
Come impedire alle IA di scansionare i tuoi contenuti
Pubblicato: 2023-10-24Gli strumenti generativi dell'intelligenza artificiale, come Google Bard e Bing Chat, sono creati da molte fonti di contenuto, incluso il Web. Con costernazione di molti, i motori di ricerca hanno silenziosamente addestrato i loro modelli di intelligenza artificiale su tutti i contenuti che trovano durante la scansione per la tradizionale ricerca sul web.
Bing e Google hanno ora annunciato metodi per bloccare l'utilizzo dei contenuti per la formazione sull'intelligenza artificiale pur rimanendo indicizzati per la ricerca web.
Quindi, dovresti bloccare le IA e come procedere?
- Dovresti bloccare le IA?
- Come si bloccano i bot IA?
- Come bloccare l'IA di Bing
- Come bloccare l'intelligenza artificiale di Google
- Come bloccare ChatGPT
- Test
Dovresti bloccare le IA?
Le aziende che realizzano i propri prodotti potrebbero considerare un vantaggio includere i propri contenuti nei modelli di intelligenza artificiale. Informazioni, come specifiche tecniche o supporto del prodotto, possono aiutare con le vendite e ridurre i costi dell'assistenza clienti.
Ma per molte altre attività online, il contenuto è il loro prodotto. Esistono fondate preoccupazioni sul fatto che l’energia investita nella creazione di contenuti verrà utilizzata per migliorare i prodotti di intelligenza artificiale di proprietà delle grandi aziende tecnologiche senza fornire alcun valore sotto forma di traffico.
Google e Bing stanno cercando di trovare modi per accreditare le fonti e fornire un po' di traffico dai referral, ma è probabile che sia inferiore a quello della ricerca web tradizionale e più probabilmente transazionale rispetto alle query di ricerca informative.
È importante notare che il blocco dei contenuti di queste IA non influirà sul comportamento di scansione. Google afferma che "il token user-agent robots.txt viene utilizzato a scopo di controllo". Il tuo sito verrà scansionato normalmente dai bot per creare i loro indici di ricerca.
E se ai motori di ricerca è già impedito di eseguire la scansione di determinate pagine, non è necessario bloccarli specificamente per gli IA.
Come si bloccano i bot IA?
Attualmente è possibile bloccare Google, Bing e ChatGPT utilizzando metodi familiari alla maggior parte dei SEO, il file robots.txt e le direttive robots a livello di pagina.
Google e ChatGPT hanno optato per il metodo robots.txt che consente di specificare pattern URL, mentre Bing ha optato per l'utilizzo delle direttive robots applicate alle singole pagine.
Il robots.txt ha il vantaggio di essere facile da configurare per un intero sito web in un unico posto. È molto trasparente quali URL vengono bloccati rispetto alle direttive dei robot a livello di pagina, che devono essere testate recuperando ogni singola pagina.
Come bloccare l'IA di Bing
Bing cerca le direttive robots nocache o noarchive, che possono essere aggiunte a una pagina come meta tag o in un'intestazione di risposta X-Robots-Tag.
Nocache consentirà di includere pagine nelle risposte di Bing Chat utilizzando solo URL, titoli e snippet nell'addestramento dei modelli AI di Microsoft.
Noarchive non consente l'inclusione di pagine in Bing Chat e nessun contenuto verrà utilizzato per addestrare i modelli di intelligenza artificiale di Microsoft.
Se una pagina ha sia Nocache che Noarchive, la Nocache meno restrittiva avrà la precedenza.
Il token " robots " applicherà la direttiva a tutti i crawler. Ciò include Google che impedirà la visualizzazione della pagina con un collegamento memorizzato nella cache nei risultati di ricerca.
<meta name=”robots” content=”noarchive”>
Puoi utilizzare i token più specifici " bingbot " o " msnbot " per evitare di influenzare altri motori di ricerca.
<meta name=”bingbot” content=”nocache”>
Come bloccare l'intelligenza artificiale di Google
Google ha optato per il metodo robots.txt che ti consente di specificare modelli URL per abbinare le pagine che non desideri vengano utilizzate in Bard e nel loro equivalente API Vertex. Al momento non si applica alla Search Generative Experience (SGE).
Corrisponderanno a un token agente utente esteso da Google. Il caso del token non ha importanza.
Agente utente: Google esteso

Non consentire: /
Se non è presente un blocco di regole specifico per il token esteso da Google, corrisponderà al token jolly (*).
Agente utente: *
Non consentire: /
Fai attenzione se disponi di un blocco di regole specifico per Googlebot e di un blocco di caratteri jolly separato. L'estensione Google corrisponderà al blocco con caratteri jolly, non al blocco Googlebot.
Agente utente: Googlebot
Permettere: /
Agente utente: *
Non consentire: /
Puoi elencare più user-agent prima che la regola si blocchi per essere più precisi.
Agente utente: Google esteso
Agente utente: Googlebot
Permettere: /
Agente utente: *
Non consentire: /
Come bloccare ChatGPT
Anche ChatGPT ha optato per il metodo robots.txt.
Chat GPT ha due diversi token user-agent, ChatGPT-User per le query per conto degli utenti ChatGPT e GPTBot, che è il web crawler di OpenAI utilizzato per creare i loro modelli.
Il sistema di opt-out attualmente tratta entrambi gli user agent allo stesso modo, quindi qualsiasi rifiuto del file robots.txt per un agente riguarderà entrambi. Ciò potrebbe cambiare in futuro, quindi ti consigliamo di bloccarli separatamente.
Agente utente: GPTBot
Agente utente: Utente ChatGPT
Non consentire: /
Test
Il test è semplice se stai bloccando l'intero sito web.
Per verificare se Google e ChatGPT sono bloccati devi vedere se il tuo robots.txt ha una regola che non consente tutto per i bot che desideri bloccare.
Agente utente: Google esteso
Agente utente: GPTbot
Non consentire: /
Se desideri bloccare solo alcuni URL, potrebbe essere necessario un set più complesso di direttive robots.txt. Potresti prendere in considerazione la possibilità di testare una serie di URL che prevedi vengano bloccati e non bloccati.
Tomo è il nostro strumento robots.txt gratuito che può aiutarti a verificare se URL specifici sono bloccati in robots.txt. È possibile definire i test sotto forma di elenco di URL e lo stato non consentito previsto per ciascun URL.
Può essere configurato con i token dell'agente utente Google-Extended, GPTBot e ChatGPT-User per mostrare quali URL sono bloccati per ciascuno e se corrisponde al risultato del test previsto.
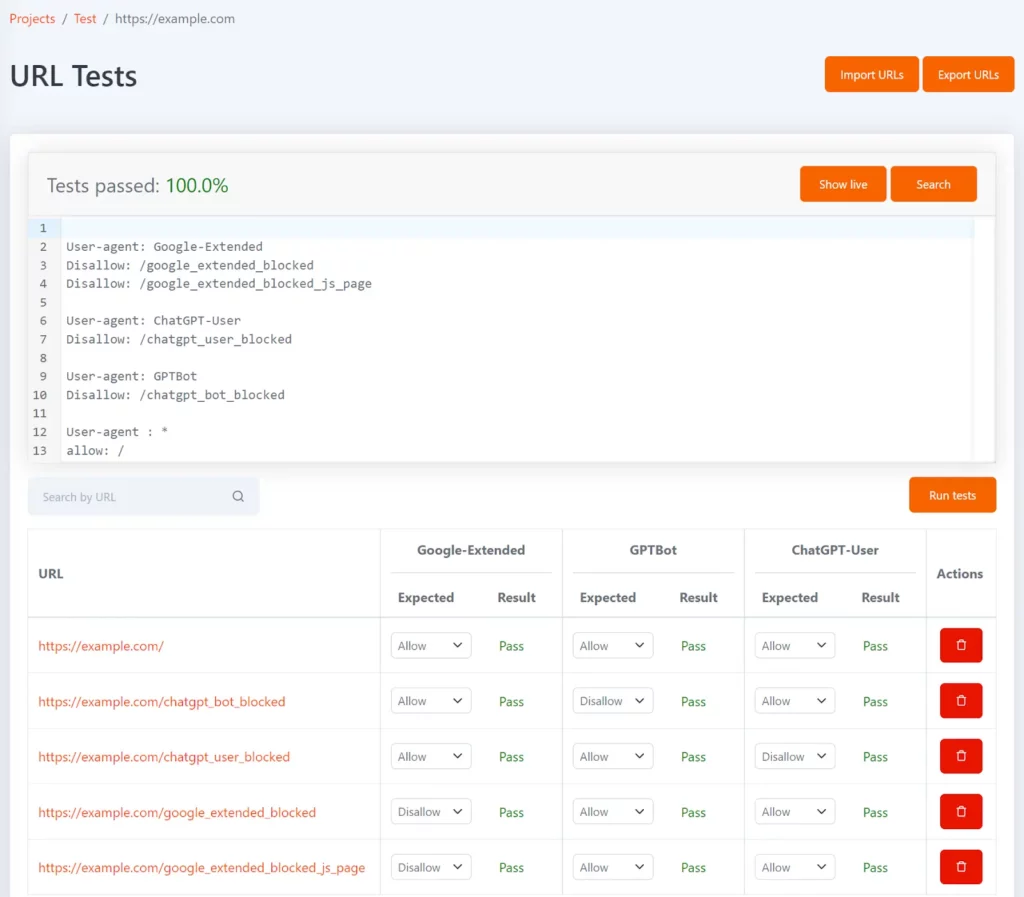
Ogni volta che il tuo file robots.txt viene aggiornato, i test verranno rieseguiti e riceverai una notifica se i risultati non corrispondono a quanto previsto.
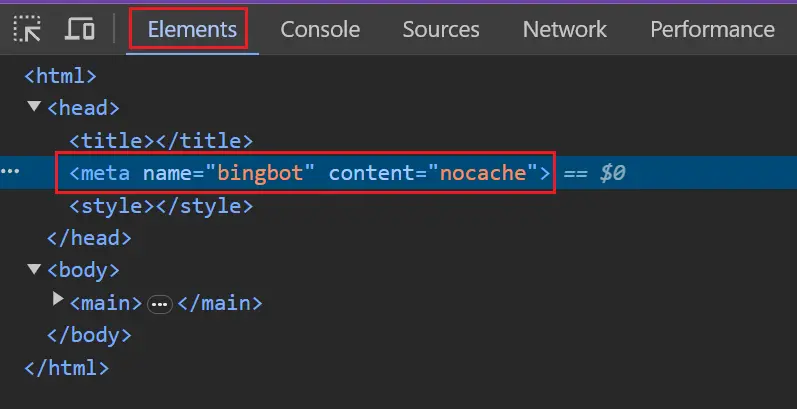
Per verificare se Bing è bloccato, puoi controllare i modelli di pagina chiave nel browser e verificare che abbiano il tag robots.
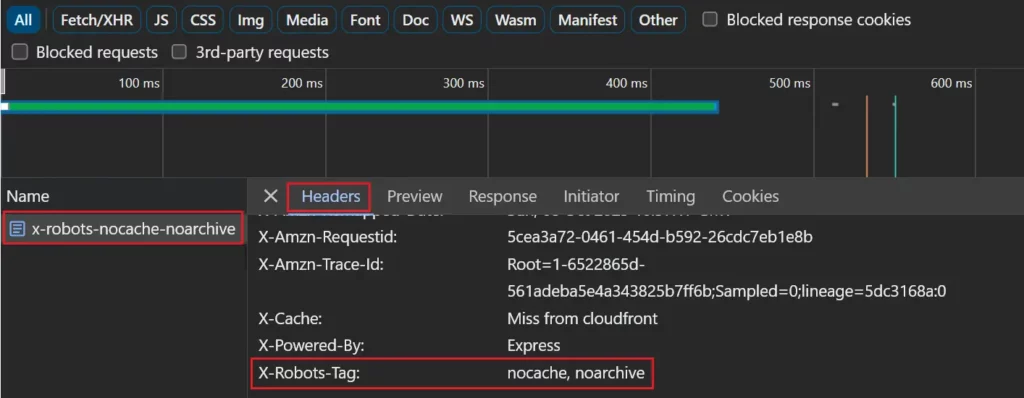
Se utilizzi un'intestazione di risposta X-Robots-Tag, puoi visualizzarla nella scheda di rete selezionando la pagina nell'elenco delle richieste di rete e visualizzando la scheda "Intestazioni".
Il test sarà più complicato se stai bloccando un insieme specifico di pagine, ma ci sono alcuni strumenti che possono aiutarti.
Il crawler Lumar ora segnalerà automaticamente anche tutte le pagine in cui gli IA di Google e Bing sono bloccati.
Hai bisogno di ulteriore supporto tecnico? Scopri di più sull'offerta tecnologica di Semetrical o contattaci per ulteriori informazioni!