
Scraping di pagine Web dinamiche con Python: guida pratica
Pubblicato: 2024-06-08Il web scraping dinamico prevede il recupero di dati da siti Web che generano contenuti in tempo reale tramite JavaScript o Python. A differenza delle pagine Web statiche, i contenuti dinamici vengono caricati in modo asincrono, rendendo inefficienti le tradizionali tecniche di scraping.
Lo scraping web dinamico utilizza:
- Siti Web basati su AJAX
- Applicazioni a pagina singola (SPA)
- Siti con elementi di caricamento ritardati
Strumenti e tecnologie chiave:
- Selenio : automatizza le interazioni del browser.
- BeautifulSoup : analizza il contenuto HTML.
- Richieste : recupera il contenuto della pagina Web.
- lxml – Analizza XML e HTML.
Python per il web scraping dinamico richiede una comprensione più approfondita delle tecnologie web per raccogliere in modo efficace dati in tempo reale.
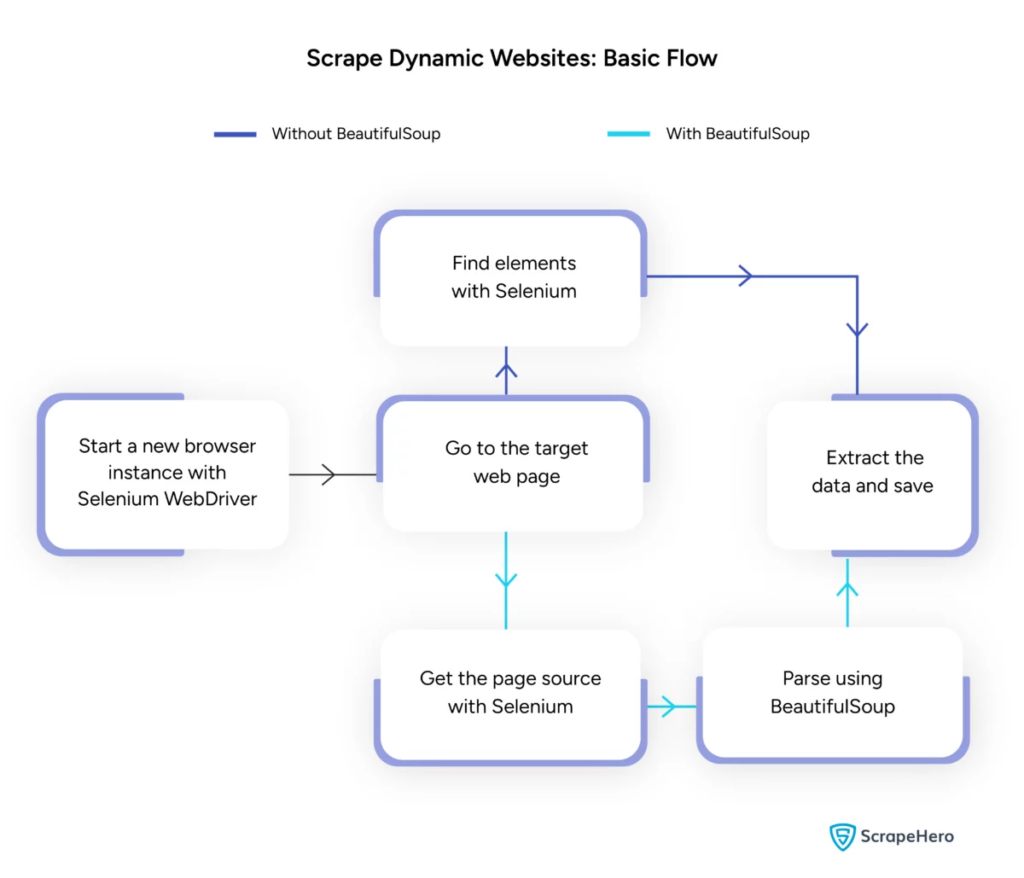
Fonte immagine: https://www.scrapehero.com/scrape-a-dynamic-website/
Configurazione dell'ambiente Python
Per iniziare il web scraping dinamico Python, è essenziale configurare correttamente l'ambiente. Segui questi passi:
- Installa Python : assicurati che Python sia installato sulla macchina. L'ultima versione può essere scaricata dal sito Web ufficiale di Python.
- Creare un ambiente virtuale :

Attiva l'ambiente virtuale:

- Installa le librerie richieste :

- Configura un editor di codice : utilizza un IDE come PyCharm, VSCode o Jupyter Notebook per scrivere ed eseguire script.
- Familiarizzare con HTML/CSS : comprendere la struttura della pagina Web aiuta a navigare ed estrarre i dati in modo efficace.
Questi passaggi stabiliscono una solida base per progetti Python di web scraping dinamico.
Comprendere le nozioni di base sulle richieste HTTP
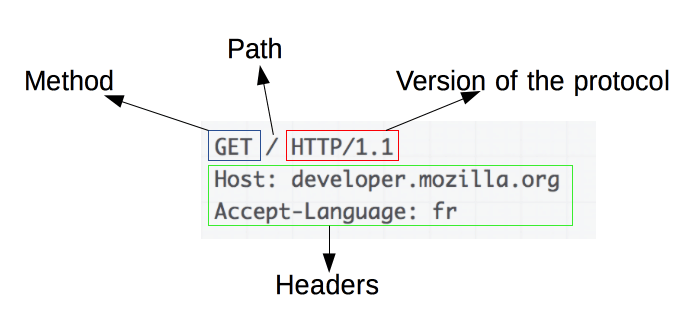
Fonte immagine: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Le richieste HTTP sono il fondamento del web scraping. Quando un client, come un browser web o un web scraper, desidera recuperare informazioni da un server, invia una richiesta HTTP. Queste richieste seguono una struttura specifica:
- Metodo : l'azione da eseguire, ad esempio GET o POST.
- URL : l'indirizzo della risorsa sul server.
- Intestazioni : metadati sulla richiesta, come tipo di contenuto e user-agent.
- Corpo : dati facoltativi inviati con la richiesta, generalmente utilizzati con POST.
Comprendere come interpretare e costruire questi componenti è essenziale per un web scraping efficace. Le librerie Python come le richieste semplificano questo processo, consentendo un controllo preciso sulle richieste.
Installazione delle librerie Python
Fonte immagine: https://ajaytech.co/what-are-python-libraries/
Per lo scraping web dinamico con Python, assicurati che Python sia installato. Apri il terminale o il prompt dei comandi e installa le librerie necessarie utilizzando pip:
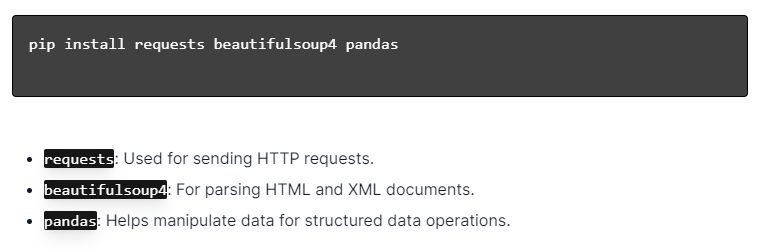
Successivamente, importa queste librerie nel tuo script:

In questo modo, ogni libreria sarà resa disponibile per attività di web scraping, come l'invio di richieste, l'analisi di HTML e la gestione efficiente dei dati.
Creazione di un semplice script di web scraping
Per creare uno script di web scraping dinamico di base in Python, è necessario prima installare le librerie necessarie. La libreria "richieste" gestisce le richieste HTTP, mentre "BeautifulSoup" analizza il contenuto HTML.
Passaggi da seguire:
- Installa le dipendenze:

- Importa librerie:

- Ottieni contenuto HTML:
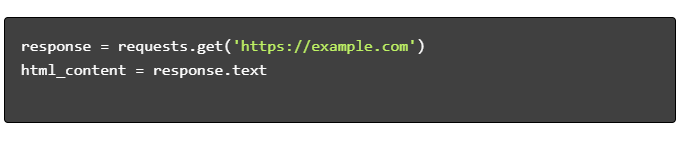
- Analizza HTML:

- Estrai dati:

Gestire il web scraping dinamico con Python
I siti web dinamici generano contenuti al volo, spesso richiedendo tecniche più sofisticate.

Considera i seguenti passaggi:
- Identifica gli elementi target : ispeziona la pagina web per individuare il contenuto dinamico.
- Scegli un framework Python : utilizza librerie come Selenium o Playwright.
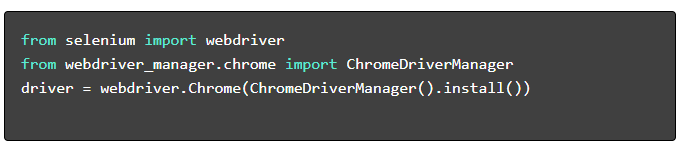
- Installa i pacchetti richiesti :
- Configura WebDriver :

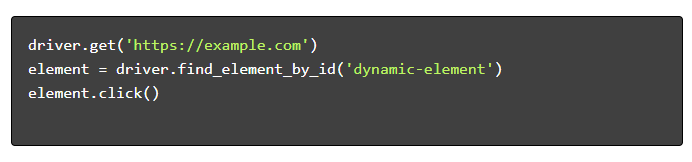
- Naviga e interagisci :
Migliori pratiche di web scraping
Si consiglia di seguire le migliori pratiche di web scraping per garantire efficienza e legalità. Di seguito sono riportate le linee guida principali e le strategie di gestione degli errori:
- Rispetta Robots.txt : controlla sempre il file robots.txt del sito di destinazione.
- Limitazione : implementa ritardi per prevenire il sovraccarico del server.
- User-Agent : utilizza una stringa User-Agent personalizzata per evitare potenziali blocchi.
- Logica dei tentativi : utilizza i blocchi try-eccetto e imposta la logica dei tentativi per gestire i timeout del server.
- Registrazione : mantiene registri completi per il debug.
- Gestione delle eccezioni : rileva in modo specifico errori di rete, errori HTTP ed errori di analisi.
- Rilevamento Captcha : incorpora strategie per rilevare, risolvere o aggirare i CAPTCHA.
Sfide comuni di web scraping dinamico
Captcha
Molti siti Web utilizzano i CAPTCHA per prevenire i bot automatizzati. Per bypassare questo:
- Utilizza servizi di risoluzione CAPTCHA come 2Captcha.
- Implementare l'intervento umano per la risoluzione dei CAPTCHA.
- Utilizza i proxy per limitare i tassi di richiesta.
Blocco IP
I siti potrebbero bloccare gli IP che effettuano troppe richieste. Contrasta questo:
- Utilizzando proxy rotanti.
- Implementazione della limitazione delle richieste.
- Utilizzo di strategie di rotazione utente-agente.
Rappresentazione JavaScript
Alcuni siti caricano i contenuti tramite JavaScript. Affronta questa sfida:
- Utilizzo di Selenium o Puppeteer per l'automazione del browser.
- Utilizzo di Scrapy-splash per il rendering di contenuti dinamici.
- Esplorare i browser headless per interagire con JavaScript.
Questioni legali
Il web scraping a volte può violare i termini di servizio. Garantire la conformità:
- Consulenza legale.
- Scraping di dati accessibili al pubblico.
- Rispettare le direttive robots.txt.
Analisi dei dati
Gestire strutture dati incoerenti può essere impegnativo. Le soluzioni includono:
- Utilizzo di librerie come BeautifulSoup per l'analisi HTML.
- Utilizzo di espressioni regolari per l'estrazione del testo.
- Utilizzo di parser JSON e XML per dati strutturati.
Archiviazione e analisi dei dati raschiati
L'archiviazione e l'analisi dei dati raschiati sono passaggi cruciali nel web scraping. La decisione su dove archiviare i dati dipende dal volume e dal formato. Le opzioni di archiviazione comuni includono:
- File CSV : facili per set di dati di piccole dimensioni e analisi semplici.
- Database : database SQL per dati strutturati; NoSQL per non strutturato.
Una volta archiviati, l'analisi dei dati può essere eseguita utilizzando le librerie Python:
- Panda : ideali per la manipolazione e la pulizia dei dati.
- NumPy : efficiente per le operazioni numeriche.
- Matplotlib e Seaborn : adatti per la visualizzazione dei dati.
- Scikit-learn : fornisce strumenti per l'apprendimento automatico.
Una corretta archiviazione e analisi dei dati migliora l’accessibilità e gli approfondimenti dei dati.
Conclusione e passi successivi
Dopo aver percorso un web scraping dinamico Python, è fondamentale affinare la comprensione degli strumenti e delle librerie evidenziate.
- Rivedi il codice : consulta lo script finale e modularizzalo ove possibile per migliorare la riusabilità.
- Librerie aggiuntive : esplora librerie avanzate come Scrapy o Splash per esigenze più complesse.
- Archiviazione dei dati : prendi in considerazione opzioni di archiviazione affidabili: database SQL o archiviazione nel cloud per la gestione di set di dati di grandi dimensioni.
- Considerazioni legali ed etiche : rimani aggiornato sulle linee guida legali sul web scraping per evitare potenziali violazioni.
- Progetti successivi : affrontare nuovi progetti di web scraping con complessità diverse consoliderà ulteriormente queste competenze.
Stai cercando di integrare il web scraping dinamico professionale con Python nel tuo progetto? Per quei team che necessitano di un'estrazione di dati su larga scala senza la complessità di gestirli internamente, PromptCloud offre soluzioni su misura. Esplora i servizi PromptCloud per una soluzione solida e affidabile. Contattaci oggi!