
Crawler Web Python: tutorial passo passo
Pubblicato: 2023-12-07I web crawler sono strumenti affascinanti nel mondo della raccolta dati e del web scraping. Automatizzano il processo di navigazione sul Web per raccogliere dati, che possono essere utilizzati per vari scopi, come l'indicizzazione dei motori di ricerca, il data mining o l'analisi della concorrenza. In questo tutorial, intraprenderemo un viaggio informativo per creare un web crawler di base utilizzando Python, un linguaggio noto per la sua semplicità e potenti capacità nella gestione dei dati web.
Python, con il suo ricco ecosistema di librerie, fornisce un'eccellente piattaforma per lo sviluppo di web crawler. Che tu sia uno sviluppatore in erba, un appassionato di dati o semplicemente curioso di sapere come funzionano i web crawler, questa guida passo passo è progettata per introdurti alle nozioni di base della scansione web e fornirti le competenze necessarie per creare il tuo crawler .
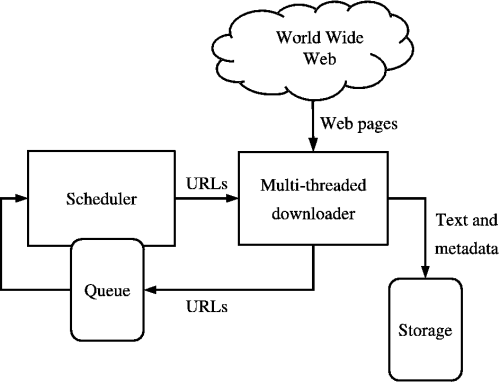
Fonte: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler – Come costruire un Web Crawler
Passaggio 1: comprendere le nozioni di base
Un web crawler, noto anche come spider, è un programma che esplora il World Wide Web in modo metodico e automatizzato. Per il nostro crawler utilizzeremo Python per la sua semplicità e le sue potenti librerie.
Passaggio 2: configura il tuo ambiente
Installa Python : assicurati di avere Python installato. Puoi scaricarlo da python.org.
Installa librerie : avrai bisogno di richieste per effettuare richieste HTTP e BeautifulSoup da bs4 per analizzare HTML. Installali usando pip:
richieste di installazione pip pip install beautifulsoup4
Passaggio 3: scrivere il crawler di base
Importa librerie :
richieste di importazione da bs4 import BeautifulSoup
Recupera una pagina Web :
Qui recupereremo il contenuto di una pagina web. Sostituisci "URL" con la pagina web di cui desideri eseguire la scansione.
url = risposta 'URL' = request.get(url) contenuto = risposta.content
Analizza il contenuto HTML :
zuppa = BeautifulSoup(content, 'html.parser')
Estrai informazioni :
Ad esempio, per estrarre tutti i collegamenti ipertestuali, puoi fare:
per il collegamento in soup.find_all('a'): print(link.get('href'))
Passaggio 4: espandi il tuo crawler
Gestione degli URL relativi :
Utilizza urljoin per gestire gli URL relativi.
da urllib.parse importa urljoin
Evitare di scansionare la stessa pagina due volte :
Mantieni una serie di URL visitati per evitare ridondanza.
Aggiunta di ritardi :
Una scansione rispettosa include ritardi tra le richieste. Usa time.sleep().
Passaggio 5: rispetta Robots.txt
Assicurati che il tuo crawler rispetti il file robots.txt dei siti web, che indica quali parti del sito non devono essere sottoposte a scansione.
Passaggio 6: gestione degli errori
Implementa blocchi try-eccetto per gestire potenziali errori come timeout di connessione o accesso negato.
Passo 7: Approfondimento
Puoi migliorare il tuo crawler per gestire attività più complesse, come l'invio di moduli o il rendering JavaScript. Per i siti Web ricchi di JavaScript, considera l'utilizzo di Selenium.
Passaggio 8: archiviare i dati
Decidi come archiviare i dati di cui hai eseguito la scansione. Le opzioni includono file semplici, database o persino l'invio diretto di dati a un server.
Passaggio 9: sii etico
- Non sovraccaricare i server; aggiungi ritardi nelle tue richieste.
- Seguire i termini di servizio del sito web.
- Non raschiare o archiviare dati personali senza autorizzazione.
Essere bloccati è una sfida comune durante la scansione del web, soprattutto quando si ha a che fare con siti Web che dispongono di misure per rilevare e bloccare l'accesso automatizzato. Ecco alcune strategie e considerazioni per aiutarti a risolvere questo problema in Python:
Capire perché vieni bloccato
Richieste frequenti: richieste rapide e ripetute dallo stesso IP possono attivare il blocco.
Modelli non umani: i bot spesso mostrano comportamenti distinti dai modelli di navigazione umani, come l’accesso alle pagine troppo velocemente o in una sequenza prevedibile.
Cattiva gestione delle intestazioni: intestazioni HTTP mancanti o errate possono far sembrare sospette le tue richieste.
Ignorare robots.txt: il mancato rispetto delle direttive nel file robots.txt di un sito può portare a blocchi.
Strategie per evitare di essere bloccati
Rispetta robots.txt : controlla e rispetta sempre il file robots.txt del sito web. È una pratica etica e può prevenire blocchi non necessari.
Agenti utente a rotazione : i siti Web possono identificarti tramite il tuo agente utente. Ruotandolo riduci il rischio di essere contrassegnato come bot. Utilizza la libreria fake_useragent per implementarlo.
from fake_useragent import UserAgent ua = UserAgent() intestazioni = {'User-Agent': ua.random}

Aggiunta di ritardi : l'implementazione di un ritardo tra le richieste può imitare il comportamento umano. Usa time.sleep() per aggiungere un ritardo casuale o fisso.
import time time.sleep(3) # Attende 3 secondi
Rotazione IP : se possibile, utilizza i servizi proxy per ruotare il tuo indirizzo IP. A questo scopo sono disponibili sia servizi gratuiti che a pagamento.
Utilizzo delle sessioni : un oggetto request.Session in Python può aiutare a mantenere una connessione coerente e condividere intestazioni, cookie, ecc. tra le richieste, facendo apparire il tuo crawler più simile a una normale sessione del browser.
con request.Session() come sessione: session.headers = {'User-Agent': ua.random} risposta = session.get(url)
Gestione di JavaScript : alcuni siti Web fanno molto affidamento su JavaScript per caricare i contenuti. Strumenti come Selenium o Puppeteer possono imitare un browser reale, incluso il rendering JavaScript.
Gestione degli errori : implementa una solida gestione degli errori per gestire e rispondere con garbo a blocchi o altri problemi.
Considerazioni etiche
- Rispetta sempre i termini di servizio di un sito web. Se un sito vieta esplicitamente il web scraping, è meglio conformarsi.
- Tieni presente l'impatto che il tuo crawler ha sulle risorse del sito web. Il sovraccarico di un server può causare problemi al proprietario del sito.
Tecniche Avanzate
- Framework di web scraping : prendi in considerazione l'utilizzo di framework come Scrapy, che dispongono di funzionalità integrate per gestire vari problemi di scansione.
- Servizi di risoluzione CAPTCHA : per i siti con sfide CAPTCHA, esistono servizi in grado di risolvere i CAPTCHA, sebbene il loro utilizzo sollevi preoccupazioni etiche.
Le migliori pratiche di scansione Web in Python
Impegnarsi in attività di web crawling richiede un equilibrio tra efficienza tecnica e responsabilità etica. Quando si utilizza Python per la scansione web, è importante aderire alle migliori pratiche che rispettino i dati e i siti Web da cui provengono. Ecco alcune considerazioni chiave e best practice per la scansione del web in Python:
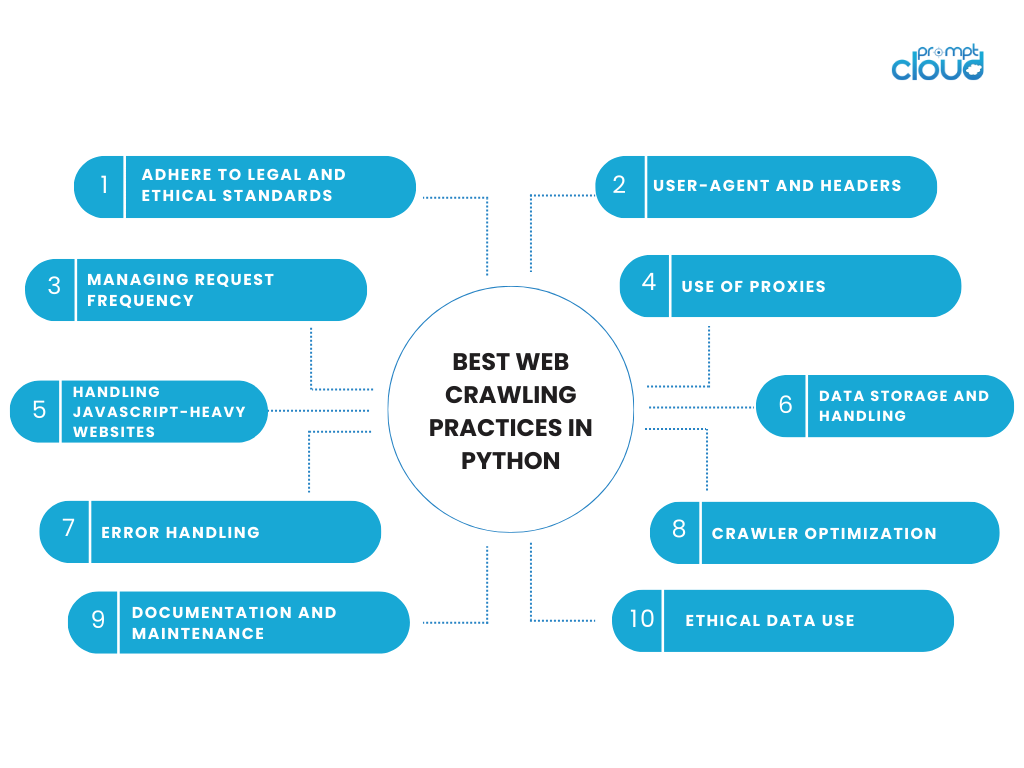
Aderire agli standard legali ed etici
- Rispetta robots.txt: controlla sempre il file robots.txt del sito web. Questo file delinea le aree del sito che il proprietario del sito preferisce non vengano sottoposte a scansione.
- Segui i Termini di servizio: molti siti Web includono clausole sul web scraping nei loro termini di servizio. Rispettare questi termini è sia etico che giuridicamente prudente.
- Evita di sovraccaricare i server: effettua le richieste a un ritmo ragionevole per evitare di caricare eccessivamente il server del sito web.
User-Agent e intestazioni
- Identificati: utilizza una stringa user-agent che includa le tue informazioni di contatto o lo scopo della scansione. Questa trasparenza può creare fiducia.
- Utilizza le intestazioni in modo appropriato: le intestazioni HTTP ben configurate possono ridurre la probabilità di essere bloccate. Possono includere informazioni come user-agent, lingua di accettazione, ecc.
Gestione della frequenza delle richieste
- Aggiungi ritardi: implementa un ritardo tra le richieste per imitare i modelli di navigazione umana. Usa la funzione time.sleep() di Python.
- Limitazione della velocità: tieni presente quante richieste invii a un sito Web entro un determinato periodo di tempo.
Utilizzo dei proxy
- Rotazione IP: l'uso dei proxy per ruotare il tuo indirizzo IP può aiutare a evitare il blocco basato su IP, ma dovrebbe essere fatto in modo responsabile ed etico.
Gestione di siti Web con uso intensivo di JavaScript
- Contenuto dinamico: per i siti che caricano il contenuto dinamicamente con JavaScript, strumenti come Selenium o Puppeteer (in combinazione con Pyppeteer per Python) possono eseguire il rendering delle pagine come un browser.
Archiviazione e gestione dei dati
- Archiviazione dei dati: archivia i dati sottoposti a scansione in modo responsabile, considerando le leggi e i regolamenti sulla privacy dei dati.
- Riduci al minimo l'estrazione dei dati: estrai solo i dati che ti servono. Evita di raccogliere informazioni personali o sensibili a meno che non sia assolutamente necessario e legale.
Gestione degli errori
- Gestione efficace degli errori: implementa una gestione completa degli errori per gestire problemi come timeout, errori del server o contenuto che non viene caricato.
Ottimizzazione del crawler
- Scalabilità: progetta il tuo crawler per gestire un aumento di scala, sia in termini di numero di pagine scansionate che di quantità di dati elaborati.
- Efficienza: ottimizza il tuo codice per l'efficienza. Un codice efficiente riduce il carico sia sul sistema che sul server di destinazione.
Documentazione e Manutenzione
- Conserva la documentazione: documenta il codice e la logica di scansione per riferimento e manutenzione futuri.
- Aggiornamenti regolari: mantieni aggiornato il codice di scansione, soprattutto se la struttura del sito Web di destinazione cambia.
Utilizzo etico dei dati
- Utilizzo etico: utilizza i dati raccolti in modo etico, rispettando la privacy dell'utente e le norme sull'utilizzo dei dati.
Insomma
Nel concludere la nostra esplorazione della creazione di un web crawler in Python, abbiamo viaggiato attraverso le complessità della raccolta automatizzata dei dati e le considerazioni etiche che ne derivano. Questo impegno non solo migliora le nostre competenze tecniche, ma approfondisce anche la nostra comprensione della gestione responsabile dei dati nel vasto panorama digitale.
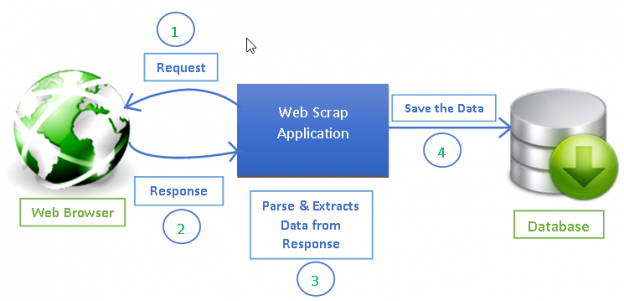
Fonte: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Tuttavia, la creazione e la manutenzione di un web crawler può essere un'attività complessa e dispendiosa in termini di tempo, soprattutto per le aziende con esigenze di dati specifiche su larga scala. È qui che entrano in gioco i servizi di web scraping personalizzati di PromptCloud. Se stai cercando una soluzione su misura, efficiente ed etica per i tuoi requisiti di dati web, PromptCloud offre una gamma di servizi per soddisfare le tue esigenze specifiche. Dalla gestione di siti Web complessi alla fornitura di dati puliti e strutturati, garantiscono che i tuoi progetti di web scraping siano semplici e allineati ai tuoi obiettivi aziendali.
Per le aziende e gli individui che potrebbero non avere il tempo o le competenze tecniche per sviluppare e gestire i propri web crawler, esternalizzare questo compito a esperti come PromptCloud può rappresentare un punto di svolta. I loro servizi non solo fanno risparmiare tempo e risorse, ma garantiscono anche che tu riceva i dati più accurati e pertinenti, il tutto rispettando gli standard legali ed etici.
Sei interessato a saperne di più su come PromptCloud può soddisfare le tue specifiche esigenze di dati? Contattali all'indirizzo sales@promptcloud.com per ulteriori informazioni e per discutere di come le loro soluzioni di web scraping personalizzate possono aiutarti a far avanzare la tua attività.
Nel dinamico mondo dei dati web, avere un partner affidabile come PromptCloud può potenziare la tua azienda, dandoti un vantaggio nel processo decisionale basato sui dati. Ricorda, nel campo della raccolta e analisi dei dati, il partner giusto fa la differenza.
Buona caccia ai dati!