
Il ruolo del Web Scraping nel miglioramento della precisione del modello AI
Pubblicato: 2023-12-27L’intelligenza artificiale è in continua evoluzione, alimentata dagli immensi dati necessari per perfezionare l’apprendimento automatico. Questo processo di apprendimento implica il riconoscimento di modelli e il prendere decisioni informate.
Entra nel web scraping: un attore vitale nella ricerca dei dati. Si tratta di estrarre vaste informazioni dai siti Web, un tesoro per l’addestramento dei modelli di intelligenza artificiale. L’armonia tra intelligenza artificiale e web scraping sottolinea l’essenza basata sui dati dell’apprendimento automatico contemporaneo. Con il progredire dell’intelligenza artificiale, aumenta la fame di set di dati diversificati, rendendo il web scraping una risorsa indispensabile per gli sviluppatori che creano sistemi di intelligenza artificiale più nitidi ed efficienti.
L'evoluzione del Web Scraping: dal manuale all'intelligenza artificiale
Lo sviluppo del web scraping rispecchia i progressi tecnologici. I primi metodi erano basilari e richiedevano l’estrazione manuale dei dati, un’attività spesso dispendiosa in termini di tempo e soggetta a errori. Con la rapida espansione di Internet, queste tecniche non riuscivano a tenere il passo con il crescente volume di dati. Sono stati introdotti script e robot per automatizzare lo scraping, ma mancavano di sofisticatezza.
Entra nell'intelligenza artificiale del web scraping, rivoluzionando la raccolta dei dati. L’apprendimento automatico ora consente l’analisi di dati complessi e non strutturati, dandone un senso in modo efficiente. Questo cambiamento non solo accelera la raccolta dei dati, ma migliora anche la qualità dei dati estratti, consentendo applicazioni più sofisticate e fornendo un terreno più ricco per i modelli di intelligenza artificiale che imparano continuamente da set di dati vasti e sfumati.
Fonte immagine: https://www.scrapingdog.com/
Comprendere le tecnologie AI nel Web Scraping
Grazie all’intelligenza artificiale, gli strumenti di web scraping sono diventati più potenti. L’intelligenza artificiale automatizza il riconoscimento dei modelli nell’estrazione dei dati, rendendo più veloce e precisa l’identificazione delle informazioni rilevanti. I web scraper basati sull'intelligenza artificiale possono:
- Adattati a diversi layout di siti web utilizzando l'apprendimento automatico, riducendo così la necessità di progettare modelli manualmente.
- Impiega l'elaborazione del linguaggio naturale (NLP) per comprendere e classificare i dati basati su testo, migliorando la qualità dei dati raccolti.
- Utilizza le funzionalità di riconoscimento delle immagini per estrarre contenuti visivi, che possono essere fondamentali in determinati contesti di analisi dei dati.
- Implementare algoritmi di rilevamento delle anomalie per identificare e gestire valori anomali o errori di estrazione dei dati, garantendo l'integrità dei dati.
Con la potenza dell'intelligenza artificiale, il web scraping diventa più forte e più adattabile, soddisfacendo i vasti requisiti di dati dei modelli di intelligenza artificiale avanzati di oggi.
Il ruolo dell'apprendimento automatico nell'estrazione intelligente dei dati
L'apprendimento automatico rivoluziona l'estrazione dei dati consentendo ai sistemi di riconoscere, comprendere ed estrarre in modo indipendente le informazioni rilevanti. I contributi chiave includono:
- Riconoscimento di modelli : gli algoritmi di apprendimento automatico eccellono nel riconoscere modelli e anomalie in set di dati di grandi dimensioni, rendendoli ideali per identificare punti dati rilevanti durante il web scraping.
- Elaborazione del linguaggio naturale (NLP) : utilizzando la PNL, l'apprendimento automatico può comprendere e interpretare il linguaggio umano, facilitando l'estrazione di informazioni da fonti di dati non strutturate come i social media.
- Apprendimento adattivo : man mano che i modelli di machine learning sono esposti a più dati, apprendono e migliorano la loro precisione, garantendo che il processo di estrazione dei dati diventi più efficiente nel tempo.
- Riduzione dell’errore umano : con l’apprendimento automatico, la probabilità di errori associati all’estrazione manuale dei dati è significativamente ridotta, migliorando la qualità del set di dati per i modelli IA.
Fonte immagine: https://research.aimultiple.com/
Riconoscimento dei modelli basato sull'intelligenza artificiale per una raschiatura efficiente
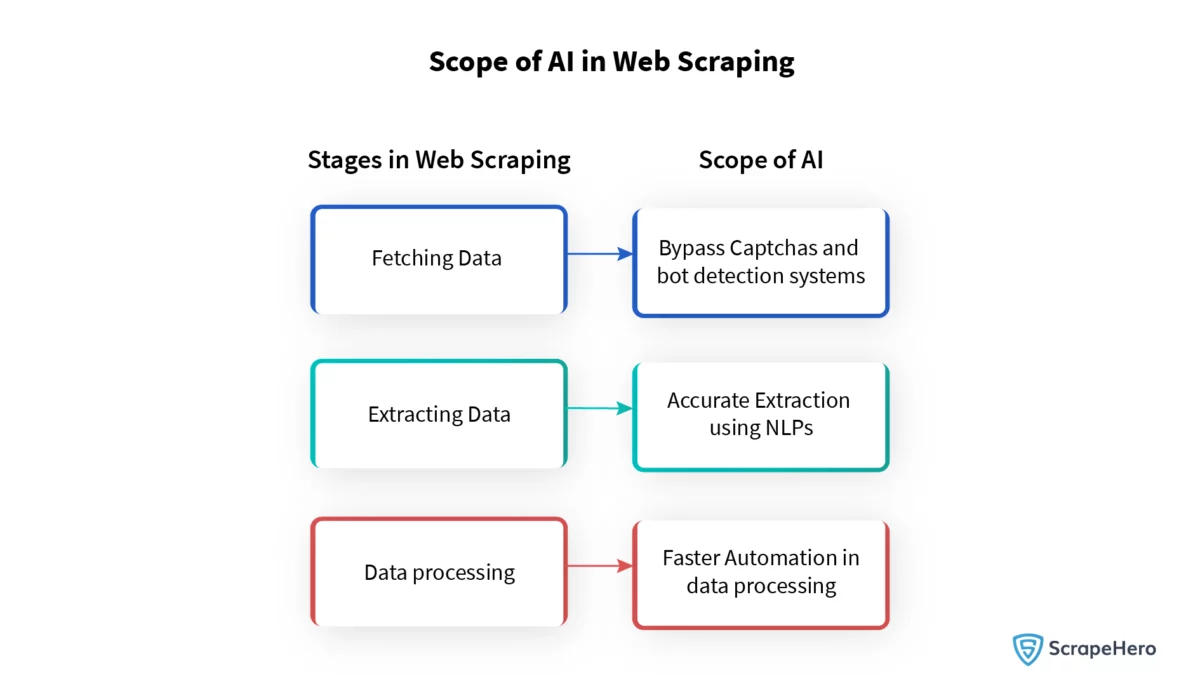
Il web scraping svolge un ruolo fondamentale nel soddisfare la crescente domanda di dati nei modelli di machine learning. In prima linea c’è il riconoscimento di modelli basato sull’intelligenza artificiale, che semplifica l’estrazione dei dati con notevole efficienza. Questa tecnica avanzata identifica e classifica grandi quantità di dati con un coinvolgimento umano minimo.
Sfruttando algoritmi complessi, l'intelligenza artificiale del web scraping naviga rapidamente attraverso le pagine web, riconoscendo modelli ed estraendo set di dati strutturati. Questi sistemi automatizzati non solo funzionano più velocemente ma migliorano anche significativamente la precisione, riducendo al minimo gli errori rispetto ai metodi di raschiatura manuale. Con l’evoluzione dell’intelligenza artificiale, la sua capacità di discernere schemi complessi continuerà a rimodellare il panorama del web scraping e dell’acquisizione di dati.
Elaborazione del linguaggio naturale per l'aggregazione dei contenuti
La funzione cruciale dell’elaborazione del linguaggio naturale (NLP) viene in primo piano nell’aggregazione dei contenuti, consentendo ai sistemi di intelligenza artificiale di comprendere, interpretare e organizzare in modo efficiente i dati. Fornisce agli scraper la capacità di discernere le informazioni rilevanti dalle chiacchiere irrilevanti. Analizzando la semantica e la sintattica del testo, la PNL classifica il contenuto, estrae le entità chiave e riassume le informazioni.

Questi dati distillati diventano il materiale di formazione fondamentale per i modelli che imparano a riconoscere modelli, anticipare le domande degli utenti e fornire risposte approfondite. Di conseguenza, l’aggregazione dei contenuti basata sulla PNL è fondamentale nello sviluppo di modelli di intelligenza artificiale più intelligenti e consapevoli del contesto. Facilita un approccio mirato nella raccolta dei dati, perfezionando l’input grezzo che alimenta l’insaziabile appetito di dati dell’intelligenza artificiale contemporanea.
Superare i captcha e le sfide dei contenuti dinamici con l'intelligenza artificiale
I captcha e i contenuti dinamici rappresentano barriere formidabili per un efficace web scraping. Questi meccanismi sono progettati per distinguere tra utenti umani e servizi automatizzati, spesso interrompendo gli sforzi di raccolta dei dati. Tuttavia, i progressi nel campo dell’intelligenza artificiale hanno introdotto soluzioni sofisticate:
- Gli algoritmi di machine learning sono migliorati significativamente nell’interpretazione dei captcha visivi, imitando le capacità umane di riconoscimento dei modelli.
- Gli strumenti basati sull’intelligenza artificiale possono ora adattarsi ai contenuti dinamici apprendendo le strutture delle pagine e prevedendo i cambiamenti nella posizione dei dati.
- Alcuni sistemi utilizzano Generative Adversarial Networks (GAN) per addestrare modelli in grado di risolvere captcha complessi.
- Le tecniche di elaborazione del linguaggio naturale (NLP) aiutano a comprendere la semantica dietro i testi generati dinamicamente, facilitando l'estrazione accurata dei dati.
Mentre si svolge la lotta in corso tra i creatori di captcha e gli sviluppatori di intelligenza artificiale, ogni passo avanti nella tecnologia captcha è contrastato da una contromisura più astuta e agile guidata dall’intelligenza artificiale. Questa interazione dinamica garantisce un flusso continuo di dati, alimentando l’incessante espansione del settore dell’intelligenza artificiale.
Migliorare la qualità e l'accuratezza dei dati attraverso la potenza delle applicazioni IA
Le applicazioni di intelligenza artificiale (AI) migliorano significativamente la qualità e l'accuratezza dei dati, fondamentali per la formazione di modelli efficaci. Utilizzando algoritmi sofisticati, l’intelligenza artificiale può:
- Rileva e correggi le incoerenze in set di dati di grandi dimensioni.
- Filtra le informazioni irrilevanti, concentrandoti su sottoinsiemi di dati vitali per la comprensione del modello.
- Convalidare i dati rispetto a parametri di qualità prestabiliti.
- Esegui la pulizia dei dati in tempo reale, garantendo che i set di dati di addestramento rimangano aggiornati e accurati.
- Utilizza l'apprendimento non supervisionato per identificare modelli o anomalie che potrebbero sfuggire al controllo umano.
L'uso dell'intelligenza artificiale nella preparazione dei dati non solo rende il processo più fluido; eleva la qualità delle informazioni ottenute dai dati, dando vita a modelli di intelligenza artificiale più intelligenti e affidabili.
Ampliare le operazioni di web scraping con l'integrazione dell'intelligenza artificiale
L’integrazione dell’intelligenza artificiale nelle pratiche di web scraping migliora significativamente l’efficienza e la scalabilità dei processi di raccolta dati. I sistemi basati sull’intelligenza artificiale possono adattarsi a diversi layout di siti Web ed estrarre i dati in modo accurato, anche se il sito subisce modifiche. Questa adattabilità deriva da algoritmi di apprendimento automatico che apprendono da modelli e anomalie durante il processo di scraping.
Inoltre, l’intelligenza artificiale può dare priorità e classificare i punti dati, riconoscendo rapidamente informazioni preziose. Le competenze di elaborazione del linguaggio naturale (NLP) consentono di acquisire strumenti per comprendere ed elaborare il linguaggio umano, consentendo così l'estrazione di sentimenti o intenzioni dai dati testuali. Man mano che i lavori di scraping aumentano in complessità e volume, l’integrazione dell’intelligenza artificiale garantisce che queste attività vengano eseguite con una supervisione manuale ridotta, portando a un’operazione più snella ed economicamente vantaggiosa. L’implementazione di tali sistemi intelligenti facilita:
- Automatizzare l'identificazione e l'estrazione dei dati rilevanti
- Apprendimento continuo e adattamento alle nuove strutture web
- Analisi e interpretazione di dati non strutturati con tecniche NLP
- Migliorare la precisione e ridurre la necessità di intervento umano
Prossime tendenze: il panorama futuro del Web Scraping AI
Mentre navighiamo nel regno in continua evoluzione dell’intelligenza artificiale, emerge un punto focale sui notevoli progressi nell’intelligenza artificiale del web scraping. Esplora queste tendenze cruciali che plasmano il futuro:
- Comprensione completa: l'intelligenza artificiale si espande per comprendere video, immagini e audio contestualmente.
- Apprendimento adattivo: l'intelligenza artificiale adatta le strategie di scraping in base alle strutture dei siti Web, riducendo l'intervento umano.
- Estrazione precisa dei dati: gli algoritmi sono ottimizzati per un'estrazione dei dati accurata e pertinente.
- Integrazione perfetta: gli strumenti di scraping basati sull'intelligenza artificiale si integrano perfettamente con le piattaforme di analisi dei dati.
- Acquisizione etica dei dati: l’intelligenza artificiale incorpora linee guida etiche per il consenso degli utenti e la protezione dei dati.
Fonte immagine: https://www.scrapehero.com/
Sperimenta la sinergia del web scraping e dell'intelligenza artificiale per le tue esigenze di dati. Contatta PromptCloud all'indirizzo sales@promptcloud.com per servizi di web scraping all'avanguardia che migliorano la precisione dei tuoi modelli di intelligenza artificiale.
Domande frequenti:
L’intelligenza artificiale può eseguire il web scraping?
Certamente, l’intelligenza artificiale è abile nel gestire gli incarichi di web scraping. Dotati di algoritmi avanzati, i sistemi di intelligenza artificiale possono attraversare in modo indipendente i siti Web, identificare modelli ed estrarre dati pertinenti con notevole efficienza. Questa capacità segna un progresso significativo, amplificando la rapidità, la precisione e la flessibilità delle procedure di estrazione dei dati.
Il web scraping è illegale?
Quando si tratta della legalità del web scraping, il panorama è ricco di sfumature. Il web scraping in sé non è di per sé illegale, ma la legalità dipende da come viene eseguito. Uno scraping responsabile ed etico, in linea con i termini di servizio dei siti Web presi di mira, è fondamentale per evitare complicazioni legali. È essenziale avvicinarsi al web scraping con una mentalità consapevole e conforme.
ChatGPT può eseguire il web scraping?
Per quanto riguarda ChatGPT, non svolge attività di web scraping. Il suo punto di forza risiede nella comprensione e nella generazione del linguaggio naturale, fornendo risposte basate sull'input che riceve. Per le attività effettive di web scraping sono necessari strumenti specializzati e programmazione.
Quanto costa l'IA del raschietto?
Quando si considera il costo dei servizi di intelligenza artificiale di scraper, è importante tenere conto di variabili come la complessità dell'attività di scraping, il volume di dati da estrarre e le specifiche esigenze di personalizzazione. I modelli di prezzo possono includere tariffe una tantum, piani di abbonamento o tariffe basate sull'utilizzo. Per un preventivo personalizzato su misura per le tue esigenze, è consigliabile contattare un fornitore di servizi di web scraping come PromptCloud.