
Padroneggiare gli scraper di pagine Web: una guida per principianti all'estrazione di dati online
Pubblicato: 2024-04-09Cosa sono i raschiatori di pagine Web?
Il raschietto di pagine Web è uno strumento progettato per estrarre dati dai siti Web. Simula la navigazione umana per raccogliere contenuti specifici. I principianti spesso sfruttano questi scraper per diverse attività, tra cui ricerche di mercato, monitoraggio dei prezzi e compilazione di dati per progetti di apprendimento automatico.
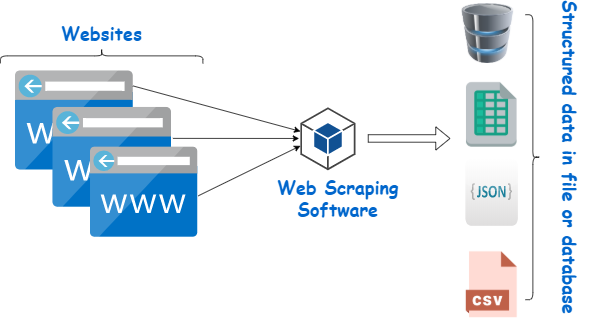
Fonte immagine: https://www.webharvy.com/articles/what-is-web-scraping.html
- Facilità d'uso: sono facili da usare e consentono a persone con competenze tecniche minime di acquisire dati web in modo efficace.
- Efficienza: gli scraper possono raccogliere rapidamente grandi quantità di dati, superando di gran lunga gli sforzi di raccolta manuale dei dati.
- Precisione: lo scraping automatizzato riduce il rischio di errore umano, migliorando la precisione dei dati.
- Conveniente: eliminano la necessità di input manuale, risparmiando tempo e costi di manodopera.
Comprendere la funzionalità degli scraper di pagine Web è fondamentale per chiunque desideri sfruttare la potenza dei dati Web.
Creazione di un semplice raschietto per pagine Web con Python
Per iniziare a creare uno scraper di pagine Web in Python, è necessario installare alcune librerie, vale a dire le richieste per effettuare richieste HTTP a una pagina Web e BeautifulSoup di bs4 per l'analisi di documenti HTML e XML.
- Strumenti di raccolta:
- Librerie: utilizza le richieste per recuperare pagine Web e BeautifulSoup per analizzare il contenuto HTML scaricato.
- Targeting della pagina Web:
- Definisci l'URL della pagina web contenente i dati che vogliamo recuperare.
- Download del contenuto:
- Utilizzando le richieste, scarica il codice HTML della pagina web.
- Analisi dell'HTML:
- BeautifulSoup trasformerà l'HTML scaricato in un formato strutturato per una facile navigazione.
- Estrazione dei dati:
- Identificare i tag HTML specifici contenenti le informazioni desiderate (ad esempio, i titoli dei prodotti all'interno dei tag <div>).
- Utilizzando i metodi BeautifulSoup, estrai ed elabora i dati di cui hai bisogno.
Ricorda di scegliere come target elementi HTML specifici pertinenti alle informazioni che desideri raccogliere.
Procedura dettagliata per lo scraping di una pagina Web
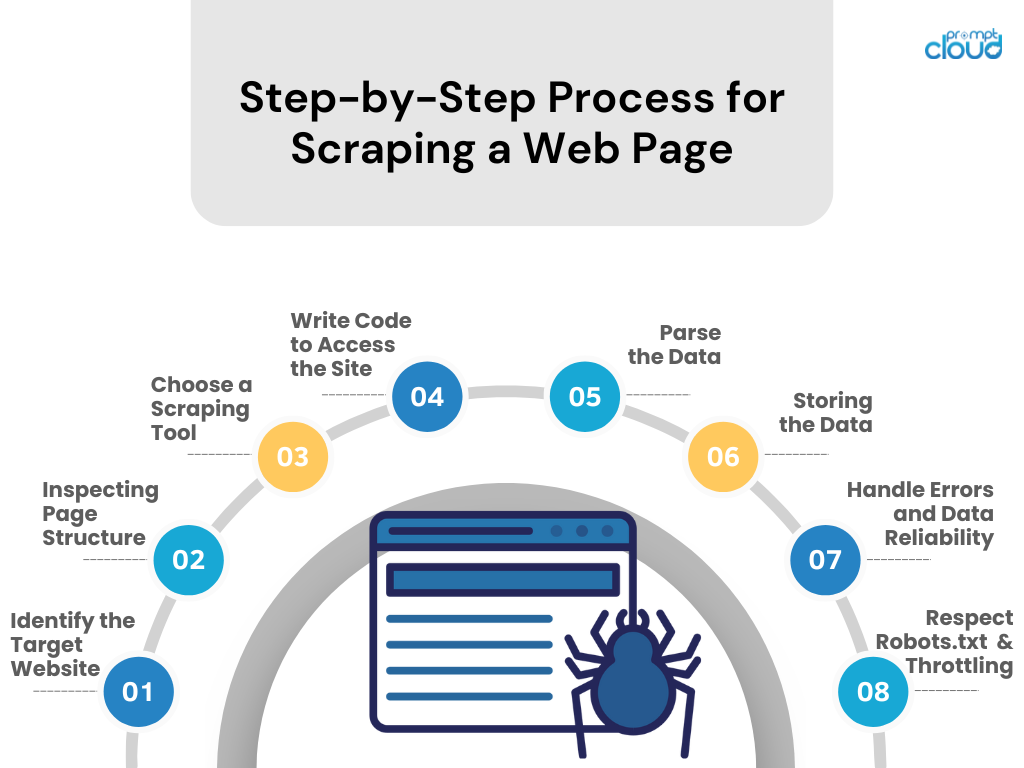
- Identificare il sito web di destinazione
Cerca il sito web che desideri raschiare. Assicurarsi che sia legale ed etico farlo. - Ispezione della struttura della pagina
Utilizza gli strumenti di sviluppo del browser per esaminare la struttura HTML, i selettori CSS e il contenuto basato su JavaScript. - Scegli uno strumento di raschiatura
Seleziona uno strumento o una libreria in un linguaggio di programmazione con cui ti senti a tuo agio (ad esempio, BeautifulSoup o Scrapy di Python). - Scrivi il codice per accedere al sito
Crea uno script che richieda dati dal sito Web, utilizzando le chiamate API se disponibili o le richieste HTTP. - Analizzare i dati
Estrai i dati rilevanti dalla pagina web analizzando HTML/CSS/JavaScript. - Memorizzazione dei dati
Salva i dati raschiati in un formato strutturato, come CSV, JSON o direttamente in un database. - Gestire gli errori e l'affidabilità dei dati
Implementare la gestione degli errori per gestire gli errori delle richieste e mantenere l'integrità dei dati. - Rispetta Robots.txt e la limitazione
Rispetta le regole del file robots.txt del sito ed evita di sovraccaricare il server controllando la frequenza delle richieste.
Selezione degli strumenti di web scraping ideali per le tue esigenze
Quando esplori il web, la selezione di strumenti in linea con le tue competenze e i tuoi obiettivi è fondamentale. I principianti dovrebbero considerare:
- Facilità d'uso: scegli strumenti intuitivi con assistenza visiva e documentazione chiara.
- Requisiti dei dati: valutare la struttura e la complessità dei dati target per determinare se è necessaria una semplice estensione o un software robusto.
- Budget: valutare il costo rispetto alle funzionalità; molti scraper efficaci offrono livelli gratuiti.
- Personalizzazione: garantire che lo strumento sia adattabile a specifiche esigenze di raschiatura.
- Supporto: l'accesso a un'utile comunità di utenti aiuta nella risoluzione dei problemi e nel miglioramento.
Scegli saggiamente per un viaggio di raschiatura senza intoppi.
Suggerimenti e trucchi per ottimizzare il raschietto delle pagine Web
- Utilizza librerie di analisi efficienti come BeautifulSoup o Lxml in Python per un'elaborazione HTML più rapida.
- Implementa la memorizzazione nella cache per evitare di scaricare nuovamente le pagine e ridurre il carico sul server.
- Rispetta i file robots.txt e utilizza la limitazione della velocità per evitare di essere bannato dal sito Web di destinazione.
- Ruota gli user agent e i server proxy per imitare il comportamento umano ed evitare il rilevamento.
- Pianifica gli scraper durante le ore non di punta per ridurre al minimo l'impatto sulle prestazioni del sito web.
- Opta per gli endpoint API, se disponibili, poiché forniscono dati strutturati e sono generalmente più efficienti.
- Evita di raccogliere dati non necessari essendo selettivo con le tue query, riducendo la larghezza di banda e lo spazio di archiviazione richiesti.
- Aggiorna regolarmente i tuoi scraper per adattarli ai cambiamenti nella struttura del sito web e mantenere l'integrità dei dati.
Gestione di problemi comuni e risoluzione dei problemi nello scraping di pagine Web
Quando si lavora con gli scraper di pagine Web, i principianti potrebbero dover affrontare diversi problemi comuni:

- Problemi con i selettori : assicurati che i selettori corrispondano alla struttura corrente della pagina web. Strumenti come gli strumenti per sviluppatori del browser possono aiutare a identificare i selettori corretti.
- Contenuto dinamico : alcune pagine Web caricano il contenuto dinamicamente con JavaScript. In questi casi, prendi in considerazione l'utilizzo di browser headless o strumenti che eseguono il rendering di JavaScript.
- Richieste bloccate : i siti Web possono bloccare gli scraper. Impiega strategie come la rotazione degli user agent, l'utilizzo di proxy e il rispetto del file robots.txt per mitigare il blocco.
- Problemi di formato dei dati : i dati estratti potrebbero richiedere pulizia o formattazione. Utilizza espressioni regolari e manipolazione di stringhe per standardizzare i dati.
Ricordarsi di consultare la documentazione e i forum della community per indicazioni specifiche sulla risoluzione dei problemi.
Conclusione
I principianti possono ora raccogliere comodamente dati dal Web tramite il raschietto delle pagine Web, rendendo la ricerca e l'analisi più efficienti. Comprendere i metodi giusti tenendo conto degli aspetti legali ed etici consente agli utenti di sfruttare tutto il potenziale del web scraping. Segui queste linee guida per un'introduzione fluida allo scraping delle pagine web, ricca di informazioni preziose e di un processo decisionale informato.
Domande frequenti:
Cos'è lo scraping di una pagina?
Il web scraping, noto anche come data scraping o web Harvesting, consiste nell'estrarre automaticamente dati da siti web utilizzando programmi informatici che imitano i comportamenti di navigazione umana. Con uno scraper per pagine web è possibile ordinare rapidamente grandi quantità di informazioni, concentrandosi esclusivamente su sezioni significative invece di compilarle manualmente.
Le aziende applicano il web scraping per funzioni quali l'esame dei costi, la gestione della reputazione, l'analisi delle tendenze e l'esecuzione di analisi della concorrenza. L'implementazione di progetti di web scraping garantisce la verifica che i siti Web visitati approvino l'azione e il rispetto di tutti i relativi protocolli robots.txt e no-follow.
Come faccio a raschiare un'intera pagina?
Per raschiare un'intera pagina web, generalmente sono necessari due componenti: un modo per individuare i dati richiesti all'interno della pagina web e un meccanismo per salvare tali dati altrove. Molti linguaggi di programmazione supportano il web scraping, in particolare Python e JavaScript.
Esistono varie librerie open source per entrambi, semplificando ulteriormente il processo. Alcune scelte popolari tra gli sviluppatori Python includono BeautifulSoup, Requests, LXML e Scrapy. In alternativa, piattaforme commerciali come ParseHub e Octoparse consentono agli utenti meno tecnici di creare visivamente complessi flussi di lavoro di web scraping. Dopo aver installato le librerie necessarie e compreso i concetti di base alla base della selezione degli elementi DOM, inizia identificando i punti dati di interesse all'interno della pagina Web di destinazione.
Utilizza gli strumenti di sviluppo del browser per ispezionare tag e attributi HTML, quindi traduci questi risultati nella sintassi corrispondente supportata dalla libreria o piattaforma scelta. Infine, specifica le preferenze del formato di output, se CSV, Excel, JSON, SQL o un'altra opzione, insieme alle destinazioni in cui risiedono i dati salvati.
Come utilizzo il raschietto di Google?
Contrariamente alla credenza popolare, Google non offre direttamente uno strumento pubblico di web scraping di per sé, nonostante fornisca API e SDK per facilitare l'integrazione perfetta con più prodotti. Ciononostante, sviluppatori esperti hanno creato soluzioni di terze parti basate sulle tecnologie principali di Google, espandendo in modo efficace le capacità oltre le funzionalità native. Gli esempi includono SerpApi, che elimina aspetti complicati di Google Search Console e presenta un'interfaccia facile da usare per il monitoraggio del posizionamento delle parole chiave, la stima del traffico organico e l'esplorazione dei backlink.
Sebbene tecnicamente distinti dal tradizionale web scraping, questi modelli ibridi sfumano le linee che separano le definizioni convenzionali. Altri casi mostrano sforzi di reverse engineering applicati alla ricostruzione della logica interna che guida Google Maps Platform, YouTube Data API v3 o Google Shopping Services, producendo funzionalità notevolmente vicine alle controparti originali sebbene soggette a vari gradi di legalità e rischi di sostenibilità. In definitiva, gli aspiranti scraper di pagine web dovrebbero esplorare diverse opzioni e valutare i meriti rispetto a requisiti specifici prima di impegnarsi in un determinato percorso.
Il raschietto di Facebook è legale?
Come indicato nelle Politiche per gli sviluppatori di Facebook, il web scraping non autorizzato costituisce una chiara violazione degli standard della community. Gli utenti accettano di non sviluppare o utilizzare applicazioni, script o altri meccanismi progettati per aggirare o superare i limiti di velocità API designati, né tentare di decifrare, decompilare o decodificare qualsiasi aspetto del Sito o del Servizio. Inoltre, evidenzia le aspettative in materia di protezione dei dati e privacy, richiedendo il consenso esplicito dell’utente prima di condividere informazioni di identificazione personale al di fuori dei contesti consentiti.
Qualsiasi inosservanza dei principi delineati innesca un'escalation di misure disciplinari che iniziano con ammonizioni e avanzano progressivamente verso l'accesso limitato o la revoca completa dei privilegi a seconda dei livelli di gravità. Nonostante le eccezioni riservate ai ricercatori di sicurezza che operano nell’ambito di programmi di bug bounty approvati, il consenso generale sostiene di evitare iniziative di scraping non autorizzate di Facebook per eludere complicazioni inutili. Considera invece la possibilità di perseguire alternative compatibili con le norme e le convenzioni prevalenti approvate dalla piattaforma.