
Che cos'è l'etichettatura dei dati nell'apprendimento automatico e come funziona?
Pubblicato: 2022-04-29I dati sono la nuova ricchezza per le aziende di oggi. Con tecnologie come l'intelligenza artificiale che prendono progressivamente il controllo della maggior parte delle nostre attività quotidiane, il corretto utilizzo di qualsiasi dato ha influenzato positivamente la società. Segregando ed etichettando i dati in modo efficiente, gli algoritmi ML possono scoprire i problemi e fornire soluzioni pratiche e pertinenti.
Con l'aiuto dell'etichettatura dei dati, insegniamo alla macchina varie tecniche e inseriamo le informazioni in vari formati affinché si comportino in modo "intelligente". La scienza alla base dell'etichettatura dei dati comporta un sacco di compiti sotto forma di annotazione o etichettatura dei set di dati con più variazioni delle stesse informazioni. Sebbene il risultato finale sorprenda e faciliti la nostra vita quotidiana, il lavoro dietro lo stesso è immenso e la dedizione lodevole.
Che cos'è l'etichettatura dei dati?
Nell'apprendimento automatico, la qualità e il tipo di dati di input determinano la qualità e il tipo di output. La qualità dei dati utilizzati per addestrare la macchina aumenta la precisione del tuo modello di intelligenza artificiale.
In altre parole, l'etichettatura dei dati è un processo per addestrare una macchina a trovare le differenze e le somiglianze tra i set di dati non strutturati o strutturati etichettandoli o annotandoli.
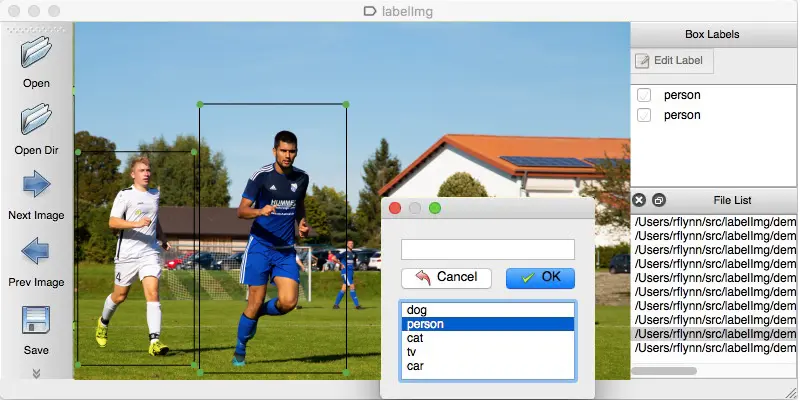
Cerchiamo di capirlo con un esempio. Per addestrare la macchina che la luce rossa è il segnale di arresto, è necessario contrassegnare tutte le luci rosse in varie immagini affinché la macchina comprenda il segnale. Sulla base di ciò, l'IA crea un algoritmo che leggerà la luce rossa come segnale di arresto in ogni dato scenario. Un altro esempio è che i generi musicali possono essere separati con più set di dati sotto le etichette jazz, pop, rock, classica e altro.
Sfide nell'etichettatura dei dati
Qualsiasi nuovo cambiamento/progresso nella tecnologia o nella struttura porta con sé vantaggi e sfide. Non è diverso per l'etichettatura dei dati. Sebbene l'etichettatura dei dati possa ridurre drasticamente i tempi di ridimensionamento di un'azienda , ha un costo. Soffermiamoci su alcune delle sfide che l'etichettatura dei dati comporta.
Costo in termini di tempo e fatica
È di per sé un compito impegnativo ottenere i dati specifici della nicchia in enormi quantità. L'aggiunta manuale di tag per ogni elemento non fa che aumentare l'attività già dispendiosa in termini di tempo. Se il progetto viene gestito internamente, la maggior parte del tempo del progetto viene dedicato ad attività relative ai dati come la raccolta, la preparazione e l'etichettatura dei dati.
Per gestire queste attività in modo efficace, in modo da ottenere il lavoro giusto al primo tentativo, avrai bisogno di etichettatori esperti con questa competenza specifica. Anche questa è un'impresa costosa, che la rende costosa, non solo in termini di tempo ma anche di denaro.
Incoerenza
Annotatori con competenze diverse possono avere criteri di etichettatura diversi. Di conseguenza, esiste un'elevata possibilità di etichettatura incoerente. Detto questo, quando più persone etichettano lo stesso set di dati, i tassi di accuratezza dei dati saranno molto più elevati.
Competenza nel dominio
Per settori specifici, sentirai la necessità di assumere etichettatrici con competenze specifiche nel settore. Ad esempio, per creare un'app ML per il settore sanitario , gli annotatori senza competenze di dominio pertinenti troveranno molto difficile taggare correttamente gli elementi.
Imperfezioni
Qualsiasi lavoro ripetitivo svolto dagli esseri umani è soggetto a errori. Qualunque sia il livello di competenza dell'etichettatore umano, l'etichettatura manuale avrà sempre lo scopo dell'imperfezione. Garantire zero errori è quasi impossibile poiché gli annotatori devono gestire grandi insiemi di dati grezzi per l'etichettatura.
Approcci all'etichettatura dei dati
Come accennato in precedenza, l'etichettatura dei dati è un'attività che richiede molto tempo e attenzione ai dettagli. In base alla definizione del problema, alla quantità di dati da etichettare, alla complessità dei dati e allo stile, la strategia applicata per annotare i dati varierà.
Esaminiamo i vari approcci che la tua azienda può optare in base alle risorse finanziarie e al tempo a disposizione.
Etichettatura interna dei dati
In base al tipo di settore, al tempo a disposizione per completare il progetto di intelligenza artificiale e alla disponibilità delle risorse necessarie, il processo di etichettatura dei dati può essere eseguito internamente dalle organizzazioni.
Professionisti:
- Alta precisione
- Alta qualità
- Tracciamento semplificato
Contro:
- Dispendioso in termini di tempo/lento
- Richiede ampie risorse
crowdsourcing
I set di dati di sourcing etichettati dai liberi professionisti sono disponibili su varie piattaforme di crowdsourcing. Questo metodo può essere utilizzato per annotare dati generalizzati come immagini.
L'esempio più famoso di etichettatura dei dati attraverso il crowdsourcing è Recaptcha. All'utente viene chiesto di identificare tipi specifici di immagini per dimostrare che sono esseri umani. Questi sono verificati sulla base degli input forniti da altri utenti. Questo funge da database di etichette per una matrice di immagini.
Professionisti:
- Facile e veloce
- Conveniente
Contro:
- Non può essere utilizzato per dati che richiedono competenze di dominio
- La qualità non è garantita
Esternalizzazione
L'outsourcing può fungere da via di mezzo tra l'etichettatura interna dei dati e il crowdsourcing. L'assunzione di organizzazioni di terze parti o individui con esperienza nel settore può aiutare le organizzazioni con tutti: progetti a lungo e breve termine.
Professionisti:
- Ideale per progetti temporanei di alto livello
- Le società di outsourcing di terze parti forniscono personale controllato
- Fornisce strumenti di etichettatura dei dati sia predefiniti che personalizzati in base alle esigenze aziendali
- Può ottenere l'opzione di esperti di etichettatura dei dati specifici di nicchia
Contro:
- La gestione di terze parti può richiedere molto tempo
Basato sulla macchina
Una delle ultime forme di etichettatura e annotazione dei dati ampiamente utilizzata e accettata dalle industrie è l'annotazione basata su macchine. L'automazione del processo di etichettatura dei dati con l'aiuto del software di etichettatura dei dati riduce l'intervento umano e aumenta la velocità con cui è possibile eseguire l'etichettatura. Con la tecnica denominata apprendimento attivo, i dati possono essere contrassegnati in base ai quali i tag possono essere aggiunti automaticamente ai set di dati di addestramento.
Professionisti:
- Elaborazione ed etichettatura dei dati più rapida
- Implica un minore intervento umano
Contro:
- Anche se di migliore qualità ma non alla pari con il tagging umano
- In caso di errori, è comunque necessario l'intervento umano

Come funziona l'etichettatura dei dati?
In base alle tue esigenze aziendali, puoi scegliere l'approccio più adatto alle tue esigenze. Tuttavia, il processo di etichettatura dei dati funziona nel seguente ordine cronologico.
Raccolta dati
La base di qualsiasi progetto di machine learning sono i dati. La raccolta della giusta quantità di dati grezzi in vari formati comprende il primo passaggio dell'etichettatura dei dati. La raccolta dei dati può essere di due forme: una che l'azienda ha raccolto internamente e l'altra che è stata raccolta da fonti esterne pubblicamente disponibili.
Essendo nella forma grezza, questi dati richiedono la pulizia e l'elaborazione prima di creare le etichette per i set di dati. Questi dati puliti e preelaborati vengono quindi inviati al modello per l'addestramento. Più i dati sono grandi e diversificati, più accurati saranno i risultati.
Annotazione dei dati
Una volta che i dati sono stati puliti, gli esperti di dominio esaminano i dati e aggiungono etichette seguendo vari approcci di etichettatura dei dati. Il contesto significativo è allegato al modello che può essere utilizzato come verità fondamentale . Queste sono le variabili target come le immagini che si desidera che il modello preveda.

Garanzia di qualità
Il successo dell'addestramento del modello ML dipende in larga misura dalla qualità dei dati che dovrebbero essere affidabili, accurati e coerenti. Per garantire queste etichette dati precise e accurate, devono essere effettuati controlli QA regolari. Con l'uso di algoritmi di controllo qualità come il Consensus e l'alpha test di Cronbach, è possibile determinare l'accuratezza di queste annotazioni. I controlli QA regolari contribuiscono notevolmente all'accuratezza dei risultati.
Formazione e test del modello
L'esecuzione di tutti i passaggi precedenti ha senso solo se i dati vengono testati per verificarne l'accuratezza. L'inserimento del set di dati non strutturato per vedere se fornisce i risultati attesi metterà alla prova il processo.
Casi d'uso del settore per l'etichettatura dei dati
Ora che abbiamo familiarità con l'etichettatura dei dati e come funziona, esaminiamo i casi d'uso più importanti.
Visione artificiale (CV)
Questo è un sottoinsieme dell'IA che consente alle macchine di derivare un'interpretazione significativa dagli input forniti sotto forma di immagini e video (immagini fisse estratte per la codifica).
L'annotazione della visione artificiale può essere utilizzata in vari settori per implementare i vantaggi pratici dell'IA.
- Nell'industria automobilistica, etichettare immagini e video per segmentare strade, edifici, pedoni e altri oggetti aiuterà i veicoli autonomi a distinguere tra queste entità per evitare il contatto nella vita reale.
- Nel settore sanitario, i sintomi della malattia possono essere segmentati in una scansione a raggi X, risonanza magnetica e TC. Con l'aiuto di immagini microscopiche, la maggior parte delle malattie critiche può essere diagnosticata in una fase precoce.
- I codici QR, i codici a barre delle etichette, ecc. possono essere utilizzati come etichette nel settore dei trasporti e della logistica per tracciare le merci.
Elaborazione del linguaggio naturale (PNL)
Questo è un sottoinsieme che consente alle macchine IA di interpretare il linguaggio umano e le statistiche. Derivando significato dal testo e dal parlato, l'algoritmo può analizzare vari aspetti linguistici.
La NLP è sempre più utilizzata in molte soluzioni aziendali .
- È comunemente usato in tutti i settori come assistente e-mail, funzione di completamento automatico, controllo ortografico, separazione di e-mail spam e non spam e molto altro.
- Sotto forma di chatbot , le domande di base poste dai clienti vengono interpretate e risposte in tempo reale senza l'intervento umano. Si prevede che il 70% delle interazioni con i clienti sarà gestito da chatbot e applicazioni di messaggistica mobile entro il 2023.
- La comprensione della polarità negativa e positiva del testo per catturare il sentimento dei clienti viene effettuata tramite l'etichettatura dei dati nell'e-commerce.
Appinventiv ha creato con successo un'app di social media per Vyrb che consente agli utenti di inviare e ricevere messaggi audio ottimizzati per dispositivi indossabili Bluetooth.

Panoramica del mercato dell'etichettatura dei dati AI
L'etichettatura dei dati è un settore fiorente che nasce dalla tecnologia AI . Poiché l'etichettatura dei dati dipende in gran parte dall'accuratezza dei dati forniti all'apprendimento automatico, è destinata a crescere nei prossimi anni.
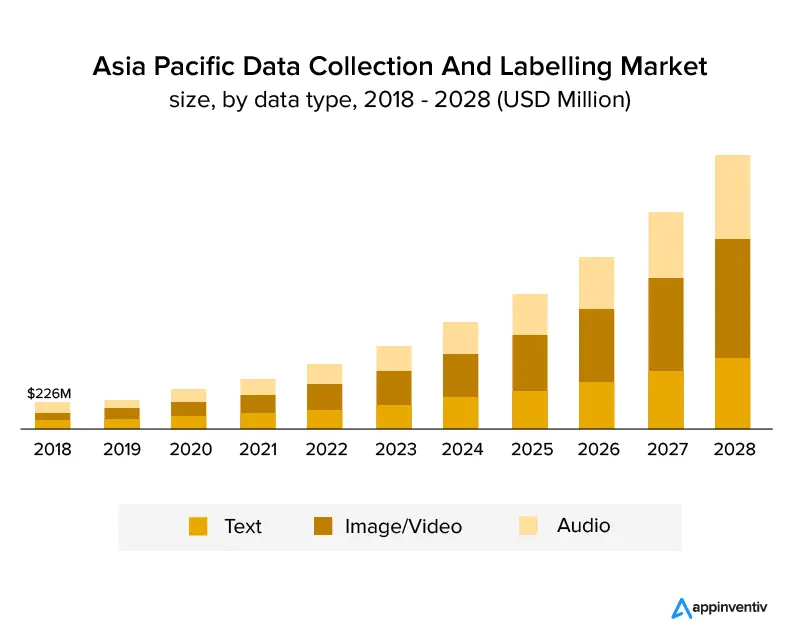
Il grafico sottostante mostra chiaramente che il settore è cresciuto e continuerà a crescere nei prossimi anni. Si prevede che cresca a una crescita annuale composta del 25,6% e raggiunga una dimensione del mercato di 8,22 miliardi di dollari entro il 2028. Il grafico seguente mostra la crescita per tipo di dati.
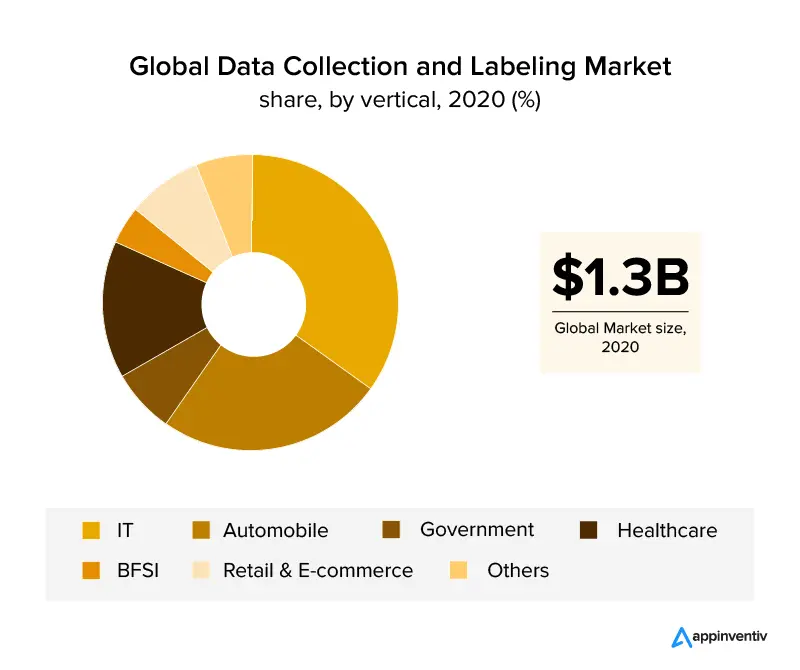
Una panoramica dei settori verticali di business che hanno sfruttato l'etichettatura dei dati sono i settori IT e automobilistico, che coprono oltre il 30% del fatturato globale. Con la crescita del settore sanitario , si prevede che l'etichettatura dei dati aumenterà a causa dei requisiti di dati accurati per applicazioni efficienti basate sull'intelligenza artificiale nel settore. Con l'aiuto dell'etichettatura delle immagini, anche i settori della vendita al dettaglio e dell'e-commerce si sono assicurati una quota di mercato significativa nel settore dell'etichettatura dei dati.
Etichettatura dei dati con Appinventiv
Strategicamente, le aziende hanno esternalizzato i servizi di raccolta ed etichettatura dei dati per la creazione di solidi modelli di machine learning.
Appinventiv è una società di sviluppo di AI e ML che da molti anni aiuta le organizzazioni a sbloccare opportunità con soluzioni basate sull'intelligenza artificiale . Con quasi un decennio di esperienza nella trasformazione delle aziende, abbiamo realizzato con successo molti progetti complessi di IA per diversi settori.
Ad esempio, Appinventiv ha automatizzato con successo il processo bancario per una banca leader in Europa. Il processo di automazione ha aiutato la banca a migliorare la precisione del 50% e i livelli di servizio ATM del 92%.
Un altro esempio in cui Appinventiv ha aiutato YouCOMM a costruire una soluzione rivoluzionaria per trasformare la comunicazione dei pazienti in ospedale fornendo accesso in tempo reale all'assistenza medica. Con un sistema di messaggistica paziente personalizzabile, i pazienti possono facilmente notificare al personale le loro esigenze tramite comandi vocali e l'uso di gesti della testa.
Con la nostra esperienza e un team incentrato sul cliente, forniamo i servizi di etichettatura dei dati che ti aiuteranno a superare le sfide fornendoti servizi di etichettatura dei dati olistici in base alle tue esigenze e requisiti specifici.
Sfruttando la vasta gamma di strumenti necessari per la codifica e l'annotazione dei dati, Appinventiv può migliorare i processi di formazione dei dati per semplificare modelli complessi. Ciò ci consente di ottenere prestazioni migliori in termini di accuratezza della segmentazione, classificazione e, successivamente, etichettatura dei dati che sarà semplice e veloce.
Avvolgendo!
"Il potere dell'intelligenza artificiale è così incredibile che cambierà la società in modi molto profondi". – Bill Gates
L'intelligenza artificiale ha il potenziale di semplificare la vita umana, facendo così del bene alla società. La sua capacità di ordinare enormi quantità di dati in istruzioni significative con l'aiuto dell'etichettatura dei dati ha aiutato le industrie a progredire e crescere a passi da gigante.
FAQ
D. Quali sono le migliori pratiche per perfezionare l'etichettatura dei dati?
R. In base all'approccio adottato per l'etichettatura dei dati, ci sono alcune best practice che puoi seguire:
- Garantire che i dati raccolti siano adeguati, adeguatamente puliti ed elaborati.
- In base al settore, assegna il lavoro solo a etichettatori di dati esperti di dominio.
- Garantire che il team segua un approccio uniforme fornendo loro i criteri delle tecniche di annotazione da seguire.
- Segui un processo di controllo del produttore assegnando più annotatori per l'etichettatura incrociata.
D. Quali sono i vantaggi dell'etichettatura dei dati?
R. L'etichettatura dei dati aiuta a fornire maggiore chiarezza su contesto, qualità e usabilità per fare una previsione precisa dei dati. Questo, a sua volta, aiuta a migliorare l'usabilità dei dati delle variabili nel modello.
D. Quali sono i vari elementi da considerare durante la selezione delle aziende di etichettatura dei dati?
R. Ci sono cinque parametri da considerare quando si scelgono i servizi di etichetta dati per l'apprendimento automatico.
- Scalabilità del processo di etichettatura dei dati
- Costo del servizio di etichettatura dei dati
- La sicurezza dei dati
- Piattaforma di etichettatura dei dati