
Come funziona un web crawler
Pubblicato: 2023-12-05I web crawler hanno una funzione vitale nell'indicizzazione e nella strutturazione delle numerose informazioni presenti su Internet. Il loro ruolo consiste nell'attraversare le pagine Web, raccogliere dati e renderli ricercabili. Questo articolo approfondisce i meccanismi di un web crawler, fornendo approfondimenti sui suoi componenti, operazioni e diverse categorie. Immergiamoci nel mondo dei web crawler!
Cos'è un web crawler
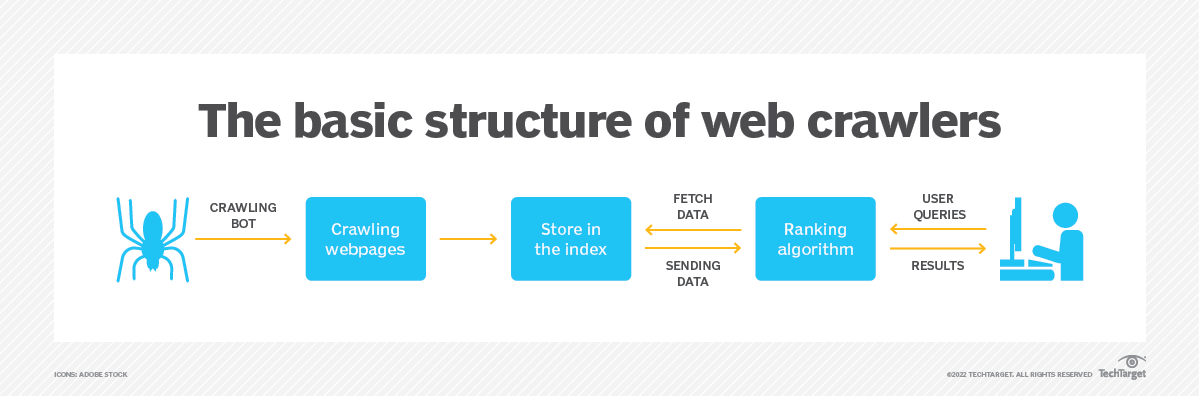
Un web crawler, denominato spider o bot, è uno script o un programma automatizzato progettato per navigare metodicamente attraverso i siti Web Internet. Inizia con un URL seed e poi segue i collegamenti HTML per visitare altre pagine web, formando una rete di pagine interconnesse che possono essere indicizzate e analizzate.
Fonte immagine: https://www.techtarget.com/
Lo scopo di un web crawler
L'obiettivo principale di un web crawler è raccogliere informazioni dalle pagine web e generare un indice ricercabile per un recupero efficiente. I principali motori di ricerca come Google, Bing e Yahoo fanno molto affidamento sui web crawler per costruire i propri database di ricerca. Attraverso l'esame sistematico dei contenuti web, i motori di ricerca possono fornire agli utenti risultati di ricerca pertinenti e attuali.
È importante notare che l'applicazione dei web crawler si estende oltre i motori di ricerca. Vengono inoltre utilizzati da varie organizzazioni per attività quali data mining, aggregazione di contenuti, monitoraggio di siti Web e persino sicurezza informatica.
I componenti di un web crawler
Un web crawler è composto da diversi componenti che lavorano insieme per raggiungere i suoi obiettivi. Ecco i componenti chiave di un web crawler:
- URL Frontier: questo componente gestisce la raccolta di URL in attesa di essere scansionati. Dà la priorità agli URL in base a fattori quali pertinenza, freschezza o importanza del sito web.
- Downloader: il downloader recupera le pagine Web in base agli URL forniti dalla frontiera degli URL. Invia richieste HTTP ai server Web, riceve risposte e salva il contenuto Web recuperato per un'ulteriore elaborazione.
- Parser: il parser elabora le pagine Web scaricate, estraendo informazioni utili come collegamenti, testo, immagini e metadati. Analizza la struttura della pagina ed estrae gli URL delle pagine collegate da aggiungere alla frontiera degli URL.
- Archiviazione dati: il componente di archiviazione dati archivia i dati raccolti, comprese le pagine Web, le informazioni estratte e i dati di indicizzazione. Questi dati possono essere archiviati in vari formati come un database o un file system distribuito.
Come funziona un web crawler
Dopo aver approfondito gli elementi coinvolti, approfondiamo la procedura sequenziale che chiarisce il funzionamento di un web crawler:
- URL seed: il crawler inizia con un URL seed, che potrebbe essere qualsiasi pagina Web o un elenco di URL. Questo URL viene aggiunto alla frontiera dell'URL per avviare il processo di scansione.
- Recupero: il crawler seleziona un URL dalla frontiera degli URL e invia una richiesta HTTP al server web corrispondente. Il server risponde con il contenuto della pagina web, che viene poi recuperato dal componente downloader.
- Analisi: il parser elabora la pagina Web recuperata, estraendo informazioni rilevanti come collegamenti, testo e metadati. Inoltre identifica e aggiunge nuovi URL trovati nella pagina alla frontiera degli URL.
- Analisi dei collegamenti: il crawler dà la priorità e aggiunge gli URL estratti alla frontiera degli URL in base a determinati criteri come pertinenza, freschezza o importanza. Ciò aiuta a determinare l'ordine in cui il crawler visiterà e scansionerà le pagine.
- Ripeti il processo: il crawler continua il processo selezionando gli URL dalla frontiera degli URL, recuperando il loro contenuto web, analizzando le pagine ed estraendo più URL. Questo processo viene ripetuto finché non ci sono più URL da scansionare o finché non viene raggiunto un limite predefinito.
- Archiviazione dati: durante tutto il processo di scansione, i dati raccolti vengono archiviati nel componente di archiviazione dati. Questi dati possono essere successivamente utilizzati per l'indicizzazione, l'analisi o altri scopi.
Tipi di web crawler
I web crawler sono disponibili in diverse varianti e hanno casi d'uso specifici. Ecco alcuni tipi di web crawler comunemente utilizzati:

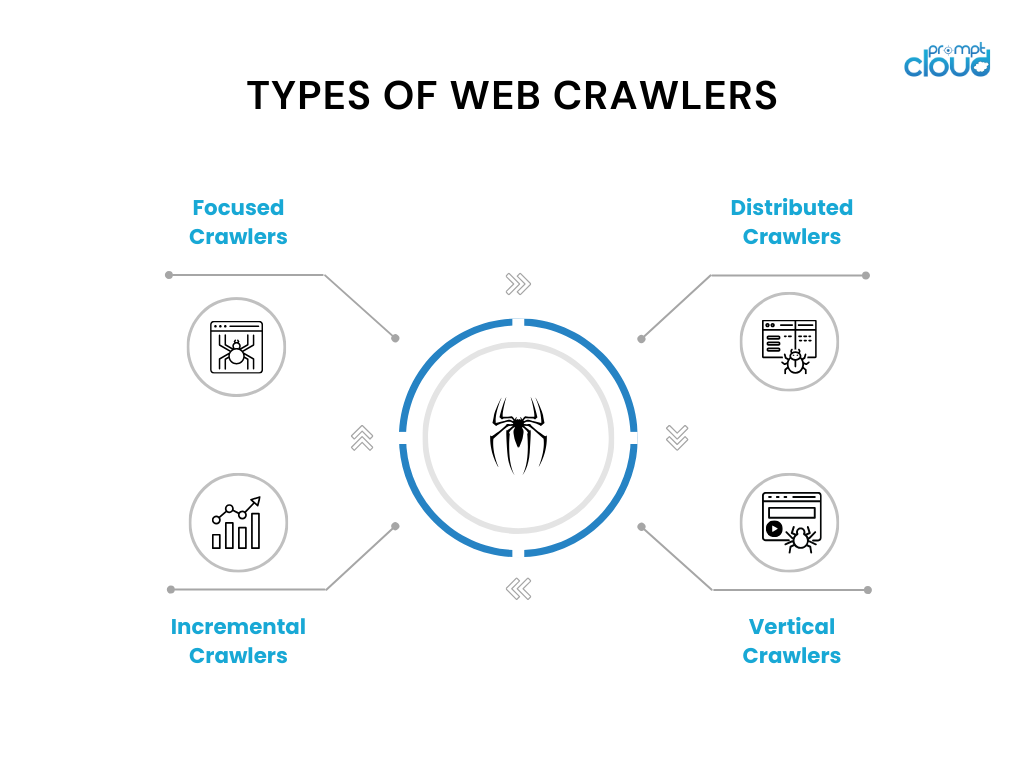
- Crawler mirati: questi crawler operano all'interno di un dominio o argomento specifico ed eseguono la scansione delle pagine pertinenti a quel dominio. Gli esempi includono crawler topici utilizzati per siti Web di notizie o documenti di ricerca.
- Crawler incrementali: i crawler incrementali si concentrano sulla scansione di contenuti nuovi o aggiornati dall'ultima scansione. Utilizzano tecniche come l'analisi del timestamp o algoritmi di rilevamento delle modifiche per identificare e scansionare le pagine modificate.
- Crawler distribuiti: nei crawler distribuiti, più istanze del crawler vengono eseguite in parallelo, condividendo il carico di lavoro della scansione di un vasto numero di pagine. Questo approccio consente una scansione più rapida e una migliore scalabilità.
- Crawler verticali: i crawler verticali prendono di mira tipi specifici di contenuti o dati all'interno delle pagine Web, come immagini, video o informazioni sul prodotto. Sono progettati per estrarre e indicizzare tipi specifici di dati per motori di ricerca specializzati.
Con quale frequenza dovresti scansionare le pagine web?
La frequenza di scansione delle pagine Web dipende da diversi fattori, tra cui le dimensioni e la frequenza di aggiornamento del sito Web, l'importanza delle pagine e le risorse disponibili. Alcuni siti Web potrebbero richiedere una scansione frequente per garantire l'indicizzazione delle informazioni più recenti, mentre altri potrebbero essere sottoposti a scansione meno frequentemente.
Per i siti Web ad alto traffico o con contenuti in rapida evoluzione, è essenziale una scansione più frequente per mantenere le informazioni aggiornate. D'altro canto, i siti Web più piccoli o le pagine con aggiornamenti poco frequenti possono essere scansionati meno frequentemente, riducendo il carico di lavoro e le risorse necessarie.
Crawler web interno e strumenti di scansione web
Quando si contempla la creazione di un web crawler, è fondamentale valutarne la complessità, la scalabilità e le risorse necessarie. Costruire un crawler da zero può essere un'impresa dispendiosa in termini di tempo, che comprende attività come la gestione della concorrenza, la supervisione dei sistemi distribuiti e la risoluzione degli ostacoli infrastrutturali. D’altro canto, optare per strumenti o framework di scansione web può offrire una risoluzione più rapida ed efficace.
In alternativa, l'utilizzo di strumenti o framework di scansione web può fornire una soluzione più rapida ed efficiente. Questi strumenti offrono funzionalità come regole di scansione personalizzabili, funzionalità di estrazione dei dati e opzioni di archiviazione dei dati. Sfruttando gli strumenti esistenti, gli sviluppatori possono concentrarsi sui propri requisiti specifici, come l'analisi dei dati o l'integrazione con altri sistemi.
Tuttavia, è fondamentale considerare le limitazioni e i costi associati all'utilizzo di strumenti di terze parti, come le restrizioni sulla personalizzazione, la proprietà dei dati e i potenziali modelli di prezzo.
Conclusione
I motori di ricerca fanno molto affidamento sui web crawler, che sono determinanti nel compito di organizzare e catalogare le vaste informazioni presenti su Internet. Comprendere i meccanismi, i componenti e le diverse categorie di web crawler consente una comprensione più profonda della complessa tecnologia che è alla base di questo processo fondamentale.
Sia che si scelga di costruire un web crawler da zero o di sfruttare strumenti preesistenti per la scansione web, diventa imperativo adottare un approccio in linea con le proprie esigenze specifiche. Ciò implica considerare fattori quali scalabilità, complessità e risorse a disposizione. Tenendo conto di questi elementi, puoi utilizzare in modo efficace la scansione del web per raccogliere e analizzare dati preziosi, spingendo così avanti la tua attività o le tue attività di ricerca .
Noi di PromptCloud siamo specializzati nell'estrazione di dati web, ricavando dati da risorse online disponibili al pubblico. Mettiti in contatto con noi all'indirizzo sales@promptcloud.com