenza dello scraping di pagine Web dinamiche apre un mondo di opportunità per accedere a dati preziosi nascosti all'interno di siti Web dinamici. Superare le sfide associate allo scraping di siti Web dinamici richiede una combinazione di competenze tecniche e adesione a pratiche di scraping etiche.
Comprendendo le complessità dello scraping di pagine Web dinamiche e implementando le strategie e le migliori pratiche descritte in questo articolo, le aziende e gli individui possono sbloccare l'intero potenziale dei dati Web e ottenere un vantaggio competitivo in vari domini.
Un'altra sfida incontrata nello scraping di pagine Web dinamiche è il volume di dati che devono essere estratti. Le pagine Web dinamiche spesso contengono una grande quantità di informazioni, rendendo difficile raccogliere ed estrarre i dati rilevanti in modo efficiente.
Per superare questo ostacolo, le aziende possono sfruttare l’esperienza dei fornitori di servizi di web scraping. La potente infrastruttura di scraping e le tecniche avanzate di estrazione dei dati di PromptCloud consentono alle aziende di gestire con facilità progetti di scraping su larga scala.
Con l'assistenza di PromptCloud, le organizzazioni possono estrarre informazioni preziose da pagine Web dinamiche e trasformarle in informazioni fruibili. Sperimenta la potenza dello scraping dinamico delle pagine Web collaborando oggi stesso con PromptCloud. Contattaci a sales@promptcloud.com.