
Web crawler: una guida completa
Pubblicato: 2023-12-12Scansione del Web
Il web crawling, un processo fondamentale nel campo dell'indicizzazione del web e della tecnologia dei motori di ricerca, si riferisce alla navigazione automatizzata del World Wide Web da parte di un programma software noto come web crawler. Questi crawler, a volte chiamati spider o bot, navigano sistematicamente sul web per raccogliere informazioni dai siti web. Questo processo consente la raccolta e l'indicizzazione dei dati, che è fondamentale affinché i motori di ricerca forniscano risultati di ricerca aggiornati e pertinenti.
Funzioni chiave della scansione web:
- Indicizzazione del contenuto : i web crawler scansionano le pagine web e ne indicizzano il contenuto, rendendolo ricercabile. Questo processo di indicizzazione prevede l'analisi del testo, delle immagini e di altri contenuti di una pagina per comprenderne l'argomento.
- Analisi dei collegamenti : i crawler seguono i collegamenti da una pagina Web all'altra. Questo non solo aiuta a scoprire nuove pagine web, ma anche a comprendere le relazioni e la gerarchia tra le diverse pagine web.
- Rilevamento degli aggiornamenti dei contenuti : rivisitando regolarmente le pagine Web, i crawler possono rilevare aggiornamenti e modifiche, garantendo che il contenuto indicizzato rimanga aggiornato.
La nostra guida passo passo alla creazione di un web crawler ti aiuterà a comprendere meglio il processo di scansione web.
Cos'è un web crawler
Un web crawler, noto anche come spider o bot, è un programma software automatizzato che esplora sistematicamente il World Wide Web allo scopo di indicizzare il web. La sua funzione principale è scansionare e indicizzare il contenuto delle pagine Web, che include testo, immagini e altri media. I web crawler partono da un insieme noto di pagine web e seguono i collegamenti su queste pagine per scoprire nuove pagine, agendo in modo molto simile a una persona che naviga sul web. Questo processo consente ai motori di ricerca di raccogliere e aggiornare i propri dati, garantendo che gli utenti ricevano risultati di ricerca aggiornati e completi. Il funzionamento efficiente dei web crawler è essenziale per mantenere accessibile e ricercabile il vasto e sempre crescente archivio di informazioni online.
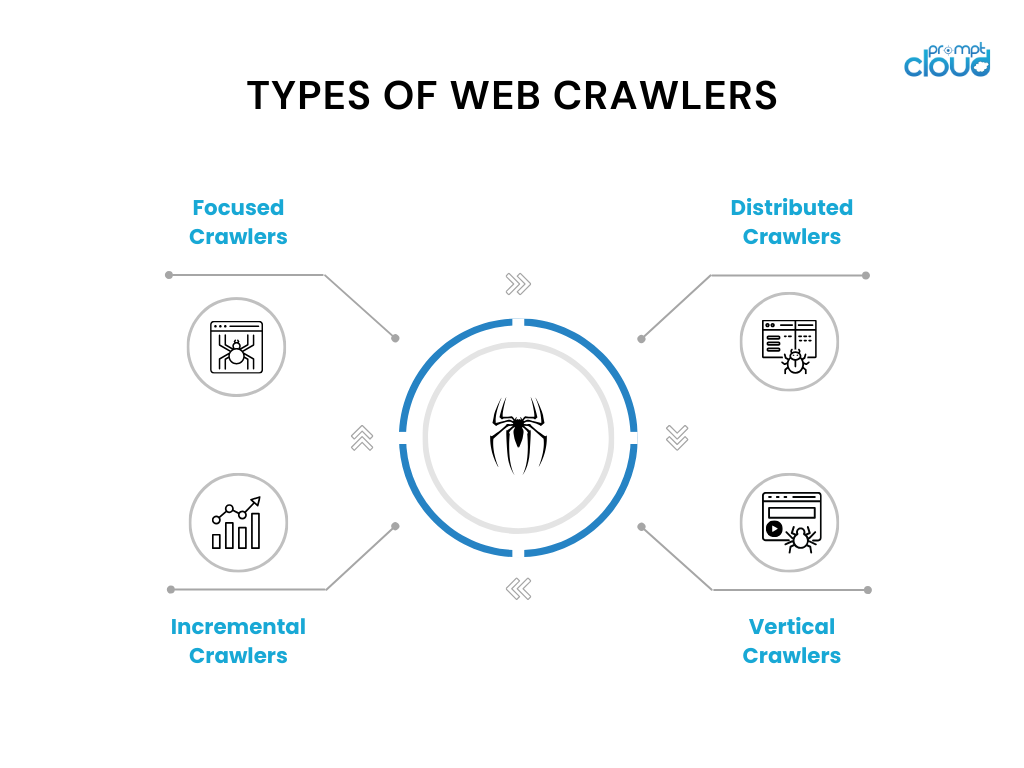
Come funziona un web crawler
I web crawler funzionano navigando sistematicamente in Internet per raccogliere e indicizzare il contenuto del sito web, un processo cruciale per i motori di ricerca. Partono da una serie di URL noti e accedono a queste pagine Web per recuperare contenuti. Durante l'analisi delle pagine, identificano tutti i collegamenti ipertestuali e li aggiungono all'elenco degli URL da visitare successivamente, mappando in modo efficace la struttura del web. Ogni pagina visitata viene elaborata per estrarre informazioni rilevanti, come testo, immagini e metadati, che vengono poi archiviate in un database. Questi dati diventano la base dell'indice di un motore di ricerca, consentendogli di fornire risultati di ricerca rapidi e pertinenti.
I web crawler devono operare entro determinati vincoli, come seguire le regole impostate nei file robots.txt dai proprietari dei siti web ed evitare di sovraccaricare i server, garantendo un processo di scansione etico ed efficiente. Mentre navigano tra miliardi di pagine web, questi crawler affrontano sfide come la gestione di contenuti dinamici, la gestione di pagine duplicate e il mantenimento dell'aggiornamento con le più recenti tecnologie web, rendendo il loro ruolo nell'ecosistema digitale complesso e indispensabile. Ecco un articolo dettagliato su come funzionano i web crawler.
Crawler Web Python
Python, rinomato per la sua semplicità e leggibilità, è un linguaggio di programmazione ideale per la creazione di web crawler. Il suo ricco ecosistema di librerie e framework semplifica il processo di scrittura di script che navigano, analizzano ed estraggono dati dal web. Ecco gli aspetti chiave che rendono Python la scelta ideale per la scansione del web:
Librerie Python chiave per la scansione del Web:
- Richieste : questa libreria viene utilizzata per effettuare richieste HTTP alle pagine Web. È semplice da usare e può gestire vari tipi di richieste, essenziali per accedere al contenuto della pagina web.
- Beautiful Soup : specializzato nell'analisi di documenti HTML e XML, Beautiful Soup consente una facile estrazione dei dati dalle pagine Web, semplificando la navigazione nella struttura dei tag del documento.
- Scrapy : un framework di scansione web open source, Scrapy fornisce un pacchetto completo per la scrittura di web crawler. Gestisce le richieste, l'analisi delle risposte e l'estrazione dei dati senza problemi.
Vantaggi dell'utilizzo di Python per la scansione del Web:
- Facilità d'uso : la sintassi semplice di Python lo rende accessibile anche a chi è nuovo alla programmazione.
- Solido supporto della community : una vasta community e un'ampia documentazione aiutano nella risoluzione dei problemi e nel miglioramento della funzionalità del crawler.
- Flessibilità e scalabilità : i crawler Python possono essere semplici o complessi a seconda delle necessità, scalando da progetti piccoli a grandi.
Esempio di un web crawler Python di base:
richieste di importazione

da bs4 importa BeautifulSoup
# Definisci l'URL da scansionare
URL = "http://esempio.com"
# Invia una richiesta HTTP all'URL
risposta = richieste.get(url)
# Analizza il contenuto HTML della pagina
zuppa = BeautifulSoup(risposta.testo, 'html.parser')
# Estrai e stampa tutti i collegamenti ipertestuali
per il collegamento in soup.find_all('a'):
print(link.get('href'))
Questo semplice script dimostra il funzionamento di base di un web crawler Python. Recupera il contenuto HTML di una pagina Web utilizzando le richieste, lo analizza con Beautiful Soup ed estrae tutti i collegamenti ipertestuali.
I web crawler Python si distinguono per la facilità di sviluppo e l'efficienza nell'estrazione dei dati.
Che si tratti di analisi SEO, data mining o marketing digitale, Python fornisce una base solida e flessibile per le attività di scansione del web, rendendolo una scelta eccellente sia per programmatori che per scienziati dei dati.
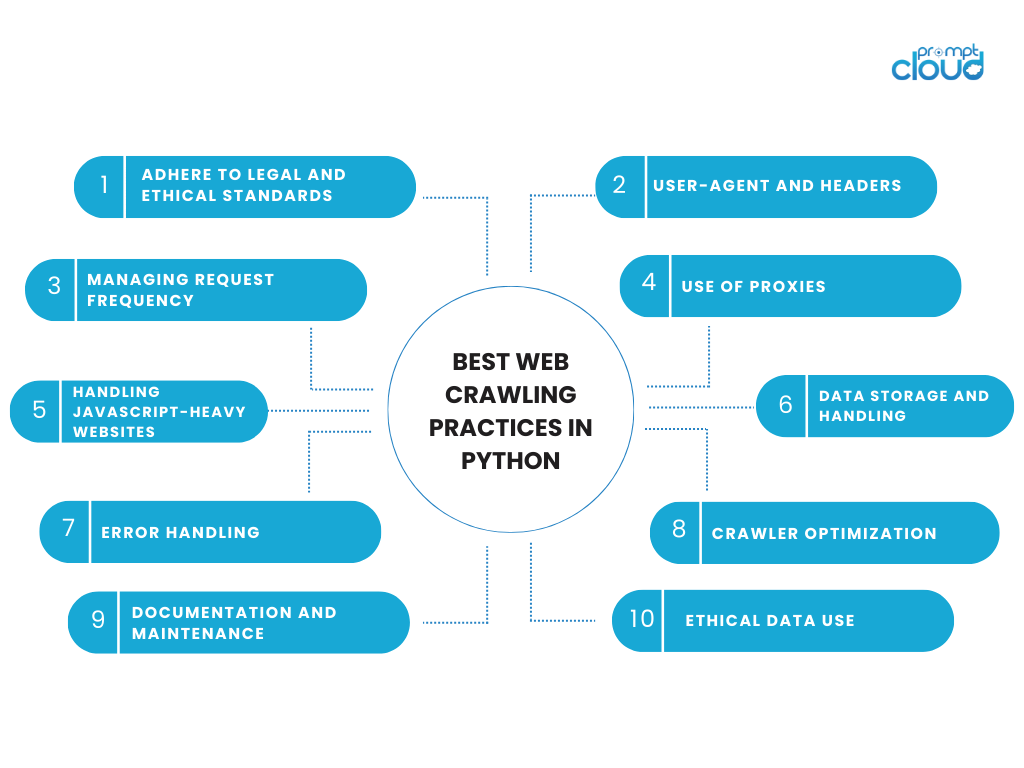
Casi d'uso della scansione web
Il web crawling ha una vasta gamma di applicazioni in diversi settori, riflettendo la sua versatilità e importanza nell’era digitale. Ecco alcuni dei casi d'uso chiave:
Indicizzazione nei motori di ricerca
L'uso più noto dei web crawler è quello da parte dei motori di ricerca come Google, Bing e Yahoo per creare un indice ricercabile del web. I crawler scansionano le pagine web, ne indicizzano i contenuti e li classificano in base a vari algoritmi, rendendoli ricercabili per gli utenti.
Estrazione e analisi dei dati
Le aziende utilizzano i web crawler per raccogliere dati sulle tendenze del mercato, sulle preferenze dei consumatori e sulla concorrenza. I ricercatori utilizzano i crawler per aggregare dati provenienti da più fonti per studi accademici.
Monitoraggio SEO
I webmaster utilizzano i crawler per capire come i motori di ricerca visualizzano i loro siti Web, aiutando a ottimizzare la struttura, il contenuto e le prestazioni del sito. Vengono utilizzati anche per analizzare i siti Web dei concorrenti per comprendere le loro strategie SEO.
Aggregazione di contenuti
I crawler vengono utilizzati dalle piattaforme di aggregazione di notizie e contenuti per raccogliere articoli e informazioni da varie fonti. Aggregazione di contenuti dalle piattaforme di social media per tenere traccia di tendenze, argomenti popolari o menzioni specifiche.
E-commerce e comparazione prezzi
I crawler aiutano a monitorare i prezzi dei prodotti su diverse piattaforme di e-commerce, aiutando nelle strategie di prezzo competitive. Vengono utilizzati anche per catalogare prodotti da vari siti di e-commerce in un'unica piattaforma.
Annunci immobiliari
I crawler raccolgono annunci immobiliari da vari siti web immobiliari per offrire agli utenti una visione consolidata del mercato.
Annunci di lavoro e reclutamento
Aggregazione di elenchi di lavoro da vari siti Web per fornire una piattaforma completa di ricerca di lavoro. Alcuni reclutatori utilizzano i crawler per setacciare il Web alla ricerca di potenziali candidati con qualifiche specifiche.
Apprendimento automatico e formazione sull'intelligenza artificiale
I crawler possono raccogliere grandi quantità di dati dal Web, che possono essere utilizzati per addestrare modelli di machine learning in varie applicazioni.
Web scraping e scansione web
Il web scraping e il web crawling sono due tecniche comunemente utilizzate nella raccolta di dati dai siti Web, ma hanno scopi diversi e funzionano in modi distinti. Comprendere le differenze è fondamentale per chiunque sia coinvolto nell'estrazione dei dati o nell'analisi web.
Raschiamento Web
- Definizione : il web scraping è il processo di estrazione di dati specifici dalle pagine web. Si concentra sulla trasformazione di dati web non strutturati (solitamente in formato HTML) in dati strutturati che possono essere archiviati e analizzati.
- Estrazione mirata dei dati : lo scraping viene spesso utilizzato per raccogliere informazioni specifiche da siti Web, come prezzi dei prodotti, dati sulle scorte, articoli di notizie, informazioni di contatto, ecc.
- Strumenti e tecniche : implica l'uso di strumenti o programmazione (spesso Python, PHP, JavaScript) per richiedere una pagina Web, analizzare il contenuto HTML ed estrarre le informazioni desiderate.
- Casi d'uso : ricerche di mercato, monitoraggio dei prezzi, lead generation, dati per modelli di machine learning, ecc.
Scansione del Web
- Definizione : il web crawling, invece, è il processo di navigazione sistematica sul web per scaricare e indicizzare i contenuti web. È principalmente associato ai motori di ricerca.
- Indicizzazione e collegamento successivo : i crawler, o spider, vengono utilizzati per visitare un'ampia gamma di pagine per comprendere la struttura e i collegamenti del sito. In genere indicizzano tutto il contenuto di una pagina.
- Automazione e scalabilità : il web crawling è un processo più automatizzato, in grado di gestire l'estrazione di dati su larga scala su molte pagine web o interi siti web.
- Considerazioni : i crawler devono rispettare le regole stabilite dai siti Web, come quelle nei file robots.txt, e sono progettati per navigare senza sovraccaricare i server Web.
Strumenti di scansione web
Gli strumenti di web crawling sono strumenti essenziali nella cassetta degli attrezzi digitali di aziende, ricercatori e sviluppatori, poiché offrono un modo per automatizzare la raccolta di dati da vari siti Web su Internet. Questi strumenti sono progettati per esplorare sistematicamente le pagine Web, estrarre informazioni utili e memorizzarle per un uso successivo. Ecco una panoramica degli strumenti di scansione web e del loro significato:
Funzionalità : gli strumenti di scansione web sono programmati per navigare attraverso i siti web, identificare informazioni rilevanti e recuperarle. Imitano il comportamento di navigazione umana, ma lo fanno su scala e velocità molto più ampie.
Estrazione e indicizzazione dei dati : questi strumenti analizzano i dati sulle pagine Web, che possono includere testo, immagini, collegamenti e altri media, quindi li organizzano in un formato strutturato. Ciò è particolarmente utile per creare database di informazioni che possono essere facilmente ricercate e analizzate.
Personalizzazione e flessibilità : molti strumenti di scansione web offrono opzioni di personalizzazione, consentendo agli utenti di specificare quali siti web scansionare, quanto approfondire l'architettura del sito e che tipo di dati estrarre.
Casi d'uso : vengono utilizzati per vari scopi, come l'ottimizzazione dei motori di ricerca (SEO), ricerche di mercato, aggregazione di contenuti, analisi della concorrenza e raccolta di dati per progetti di apprendimento automatico.
Il nostro recente articolo fornisce una panoramica dettagliata dei principali strumenti di scansione web del 2024. Consulta l'articolo per saperne di più. Contattaci all'indirizzo sales@promptcloud.com per soluzioni di scansione web personalizzate.