
Come caricare dati su BigQuery con R e Python
Pubblicato: 2023-06-06Il mondo dell'analisi dei dati web continua a precipitare verso la fatidica data del 1° luglio, quando Universal Analytics interrompe l'elaborazione dei dati e viene sostituita da Google Analytics 4 (GA4). Una delle modifiche principali è che in GA4 è possibile conservare i dati nella piattaforma solo per un massimo di 14 mesi. Si tratta di un cambiamento importante rispetto a UA, ma in cambio di ciò, puoi inserire gratuitamente i dati GA4 in BigQuery, fino a un certo limite.
BigQuery è una risorsa estremamente utile per l'archiviazione dei dati oltre GA4. Dato che sta diventando più importante che mai in pochi mesi, è il momento migliore che mai per iniziare a usarlo per tutte le tue esigenze di archiviazione dei dati. Spesso sarà preferibile manipolare i dati in qualche modo prima del caricamento. Per questo, consigliamo di utilizzare uno script scritto in R o in Python, soprattutto se questo tipo di manipolazione deve essere eseguito ripetutamente. Puoi anche caricare i dati in BigQuery direttamente da questi script, ed è esattamente ciò che questo blog ti guiderà.
Caricamento in BigQuery da R
R è un linguaggio estremamente potente per la scienza dei dati e il più facile da usare per caricare i dati in BigQuery. Il primo passo è importare tutte le librerie necessarie. Per questo tutorial, avremo bisogno delle seguenti librerie:
library(googleAuthR)
library(bigQueryR)
Se non hai mai usato queste librerie prima, esegui install.packages(<PACKAGE NAME>) nella console per installarle.
Successivamente, dobbiamo affrontare quella che è spesso la parte più complicata e costantemente più frustrante del lavoro con le API: l'autorizzazione. Fortunatamente, con R, questo è relativamente semplice. Avrai bisogno di un file JSON contenente le credenziali di autorizzazione. Questo può essere trovato in Google Cloud Console, lo stesso posto in cui si trova BigQuery. Innanzitutto, accedi a Google Cloud Console e fai clic su "API e servizi".
Successivamente, fai clic su "Credenziali" nella barra laterale.
Nella pagina Credenziali, puoi visualizzare le chiavi API esistenti, gli ID client OAuth 2.0 e gli account di servizio. Avrai bisogno di un ID client OAuth 2.0 per questo, quindi premi il pulsante di download alla fine della riga pertinente per il tuo ID o crea un nuovo ID facendo clic su "Crea credenziali" nella parte superiore della pagina. Assicurati che il tuo ID sia autorizzato a visualizzare e modificare il progetto BigQuery pertinente: a tale scopo, apri la barra laterale, passa il mouse su "IAM e amministrazione" e fai clic su "IAM". In questa pagina puoi concedere al tuo account di servizio l'accesso al progetto pertinente utilizzando il pulsante "Concedi accesso" nella parte superiore della pagina.
Con il file JSON ottenuto e salvato, puoi passargli il percorso con la funzione gar_set_client() per impostare le tue credenziali. Il codice completo per l'autorizzazione è di seguito:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Ovviamente, vorrai sostituire il percorso nella funzione gar_set_client() con il percorso del tuo file JSON e inserire l'indirizzo email che utilizzi per accedere a BigQuery nella funzione bqr_auth().
Una volta configurata l'autorizzazione, abbiamo bisogno di alcuni dati da caricare in BigQuery. Dovremo inserire questi dati in un dataframe. Ai fini di questo articolo, creerò alcuni dati fittizi con un numero di posizioni e conteggi delle vendite, ma molto probabilmente leggerai dati reali da un file .csv o da un foglio di calcolo. Per leggere i dati da un file .csv, puoi semplicemente utilizzare la funzione read.csv(), passando come argomento il percorso del file:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
In alternativa, se i tuoi dati sono archiviati in un foglio di calcolo, il tuo metodo varierà a seconda di dove si trova questo foglio di calcolo. Se il tuo foglio di lavoro è archiviato in Fogli Google, puoi leggerne i dati in R utilizzando la libreria googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Come prima, se non hai mai utilizzato questo pacchetto prima, dovrai eseguire install.packages(“googlesheets4”) nella console prima di eseguire il tuo codice.
Se il tuo foglio di calcolo è in Excel, dovrai utilizzare la libreria readxl, che fa parte della libreria tidyverse, qualcosa che consiglio di utilizzare. Contiene un numero enorme di funzioni che rendono la manipolazione dei dati in R molto più semplice:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
E ancora una volta, assicurati di eseguire install.package(“tidyverse”) se non l'hai mai fatto prima!
Il passaggio finale consiste nel caricare i dati in BigQuery. Per questo, avrai bisogno di un posto in BigQuery per caricarlo. La tua tabella si troverà all'interno di un set di dati, che si troverà all'interno di un progetto, e avrai bisogno dei nomi di tutti e tre questi nel seguente formato:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
Nel mio caso, questo significa che il mio codice legge:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Se la tua tabella non esiste ancora, non ti preoccupare, il codice la creerà per te. Non dimenticare di inserire i nomi del tuo progetto, set di dati e tabella nel codice sopra (tra virgolette) e assicurati di caricare il frame di dati corretto! Una volta fatto ciò, dovresti vedere i tuoi dati in BigQuery, come di seguito:

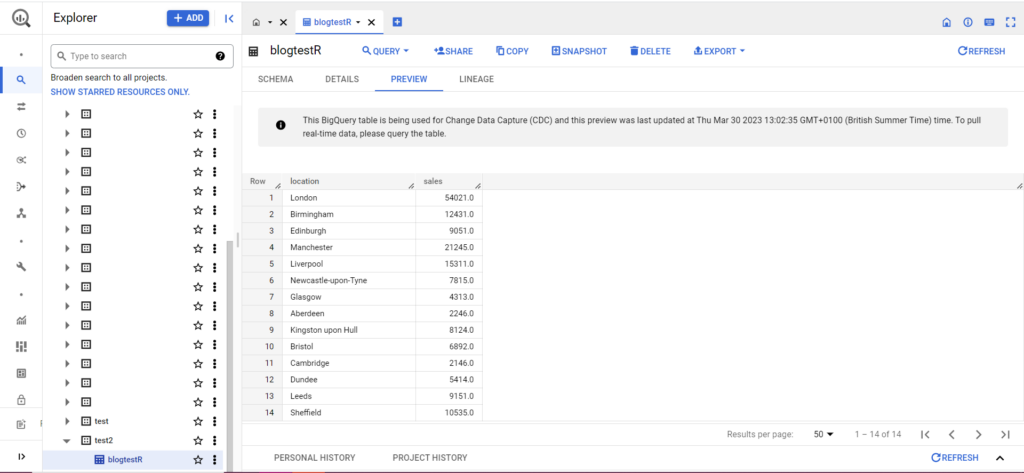
Come passaggio finale, supponiamo che tu disponga di ulteriori dati che desideri aggiungere a BigQuery. Ad esempio, nei miei dati sopra, diciamo che ho dimenticato di includere un paio di località dal continente e voglio caricare su BigQuery, ma non voglio sovrascrivere i dati esistenti. Per questo, bqr_upload_data ha un parametro chiamato writeDisposition. writeDisposition ha due impostazioni, "WRITE_TRUNCATE" e "WRITE_APPEND". Il primo dice a bqr_upload_data() di sovrascrivere i dati esistenti nella tabella, mentre il secondo gli dice di aggiungere i nuovi dati. Quindi, per caricare questi nuovi dati, scriverò:
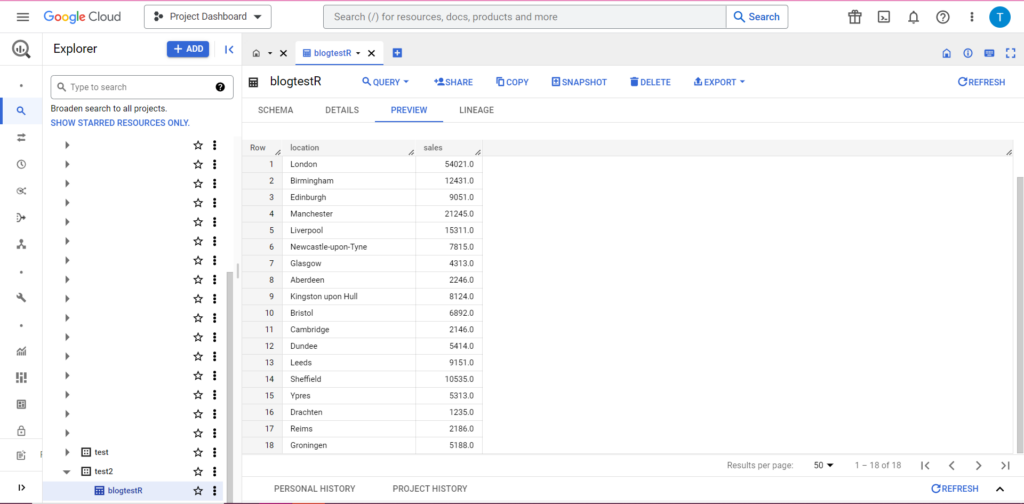
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
E infatti, in BigQuery possiamo vedere che i nostri dati hanno alcuni nuovi coinquilini:
Caricamento in BigQuery da Python
In Python, le cose sono leggermente diverse. Ancora una volta, avremo bisogno di importare alcuni pacchetti, quindi iniziamo con questi:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
L'autorizzazione è complicata. Ancora una volta avremo bisogno di un file JSON contenente le credenziali. Come sopra, andremo a Google Cloud Console e faremo clic su "API e servizi", quindi faremo clic su "Credenziali" nella barra laterale. Questa volta, in fondo alla pagina, ci sarà una sezione chiamata "Account di servizio".
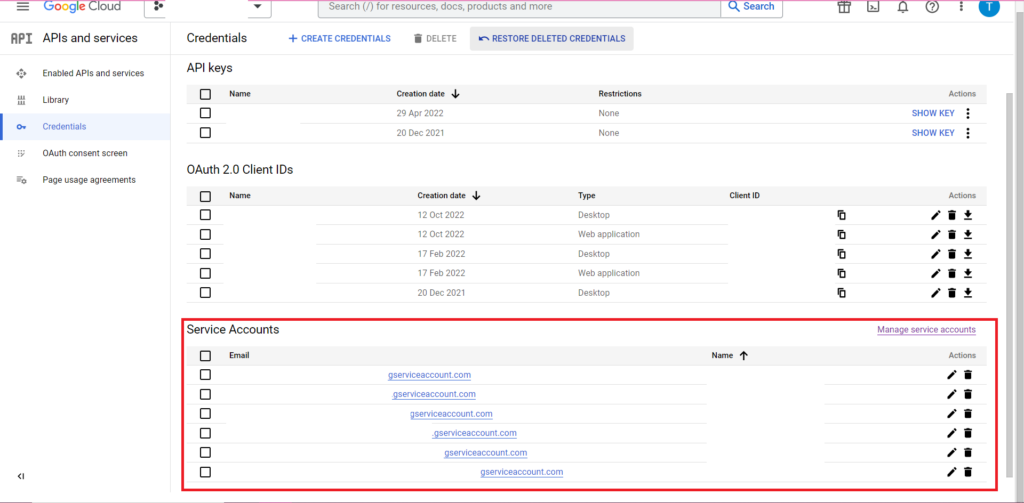
Lì puoi scaricare la chiave sul tuo account di servizio oppure, facendo clic su "Gestisci account di servizio", puoi creare una nuova chiave o un nuovo account di servizio per il quale puoi scaricare le credenziali.
Dovrai quindi assicurarti che il tuo account di servizio disponga dell'autorizzazione per accedere e modificare il tuo progetto BigQuery. Ancora una volta, vai alla pagina IAM in "IAM e amministrazione" nella barra laterale e lì puoi concedere al tuo account di servizio l'accesso al progetto pertinente utilizzando il pulsante "Concedi accesso" nella parte superiore della pagina.
Non appena hai risolto, puoi scrivere il codice di autorizzazione:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Successivamente, dovrai inserire i tuoi dati in un dataframe. I dataframe appartengono al pacchetto pandas e sono molto semplici da creare. Per leggere da un CSV, segui questo esempio:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Ovviamente, dovrai sostituire il percorso sopra con quello del tuo file CSV. Per leggere da un file Excel, seguire questo esempio:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Leggere da Fogli Google è complicato e richiede un altro giro di autorizzazione. Dovremo importare alcuni nuovi pacchetti e utilizzare il file delle credenziali JSON che abbiamo recuperato durante l'esercitazione R precedente. Puoi seguire questo codice per autorizzare e leggere i tuoi dati:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Una volta che hai i tuoi dati nel tuo dataframe, è il momento di caricare di nuovo su BigQuery! Puoi farlo seguendo questo modello:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Ad esempio, ecco il codice che ho appena scritto per caricare i dati che ho creato in precedenza:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Fatto ciò, i dati dovrebbero apparire immediatamente in BigQuery!
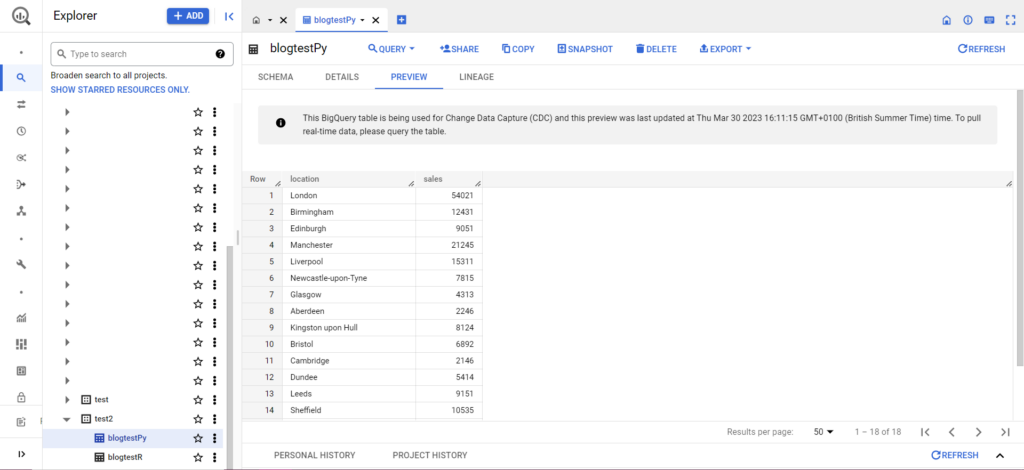
C'è molto di più che puoi fare con queste funzioni una volta che hai imparato a usarle. Se vuoi avere un maggiore controllo sulla tua configurazione di analisi, Semetrical è qui per aiutarti! Consulta il nostro blog per ulteriori informazioni su come ottenere il massimo dai tuoi dati. Oppure, per ulteriore supporto su tutto ciò che riguarda l'analisi, visita Web Analytics per scoprire come possiamo aiutarti.