
Sfide e soluzioni del web scraping: navigare nelle complessità
Pubblicato: 2023-09-13Il web scraping è diventato una tecnica preziosa per estrarre dati dai siti web. Se hai bisogno di raccogliere informazioni a scopo di ricerca, monitorare prezzi o tendenze o automatizzare determinate attività online, il web scraping può farti risparmiare tempo e fatica. Navigare nelle complessità dei siti web e affrontare le varie sfide del web scraping può essere un compito arduo. In questo articolo, approfondiremo la semplificazione del processo di web scraping acquisendone una comprensione completa. Tratteremo i passaggi coinvolti, selezionando gli strumenti appropriati, identificando i dati di destinazione, navigando nelle strutture del sito web, gestendo l'autenticazione e il captcha e gestendo il contenuto dinamico.
Comprendere il Web Scraping
Il web scraping è la procedura di estrazione dei dati dai siti web attraverso l'analisi e il parsing del codice HTML e CSS. Comprende l'invio di richieste HTTP alle pagine Web, il recupero del contenuto HTML e la successiva estrazione delle informazioni pertinenti. Anche se il web scraping manuale mediante l'ispezione del codice sorgente e la copia dei dati è un'opzione, è spesso inefficiente e dispendioso in termini di tempo, soprattutto per raccolte di dati estese.
Per automatizzare il processo di web scraping, è possibile utilizzare linguaggi di programmazione come Python e librerie come Beautiful Soup o Selenium, nonché strumenti di web scraping dedicati come Scrapy o Beautiful Soup. Questi strumenti offrono funzionalità per interagire con i siti Web, analizzare HTML ed estrarre dati in modo efficiente.
Sfide di web scraping
Selezione degli strumenti appropriati
Selezionare gli strumenti giusti è fondamentale per il successo della tua attività di web scraping. Ecco alcune considerazioni quando scegli gli strumenti per il tuo progetto di web scraping:
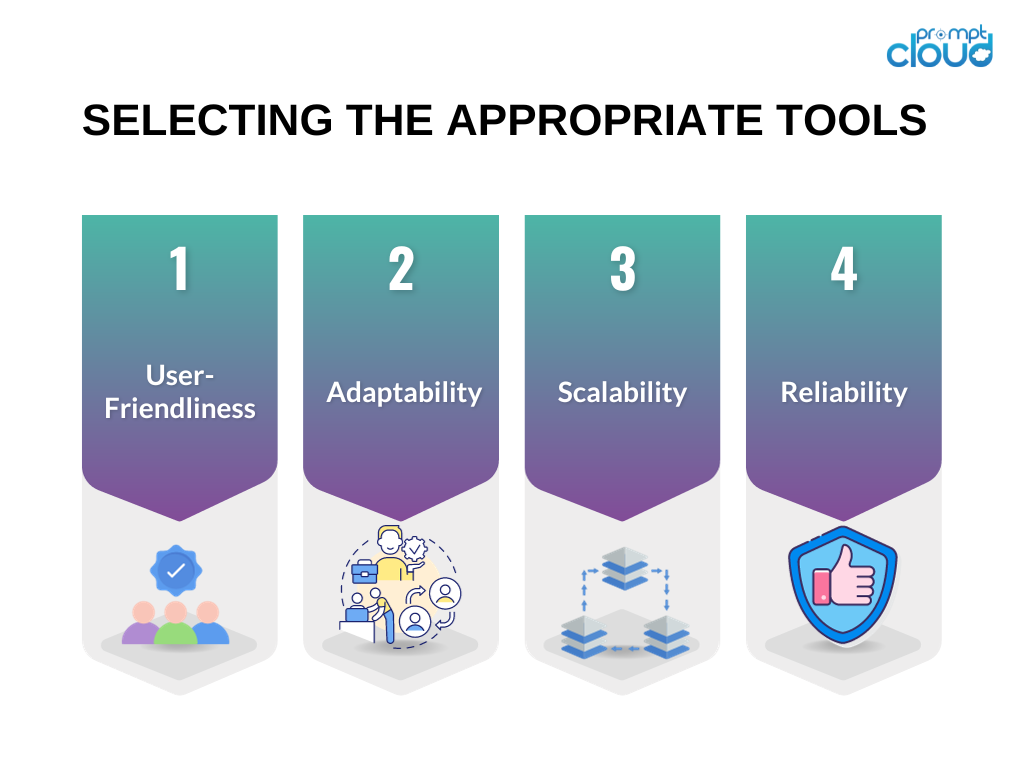
Facilità d'uso : dare priorità agli strumenti con interfacce facili da usare o quelli che forniscono documentazione chiara ed esempi pratici.
Adattabilità : optare per strumenti in grado di gestire diversi tipi di siti Web e adattarsi ai cambiamenti nelle strutture dei siti Web.
Scalabilità : se la tua attività di raccolta dati coinvolge una notevole quantità di dati o richiede funzionalità avanzate di web scraping, prendi in considerazione strumenti in grado di gestire volumi elevati e offrire funzionalità di elaborazione parallela.
Affidabilità : garantire che gli strumenti siano attrezzati per gestire vari tipi di errori, come timeout di connessione o errori HTTP, e siano dotati di meccanismi di gestione degli errori integrati.
Sulla base di questi criteri, strumenti ampiamente utilizzati come Beautiful Soup e Selenium sono spesso consigliati per progetti di web scraping.
Identificazione dei dati target
Prima di iniziare un progetto di web scraping, è fondamentale identificare i dati di destinazione che si desidera estrarre da un sito web. Potrebbero trattarsi di informazioni sul prodotto, articoli di notizie, post sui social media o qualsiasi altro tipo di contenuto. Comprendere la struttura del sito Web di destinazione è fondamentale per estrarre in modo efficace i dati desiderati.
Per identificare i dati di destinazione, puoi utilizzare strumenti per sviluppatori del browser come Chrome DevTools o Firefox Developer Tools. Questi strumenti ti consentono di ispezionare la struttura HTML di una pagina web, identificare gli elementi specifici contenenti i dati di cui hai bisogno e comprendere i selettori CSS o le espressioni XPath necessarie per estrarre tali dati.

Navigazione nelle strutture del sito web
I siti Web possono avere strutture complesse con elementi HTML nidificati, contenuto JavaScript dinamico o richieste AJAX. Navigare attraverso queste strutture ed estrarre le informazioni rilevanti richiede analisi e strategie attente.
Ecco alcune tecniche per aiutarti a navigare in strutture complesse di siti web:
Utilizza selettori CSS o espressioni XPath : comprendendo la struttura del codice HTML, puoi utilizzare selettori CSS o espressioni XPath per individuare elementi specifici ed estrarre i dati desiderati.
Gestire l'impaginazione : se i dati di destinazione sono distribuiti su più pagine, è necessario implementare l'impaginazione per raccogliere tutte le informazioni. Questo può essere fatto automatizzando il processo di clic sui pulsanti “successivo” o “carica altro” o costruendo URL con parametri diversi.
Gestire elementi nidificati : a volte, i dati di destinazione sono nidificati all'interno di più livelli di elementi HTML. In questi casi, è necessario attraversare gli elementi nidificati utilizzando le relazioni genitore-figlio o le relazioni di fratello per estrarre le informazioni desiderate.
Gestione dell'autenticazione e del captcha
Alcuni siti Web potrebbero richiedere l'autenticazione o presentare captcha per impedire lo scraping automatico. Per superare queste sfide di web scraping, puoi utilizzare le seguenti strategie:
Gestione della sessione : mantieni lo stato della sessione con cookie o token per gestire i requisiti di autenticazione.
Spoofing dello user-agent : emula diversi user-agent per apparire come utenti normali ed evitare il rilevamento.
Servizi di risoluzione captcha : utilizza servizi di terze parti in grado di risolvere automaticamente i captcha per tuo conto.
Tieni presente che, sebbene l'autenticazione e i captcha possano essere aggirati, dovresti assicurarti che le tue attività di web scraping siano conformi ai termini di servizio del sito Web e alle restrizioni legali.
Gestire i contenuti dinamici
I siti Web spesso utilizzano JavaScript per caricare i contenuti in modo dinamico o recuperare dati tramite richieste AJAX. I metodi tradizionali di web scraping potrebbero non acquisire questo contenuto dinamico. Per gestire il contenuto dinamico, considera i seguenti approcci:
Utilizza browser headless : strumenti come Selenium ti consentono di controllare i browser Web reali in modo programmatico e di interagire con il contenuto dinamico.
Utilizza librerie di web scraping : alcune librerie come Puppeteer o Scrapy-Splash possono gestire il rendering JavaScript e l'estrazione dinamica dei contenuti.
Utilizzando queste tecniche, puoi assicurarti di poter raschiare siti Web che fanno molto affidamento su JavaScript per la distribuzione dei contenuti.
Implementazione della gestione degli errori
Il web scraping non è sempre un processo fluido. I siti Web possono modificare la propria struttura, restituire errori o imporre limitazioni alle attività di scraping. Per mitigare i rischi associati a queste sfide di web scraping, è importante implementare meccanismi di gestione degli errori:
Monitora le modifiche del sito web : controlla regolarmente se la struttura o il layout del sito web sono cambiati e modifica di conseguenza il tuo codice di scraping.
Meccanismi di nuovo tentativo e di timeout : implementa meccanismi di nuovo tentativo e di timeout per gestire correttamente errori intermittenti come timeout di connessione o errori HTTP.
Registra e gestisci le eccezioni : acquisisci e gestisci diversi tipi di eccezioni, come errori di analisi o guasti di rete, per evitare che il processo di scraping fallisca completamente.
Implementando tecniche di gestione degli errori, puoi garantire l'affidabilità e la robustezza del tuo codice di web scraping.
Riepilogo
In conclusione, le sfide del web scraping possono essere semplificate comprendendo il processo, scegliendo gli strumenti giusti, identificando i dati di destinazione, navigando nelle strutture del sito web, gestendo l'autenticazione e i captcha, trattando il contenuto dinamico e implementando tecniche di gestione degli errori. Seguendo queste best practice, puoi superare le complessità del web scraping e raccogliere in modo efficiente i dati di cui hai bisogno.