
Comprensione dell'architettura GPU per l'ottimizzazione dell'inferenza LLM
Pubblicato: 2024-04-02Introduzione ai LLM e all'importanza dell'ottimizzazione della GPU
Nell'era odierna dei progressi dell'elaborazione del linguaggio naturale (NLP), i Large Language Models (LLM) sono emersi come potenti strumenti per una miriade di attività, dalla generazione di testo alla risposta alle domande e al riepilogo. Questi sono più di un probabile generatore di token. Tuttavia, la crescente complessità e dimensione di questi modelli pone sfide significative in termini di efficienza e prestazioni computazionali.
In questo blog approfondiamo le complessità dell'architettura GPU, esplorando il modo in cui i diversi componenti contribuiscono all'inferenza LLM. Discuteremo i parametri chiave delle prestazioni, come la larghezza di banda della memoria e l'utilizzo del tensor core, e illustreremo le differenze tra le varie schede GPU, consentendoti di prendere decisioni informate quando selezioni l'hardware per le tue attività di modelli linguistici di grandi dimensioni.
In un panorama in rapida evoluzione in cui le attività di PNL richiedono risorse computazionali sempre maggiori, l'ottimizzazione del throughput di inferenza LLM è fondamentale. Unisciti a noi mentre intraprendiamo questo viaggio per sbloccare tutto il potenziale degli LLM attraverso tecniche di ottimizzazione della GPU e approfondire vari strumenti che ci consentono di migliorare efficacemente le prestazioni.
Elementi essenziali dell'architettura GPU per LLM: conosci i componenti interni della GPU
Data la natura di esecuzione di calcoli paralleli altamente efficienti, le GPU diventano il dispositivo preferito per eseguire tutte le attività di deep learning, quindi è importante comprendere la panoramica di alto livello dell'architettura GPU per comprendere i colli di bottiglia sottostanti che si presentano durante la fase di inferenza. Le schede Nvidia sono preferite grazie a CUDA (Compute Unified Device Architecture), una piattaforma di elaborazione parallela proprietaria e un'API sviluppata da NVIDIA, che consente agli sviluppatori di specificare il parallelismo a livello di thread nel linguaggio di programmazione C, fornendo accesso diretto al set di istruzioni virtuali della GPU e al parallelo elementi computazionali.
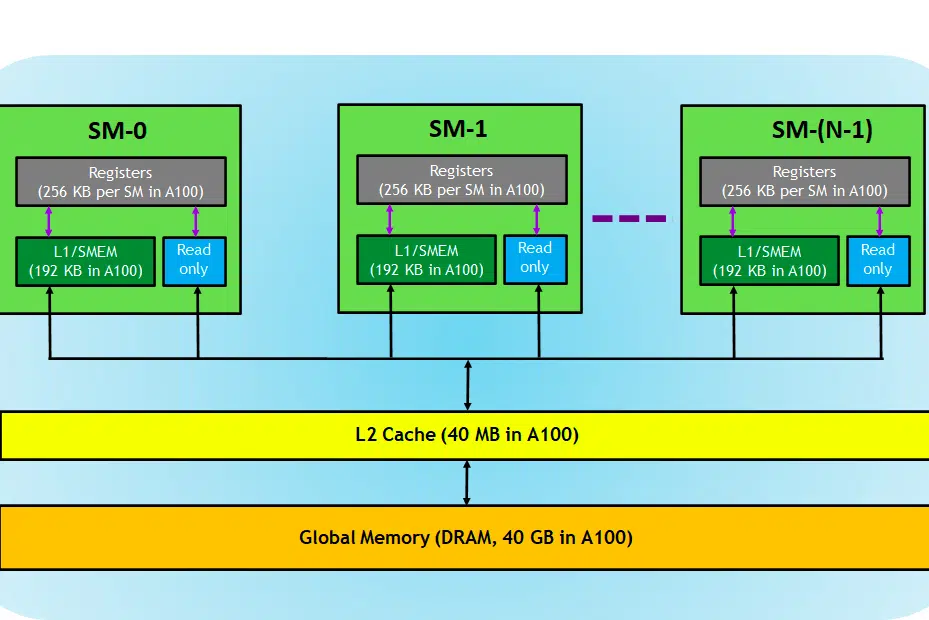
Per il contesto, abbiamo utilizzato una scheda NVIDIA come spiegazione perché è ampiamente preferita per le attività di deep learning, come già affermato e pochi altri termini come Tensor Core sono applicabili a questo.
Diamo un'occhiata alla scheda GPU, qui nell'immagine possiamo vedere tre parti principali e (un'altra parte nascosta principale) di un dispositivo GPU
- SM (streaming multiprocessore)
- Cache L2
- Banda di memoria
- Memoria globale (DRAM)
Proprio come la tua CPU-RAM gioca insieme, la RAM è il luogo in cui risiedono i dati (cioè la memoria) e la CPU per le attività di elaborazione (cioè il processo). In una GPU, la memoria globale a larghezza di banda elevata (DRAM) contiene i pesi del modello (ad esempio LLAMA 7B) che vengono caricati in memoria e, quando necessario, questi pesi vengono trasferiti all'unità di elaborazione (ad esempio il processore SM) per i calcoli.
Streaming multiprocessore
Un multiprocessore di streaming o SM è una raccolta di unità di esecuzione più piccole chiamate CUDA core (piattaforma di elaborazione parallela proprietaria di NVIDIA), insieme a unità funzionali aggiuntive responsabili del recupero, della decodifica, della pianificazione e dell'invio delle istruzioni. Ogni SM opera in modo indipendente e contiene il proprio file di registro, memoria condivisa, cache L1 e unità texture. Gli SM sono altamente parallelizzati, consentendo loro di elaborare migliaia di thread contemporaneamente, il che è essenziale per ottenere un throughput elevato nelle attività di elaborazione GPU. Le prestazioni del processore sono generalmente misurate in FLOPS, il n. di operazioni mobili che può eseguire ogni secondo.
Le attività di deep learning consistono principalmente in operazioni tensoriali, ovvero moltiplicazione matrice-matrice. NVIDIA ha introdotto i core tensoriali nelle GPU di nuova generazione, progettati specificamente per eseguire queste operazioni tensoriali in modo altamente efficiente. Come accennato, i tensor core sono utili quando si tratta di attività di deep learning e invece dei CUDA core, dobbiamo controllare i tensor core per determinare con quanta efficienza una GPU può eseguire l'addestramento/l'inferenza di LLM.
Cache L2
La cache L2 è una memoria a larghezza di banda elevata condivisa tra SM con lo scopo di ottimizzare l'accesso alla memoria e l'efficienza del trasferimento dei dati all'interno del sistema. È un tipo di memoria più piccolo e più veloce che risiede più vicino alle unità di elaborazione (come i multiprocessori di streaming) rispetto alla DRAM. Aiuta a migliorare l'efficienza complessiva dell'accesso alla memoria riducendo la necessità di accedere alla DRAM più lenta per ogni richiesta di memoria.
Banda di memoria
Quindi, le prestazioni dipendono da quanto velocemente possiamo trasferire i pesi dalla memoria al processore e da quanto efficientemente e velocemente il processore può elaborare i calcoli dati.
Quando la capacità di calcolo è superiore/più veloce della velocità di trasferimento dati tra la memoria e l'SM, l'SM non avrà più dati da elaborare e quindi l'elaborazione sarà sottoutilizzata. Questa situazione in cui la larghezza di banda della memoria è inferiore alla velocità di consumo è nota come fase legata alla memoria. . Questo è molto importante da notare poiché questo è il collo di bottiglia prevalente nel processo di inferenza.
Al contrario, se il calcolo impiega più tempo per l'elaborazione e se più dati vengono accodati per il calcolo, questo stato è una fase legata al calcolo .
Per sfruttare appieno la GPU, dobbiamo essere in uno stato vincolato al calcolo mentre si eseguono i calcoli nel modo più efficiente possibile.
Memoria DRAM
La DRAM funge da memoria primaria in una GPU, fornendo un ampio pool di memoria per l'archiviazione di dati e istruzioni necessarie per il calcolo. Solitamente è organizzato in una gerarchia, con più banchi di memoria e canali per consentire l'accesso ad alta velocità.

Per l'attività di inferenza, la DRAM della GPU determina quanto è grande un modello che possiamo caricare e i FLOPS di calcolo e la larghezza di banda determinano il throughput che possiamo ottenere.
Confronto delle schede GPU per attività LLM
Per ottenere informazioni sul numero dei tensor core e sulla velocità della larghezza di banda, è possibile consultare il whitepaper rilasciato dal produttore della GPU. Ecco un esempio,
| RTX A6000 | RTX4090 | RTX3090 | |
| Dimensione della memoria | 48GB | 24GB | 24GB |
| Tipo di memoria | GDDR6 | GDDR6X | |
| Larghezza di banda | 768,0 GB/sec | 1008GB/sec | 936,2 GB/sec |
| CUDA Core/GPU | 10752 | 16384 | 10496 |
| Nuclei tensoriali | 336 | 512 | 328 |
| Cache L1 | 128 KB (per SM) | 128 KB (per SM) | 128 KB (per SM) |
| FP16 Non tensore | 38,71 TFLOP (1:1) | 82.6 | 35,58 TFLOP (1:1) |
| FP32 Non tensore | 38,71 TFLOP | 82.6 | 35,58 TFLOP |
| FP64 Non tensore | 1.210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| Picco TFLOPS del tensore FP16 con accumulo FP16 | 154.8/309.6 | 330.3/660.6 | 142/284 |
| Picco TFLOPS del tensore FP16 con accumulo FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| Picco BF16 Tensore TFLOPS con FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| Picco TF32 Tensore TFLOPS | 77.4/154.8 | 82.6/165.2 | 35,6/71 |
| Tensore di picco INT8 TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| Tensore di picco INT4 TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| Cache L2 | 6 MB | 72MB | 6MB |
| Bus della memoria | 384 bit | 384 bit | 384 bit |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| Conteggio SM | 84 | 128 | 82 |
| Nuclei RT | 84 | 128 | 82 |
Qui possiamo vedere che FLOPS è menzionato specificamente per le operazioni Tensor, questi dati ci aiuteranno a confrontare le diverse schede GPU e a selezionare quella adatta al nostro caso d'uso. Dalla tabella, sebbene l'A6000 abbia il doppio della memoria del 4090, i tensore flop e la larghezza di banda della memoria del 4090 sono migliori in termini numerici e quindi più potenti per l'inferenza dei modelli linguistici di grandi dimensioni.
Ulteriori informazioni: Nvidia CUDA in 100 secondi
Conclusione
Nel campo in rapido progresso della PNL, l’ottimizzazione dei Large Language Models (LLM) per compiti di inferenza è diventata un’area critica di interesse. Come abbiamo esplorato, l'architettura delle GPU gioca un ruolo fondamentale nel raggiungimento di prestazioni elevate ed efficienza in queste attività. Comprendere i componenti interni delle GPU, come Streaming Multiprocessors (SM), cache L2, larghezza di banda della memoria e DRAM, è essenziale per identificare i potenziali colli di bottiglia nei processi di inferenza LLM.
Il confronto tra le diverse schede GPU NVIDIA (RTX A6000, RTX 4090 e RTX 3090) rivela differenze significative in termini di dimensione della memoria, larghezza di banda e numero di CUDA e Tensor Core, tra gli altri fattori. Queste distinzioni sono fondamentali per prendere decisioni informate su quale GPU è più adatta per attività LLM specifiche. Ad esempio, mentre l'RTX A6000 offre una dimensione di memoria maggiore, l'RTX 4090 eccelle in termini di Tensor FLOPS e larghezza di banda della memoria, rendendola una scelta più potente per attività di inferenza LLM impegnative.
L'ottimizzazione dell'inferenza LLM richiede un approccio equilibrato che consideri sia la capacità computazionale della GPU sia i requisiti specifici dell'attività LLM in questione. Selezionare la GPU giusta implica comprendere i compromessi tra capacità di memoria, potenza di elaborazione e larghezza di banda per garantire che la GPU possa gestire in modo efficiente i pesi del modello ed eseguire calcoli senza diventare un collo di bottiglia. Poiché il campo della PNL continua ad evolversi, rimanere informati sulle ultime tecnologie GPU e sulle loro capacità sarà fondamentale per coloro che desiderano ampliare i confini di ciò che è possibile con i modelli linguistici di grandi dimensioni.
Terminologia utilizzata
- Portata:
In caso di inferenza, il throughput è la misura di quante richieste/prompt vengono elaborate per un dato periodo di tempo. La produttività viene generalmente misurata in due modi:
- Richieste al secondo (RPS) :
- RPS misura il numero di richieste di inferenza che un modello può gestire in un secondo. Una richiesta di inferenza implica in genere la generazione di una risposta o previsione basata sui dati di input.
- Per la generazione LLM, RPS indica la velocità con cui il modello può rispondere alle richieste o alle query in arrivo. Valori RPS più elevati suggeriscono una migliore reattività e scalabilità per le applicazioni in tempo reale o quasi in tempo reale.
- Il raggiungimento di valori RPS elevati spesso richiede strategie di distribuzione efficienti, come l'unione di più richieste per ammortizzare i costi generali e massimizzare l'utilizzo delle risorse computazionali.
- Gettoni al secondo (TPS) :
- TPS misura la velocità con cui un modello può elaborare e generare token (parole o sottoparole) durante la generazione del testo.
- Nel contesto della generazione LLM, TPS riflette la velocità effettiva del modello in termini di generazione di testo. Indica quanto velocemente il modello può produrre risposte coerenti e significative.
- Valori TPS più elevati implicano una generazione di testo più rapida, consentendo al modello di elaborare più dati di input e generare risposte più lunghe in un determinato periodo di tempo.
- Il raggiungimento di valori TPS elevati spesso implica l’ottimizzazione dell’architettura del modello, la parallelizzazione dei calcoli e lo sfruttamento di acceleratori hardware come le GPU per accelerare la generazione di token.
- Latenza:
La latenza negli LLM si riferisce al ritardo temporale tra input e output durante l'inferenza. Ridurre al minimo la latenza è essenziale per migliorare l'esperienza dell'utente e consentire interazioni in tempo reale nelle applicazioni che sfruttano gli LLM. È essenziale trovare un equilibrio tra throughput e latenza in base al servizio che dobbiamo fornire. Una bassa latenza è auspicabile per casi quali chatbot/copiloti con interazione in tempo reale, ma non è necessaria per casi di elaborazione di dati in massa come la rielaborazione interna dei dati.
Scopri di più sulle tecniche avanzate per migliorare il throughput LLM qui.