
Guida dettagliata per creare un web crawler
Pubblicato: 2023-12-05Nell’intricato arazzo di Internet, dove le informazioni sono sparse su innumerevoli siti web, i web crawler emergono come eroi non celebrati, lavorando diligentemente per organizzare, indicizzare e rendere accessibile questa ricchezza di dati. Questo articolo intraprende un'esplorazione dei web crawler, facendo luce sul loro funzionamento fondamentale, distinguendo tra web crawling e web scraping e fornendo approfondimenti pratici come una guida passo passo per creare un semplice web crawler basato su Python. Man mano che approfondiamo, scopriremo le capacità di strumenti avanzati come Scrapy e scopriremo come PromptCloud eleva il web crawling su scala industriale.
Cos'è un web crawler
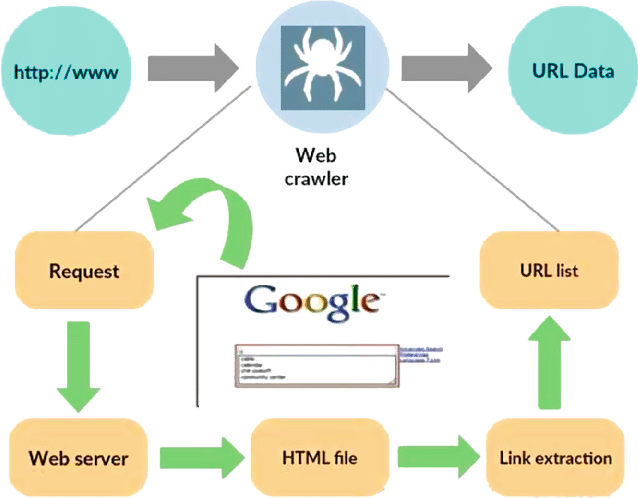
Fonte: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Un web crawler, noto anche come spider o bot, è un programma specializzato progettato per navigare in modo sistematico e autonomo nella vasta distesa del World Wide Web. La sua funzione principale è quella di esplorare siti Web, raccogliere dati e indicizzare informazioni per vari scopi, come l'ottimizzazione dei motori di ricerca, l'indicizzazione dei contenuti o l'estrazione dei dati.
Fondamentalmente, un web crawler imita le azioni di un utente umano, ma a un ritmo molto più veloce ed efficiente. Inizia il suo viaggio da un punto di partenza designato, spesso definito URL seed, e quindi segue i collegamenti ipertestuali da una pagina Web a un'altra. Questo processo di seguire i collegamenti è ricorsivo e consente al crawler di esplorare una parte significativa di Internet.
Quando il crawler visita le pagine Web, estrae e archivia sistematicamente i dati rilevanti, che possono includere testo, immagini, metadati e altro ancora. I dati estratti vengono quindi organizzati e indicizzati, rendendo più semplice per i motori di ricerca recuperare e presentare informazioni rilevanti agli utenti quando interrogati.
I web crawler svolgono un ruolo fondamentale nella funzionalità dei motori di ricerca come Google, Bing e Yahoo. Eseguendo la scansione continua e sistematica del Web, garantiscono che gli indici dei motori di ricerca siano aggiornati, fornendo agli utenti risultati di ricerca accurati e pertinenti. Inoltre, i web crawler vengono utilizzati in varie altre applicazioni, tra cui l'aggregazione di contenuti, il monitoraggio dei siti Web e il data mining.
L'efficacia di un web crawler si basa sulla sua capacità di navigare in diverse strutture di siti web, gestire contenuti dinamici e rispettare le regole stabilite dai siti web attraverso il file robots.txt, che delinea quali parti di un sito possono essere sottoposte a scansione. Comprendere come operano i web crawler è fondamentale per apprezzare la loro importanza nel rendere accessibile e organizzato il vasto web di informazioni.
Come funzionano i web crawler
I web crawler, noti anche come spider o bot, operano attraverso un processo sistematico di navigazione nel World Wide Web per raccogliere informazioni dai siti web. Ecco una panoramica di come funzionano i web crawler:
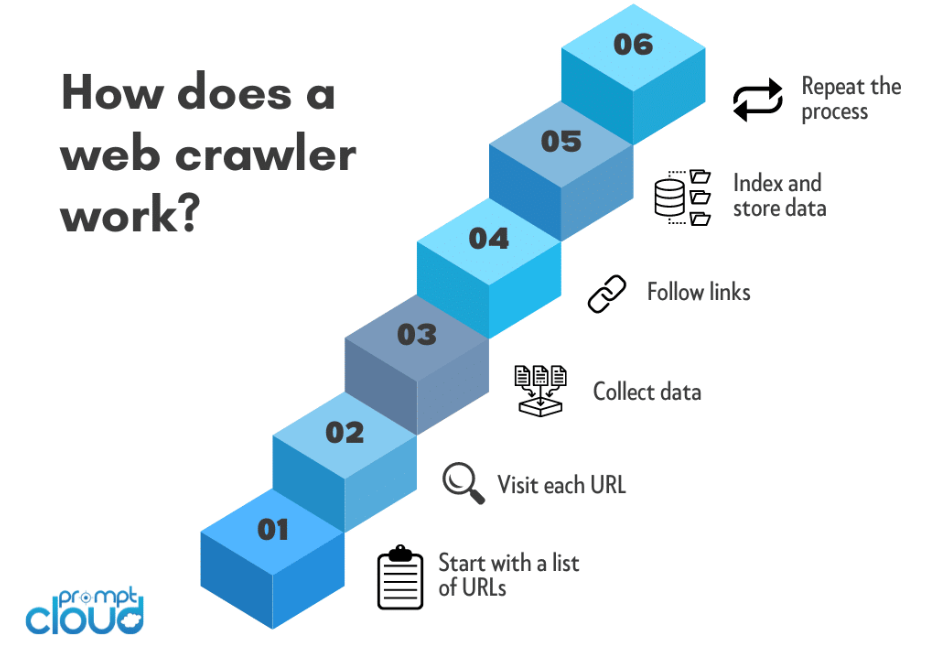
Selezione URL seme:
Il processo di scansione web inizia in genere con un URL seed. Questa è la pagina web iniziale o il sito web da cui il crawler inizia il suo viaggio.
Richiesta HTTP:
Il crawler invia una richiesta HTTP all'URL seed per recuperare il contenuto HTML della pagina web. Questa richiesta è simile alle richieste effettuate dai browser web quando si accede a un sito web.
Analisi HTML:
Una volta recuperato il contenuto HTML, il crawler lo analizza per estrarre informazioni rilevanti. Ciò comporta la scomposizione del codice HTML in un formato strutturato che il crawler può navigare e analizzare.
Estrazione URL:
Il crawler identifica ed estrae i collegamenti ipertestuali (URL) presenti nel contenuto HTML. Questi URL rappresentano collegamenti ad altre pagine che il crawler visiterà successivamente.
Coda e pianificazione:
Gli URL estratti vengono aggiunti a una coda o a uno scheduler. La coda garantisce che il crawler visiti gli URL in un ordine specifico, spesso dando priorità agli URL nuovi o non visitati.
Ricorsione:
Il crawler segue i collegamenti in coda, ripetendo il processo di invio di richieste HTTP, analisi del contenuto HTML ed estrazione di nuovi URL. Questo processo ricorsivo consente al crawler di navigare attraverso più livelli di pagine web.
Estrazione dati:
Mentre il crawler attraversa il Web, estrae dati rilevanti da ciascuna pagina visitata. Il tipo di dati estratti dipende dallo scopo del crawler e può includere testo, immagini, metadati o altri contenuti specifici.
Indicizzazione dei contenuti:
I dati raccolti sono organizzati e indicizzati. L'indicizzazione implica la creazione di un database strutturato che semplifichi la ricerca, il recupero e la presentazione delle informazioni quando gli utenti inviano query.
Rispettando Robots.txt:
I web crawler in genere aderiscono alle regole specificate nel file robots.txt di un sito web. Questo file fornisce linee guida su quali aree del sito possono essere sottoposte a scansione e quali dovrebbero essere escluse.
Ritardi e cortesia nella scansione:
Per evitare di sovraccaricare i server e causare interruzioni, i crawler spesso incorporano meccanismi per ritardi e cortesia nella scansione. Queste misure garantiscono che il crawler interagisca con i siti web in modo rispettoso e non distruttivo.
I web crawler navigano sistematicamente sul web, seguendo i link, estraendo dati e costruendo un indice organizzato. Questo processo consente ai motori di ricerca di fornire risultati accurati e pertinenti agli utenti in base alle loro query, rendendo i web crawler una componente fondamentale del moderno ecosistema Internet.

Scansione Web e Web Scraping

Fonte: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Sebbene il web crawling e il web scraping siano spesso usati in modo intercambiabile, hanno scopi distinti. Il web crawling implica la navigazione sistematica del web per indicizzare e raccogliere informazioni, mentre il web scraping si concentra sull'estrazione di dati specifici dalle pagine web. In sostanza, il web crawling riguarda l'esplorazione e la mappatura del web, mentre il web scraping riguarda la raccolta di informazioni mirate.
Costruire un web crawler
La creazione di un semplice web crawler in Python prevede diversi passaggi, dalla configurazione dell'ambiente di sviluppo alla codifica della logica del crawler. Di seguito è riportata una guida dettagliata per aiutarti a creare un web crawler di base utilizzando Python, utilizzando la libreria delle richieste per effettuare richieste HTTP e BeautifulSoup per l'analisi HTML.
Passaggio 1: impostare l'ambiente
Assicurati di avere Python installato sul tuo sistema. Puoi scaricarlo da python.org. Inoltre, dovrai installare le librerie richieste:
pip install requests beautifulsoup4
Passaggio 2: importare librerie
Crea un nuovo file Python (ad esempio, simple_crawler.py) e importa le librerie necessarie:
import requests from bs4 import BeautifulSoup
Passaggio 3: definire la funzione crawler
Crea una funzione che accetta un URL come input, invia una richiesta HTTP ed estrae informazioni rilevanti dal contenuto HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Passaggio 4: testare il crawler
Fornisci un URL di esempio e chiama la funzione simple_crawler per testare il crawler:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Passaggio 5: esegui il crawler
Esegui lo script Python nel terminale o nel prompt dei comandi:
python simple_crawler.py
Il crawler recupererà il contenuto HTML dell'URL fornito, lo analizzerà e stamperà il titolo. Puoi espandere il crawler aggiungendo più funzionalità per estrarre diversi tipi di dati.
Scansione del Web con Scrapy
Il web crawling con Scrapy apre le porte a un framework potente e flessibile progettato specificamente per uno scraping web efficiente e scalabile. Scrapy semplifica le complessità della creazione di web crawler, offrendo un ambiente strutturato per la creazione di spider in grado di navigare nei siti Web, estrarre dati e archiviarli in modo sistematico. Ecco uno sguardo più da vicino alla scansione del web con Scrapy:
Installazione:
Prima di iniziare, assicurati di avere installato Scrapy. Puoi installarlo usando:
pip install scrapy
Creazione di un progetto Scrapy:
Avvia un progetto Scrapy:
Apri un terminale e vai alla directory in cui desideri creare il tuo progetto Scrapy. Esegui il seguente comando:
scrapy startproject your_project_name
Questo crea una struttura di progetto di base con i file necessari.
Definisci il ragno:
All'interno della directory del progetto, vai alla cartella spiders e crea un file Python per il tuo spider. Definisci una classe spider creando una sottoclasse scrapy.Spider e fornendo dettagli essenziali come nome, domini consentiti e URL di avvio.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Estrazione dei dati:
Utilizzo dei selettori:
Scrapy utilizza potenti selettori per estrarre dati da HTML. È possibile definire selettori nel metodo di analisi dello spider per acquisire elementi specifici.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
Questo esempio estrae il contenuto testuale del tag <title>.
Seguenti link:
Scrapy semplifica il processo di seguire i collegamenti. Utilizzare il metodo Segui per navigare verso altre pagine.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Esecuzione del ragno:
Esegui il tuo spider utilizzando il seguente comando dalla directory del progetto:
scrapy crawl your_spider
Scrapy avvierà lo spider, seguirà i collegamenti ed eseguirà la logica di analisi definita nel metodo parse.
La scansione del Web con Scrapy offre un framework robusto ed estensibile per la gestione di attività di scraping complesse. La sua architettura modulare e le funzionalità integrate lo rendono la scelta preferita per gli sviluppatori impegnati in sofisticati progetti di estrazione di dati web.
Scansione Web su larga scala
La scansione del Web su larga scala presenta sfide uniche, soprattutto quando si ha a che fare con una grande quantità di dati sparsi su numerosi siti Web. PromptCloud è una piattaforma specializzata progettata per semplificare e ottimizzare il processo di scansione del web su larga scala. Ecco come PromptCloud può assisterti nella gestione di iniziative di scansione web su larga scala:
- Scalabilità
- Estrazione e arricchimento dei dati
- Qualità e accuratezza dei dati
- Gestione delle infrastrutture
- Facilità d'uso
- Conformità ed etica
- Monitoraggio e reporting in tempo reale
- Supporto e manutenzione
PromptCloud è una soluzione solida per organizzazioni e individui che desiderano condurre la scansione del web su larga scala. Affrontando le principali sfide associate all'estrazione di dati su larga scala, la piattaforma migliora l'efficienza, l'affidabilità e la gestibilità delle iniziative di web crawling.
In sintesi
I web crawler rappresentano gli eroi non celebrati nel vasto panorama digitale, navigando diligentemente nel web per indicizzare, raccogliere e organizzare le informazioni. Man mano che la portata dei progetti di web crawling si espande, PromptCloud interviene come soluzione, offrendo scalabilità, arricchimento dei dati e conformità etica per semplificare iniziative su larga scala. Mettiti in contatto con noi all'indirizzo sales@promptcloud.com