
Jarvis Rising – In che modo Google potrebbe generare un modello di apprendimento automatico "al volo" per prevedere le risposte quando la Ricerca non può, e come potrebbe indicizzare quei modelli per prevedere le risposte per le query future [Br
Pubblicato: 2023-07-13
Dopo aver analizzato un brevetto di Google relativo a PAA e PASF, ho iniziato a esaminare altri brevetti concessi di recente. E non passò molto tempo prima che ne emergesse un altro molto interessante riguardante l'uso dei modelli di machine learning. Il brevetto che ho appena analizzato si concentra sull'utilizzo e/o la generazione di un modello di apprendimento automatico in risposta a una query (quando Google deve prevedere una risposta poiché i risultati di ricerca standard non potrebbero fornire una risposta adeguata). Dopo aver letto il brevetto più volte, ha sottolineato quanto possano essere sofisticati i sistemi di Google quando è necessario fornire una risposta (o una previsione) di qualità per gli utenti.
Come con qualsiasi brevetto, non sappiamo mai se Google abbia effettivamente implementato ciò che copre il brevetto, ma è sempre possibile. E se fosse implementato, non solo Google potrebbe utilizzare un modello di machine learning addestrato per aiutare a prevedere una risposta a una query, ma può indicizzare quei modelli di machine learning, associarli a varie entità, pagine web, ecc., e quindi recuperare e utilizzare tali modelli per successive ricerche correlate. Pensa a quanto può essere potente e scalabile per Google.
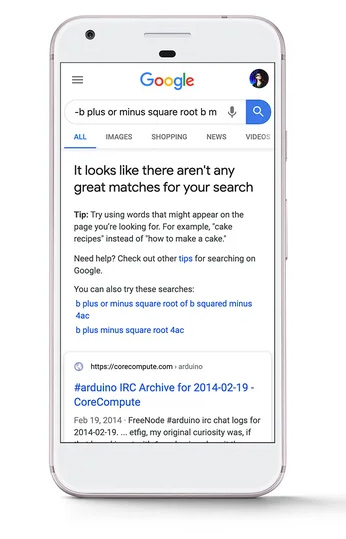
Inoltre, il brevetto spiega che Google può restituire un'interfaccia interattiva al modello di apprendimento automatico nei risultati di ricerca, che consente agli utenti di aggiungere parametri che possono essere utilizzati per generare una previsione per le query quando i risultati di ricerca non sono sufficienti. Quella parte del brevetto mi ha fatto pensare al messaggio che Google ha lanciato nelle SERP nell'aprile del 2020 quando non vengono restituiti risultati di ricerca di qualità per una query. L'attuale implementazione non fornisce un modulo con cui gli utenti possono interagire, ma potrebbe sicuramente farlo a un certo punto. E forse quell'interfaccia potrebbe essere utilizzata per più query in futuro rispetto a quelle più oscure che emerge per ora. Tratterò di più su questo nei proiettili qui sotto.
Punti chiave del brevetto:
Simile al mio ultimo post riguardante un recente brevetto di Google, penso che il modo migliore per coprire i dettagli sia fornire elenchi puntati dei punti chiave.
Generazione e/o utilizzo di un modello di apprendimento automatico in risposta a una richiesta di ricerca
USA 11645277 B2
Data concessa: 9 maggio 2023
Data deposito: 12 dicembre 2017
Nome dell'assegnatario: Google LLC
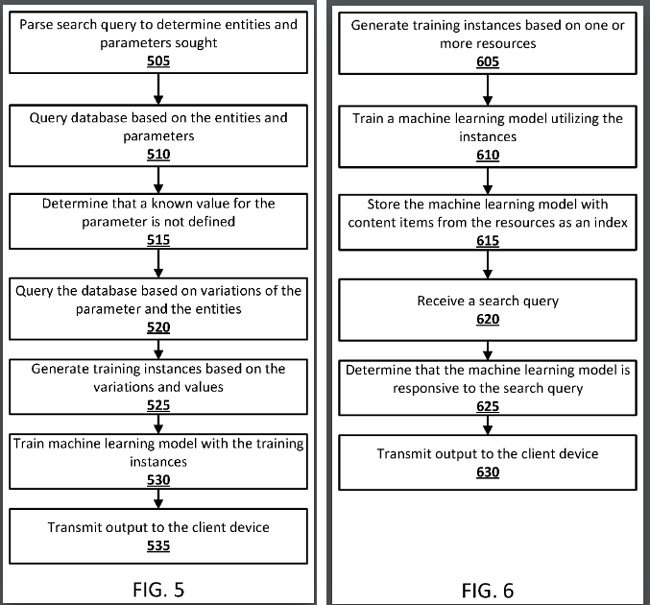
1. Il brevetto di Google spiega che se non è possibile individuare con certezza una risposta e l'utente invia una richiesta di natura predittiva, è possibile utilizzare un modello di apprendimento automatico addestrato per generare una previsione.
2. Ad esempio, Google potrebbe prima generare risultati di ricerca basati su una query, ma se i risultati non sono di qualità sufficiente, è possibile utilizzare un modello di machine learning per fornire una risposta prevista più forte. Pertanto, il sistema può fornire risposte previste basate su un modello di apprendimento automatico quando una risposta non può essere convalidata da Google.

3. Inoltre, il modello di machine learning può essere generato "al volo" e Google potrebbe archiviare modelli di machine learning addestrati in un indice di ricerca. Sì, Google potrebbe indicizzare modelli di machine learning che sono stati appena addestrati per fornire previsioni basate su specifici tipi di query. Tratterò di più su questo presto.

4. Il brevetto ha fornito un esempio basato sulla domanda "Quanti medici ci saranno in Cina nel 2050?" Se non è possibile fornire una risposta autorevole tramite i risultati di ricerca standard, la query può essere passata a un modello di machine learning addestrato per generare una previsione.

5. Il brevetto prosegue spiegando che il sistema potrebbe impiegare altri anni come 2010, 2015, 2020, ecc. e utilizzarli per generare una previsione (tramite un modello di apprendimento automatico addestrato su tali parametri).
6. Il brevetto spiega che i modelli di apprendimento automatico addestrati possono essere indicizzati da uno o più elementi di contenuto da "risorse utilizzate per addestrare il modello". E per le query future, quando il sistema identifica i parametri correlati a un modello di apprendimento automatico (ad esempio, se un utente successivo pone una domanda correlata come "Quanti medici ci saranno in Cina nel 2040 ?"), il modello di apprendimento automatico potrebbe essere utilizzato per generare una previsione.


7. Il brevetto prosegue spiegando che i modelli di apprendimento automatico potrebbero essere archiviati con uno o più elementi di contenuto, come entità in un grafico della conoscenza, nomi di tabelle, nomi di colonne, nomi di pagine Web e altro. Inoltre, le parole associate alla query come "Cina" e "dottori" potrebbero essere utilizzate dal modello di apprendimento automatico per generare una previsione.
8. Il brevetto prosegue spiegando che il sistema potrebbe fornire un'interfaccia interattiva per consentire agli utenti di selezionare i parametri che possono essere passati al modello di apprendimento automatico. Può essere un campo di testo, un menu a discesa, ecc. Inoltre, la risposta potrebbe includere un messaggio presentato all'utente che la risposta è una previsione basata su un modello di apprendimento automatico addestrato. Quindi Google vuole assicurarsi che gli utenti capiscano che si tratta di una previsione basata su un modello di apprendimento automatico rispetto alle risposte fornite in base ai dati che ha indicizzato.

9. Il modello addestrato può quindi essere convalidato per garantire che le previsioni siano almeno di una "qualità soglia". Qualunque cosa al di sotto di una certa soglia può essere soppressa e non fornita all'utente. In tal caso, è possibile visualizzare invece i risultati di ricerca standard.

10. Oltre ai risultati della ricerca pubblica, il brevetto spiega che il sistema potrebbe essere utilizzato su un database privato per aiutare le aziende a prevedere determinati risultati. Il brevetto spiega, "privato per un gruppo di utenti, una società e/o altri insiemi limitati". Ad esempio, un dipendente di un parco di divertimenti potrebbe chiedere: "quanti coni di neve venderemo domani?" Il sistema potrebbe quindi interrogare un database privato per comprendere le vendite dei giorni precedenti, le informazioni meteorologiche, i dati sulle presenze, ecc., per prevedere una risposta per il dipendente.
11. Il brevetto spiega che il sistema potrebbe fornire notifiche push da un "assistente automatico" a un certo punto. E solo pensando ad alta voce, mi chiedo se potrebbe provenire da un assistente simile a Jarvis come ho spiegato nel mio post su Code Red di Google che ha attivato migliaia di Code Red presso gli editori.

12. Dal punto di vista della latenza, il brevetto spiega che potrebbe esserci un ritardo dopo che un utente invia una query. Quando ciò accade, i risultati di ricerca standard potrebbero essere inizialmente visualizzati insieme a un messaggio che indica che i risultati "buoni" non sono disponibili per la query e che viene utilizzato un modello di apprendimento automatico per generare una previsione. In tali situazioni, il sistema potrebbe inviare tale previsione all'utente in un secondo momento o fornire un collegamento ipertestuale su cui gli utenti possono fare clic per visualizzare l'output di machine learning.
13. Inoltre, il brevetto dice per alcune situazioni che l'utente dovrebbe confermare il prompt affinché il processo continui. Ad esempio, il sistema potrebbe fornire un messaggio che indica: "Non è disponibile una buona risposta. Vuoi che ti preveda una risposta? Quindi il modello di machine learning verrebbe addestrato solo se l'input affermativo dell'utente viene ricevuto in risposta al prompt. Come ho spiegato in precedenza, vedo una connessione con il messaggio "Non ci sono grandi corrispondenze per la tua ricerca" lanciato nell'aprile del 2020. Mi chiedo se questo potrebbe espandersi per utilizzare questo modello in futuro...

Riepilogo: Google potrebbe prevedere risposte di qualità in modo potente e super efficiente tramite modelli di machine learning (indicizzati).
Anche se non sappiamo se viene utilizzato un brevetto specifico, la potenza e l'efficienza di questo processo ha molto senso per Google. Dalla generazione di modelli di apprendimento automatico "al volo" all'indicizzazione di tali modelli per un utilizzo futuro all'utilizzo di un'interfaccia interattiva con notifiche push, Google sembra preparare il terreno per un assistente come Jarvis. Quindi, la prossima volta che chiedi a Google di prevedere una risposta, pensa a questo brevetto. E a un certo punto potrebbero essere richieste ulteriori informazioni (fino a quando Jarvis non può fare tutto questo in un nanosecondo). :)
GG