
Cos'è Robots.txt in SEO: come crearlo e ottimizzarlo
Pubblicato: 2022-04-22L'argomento di oggi non è direttamente correlato alla monetizzazione del traffico. Ma robots.txt può influire sulla SEO del tuo sito Web e, alla fine, sulla quantità di traffico che riceve. Molti amministratori web hanno rovinato le classifiche dei loro siti web a causa di voci robots.txt pasticciate. Questa guida ti aiuterà a evitare tutte queste insidie. Assicurati di leggere fino alla fine!
- Che cos'è un file robots.txt?
- Come appare un file robots.txt?
- Come trovare il file robots.txt
- Come funziona un file Robots.txt?
- sintassi Robots.txt
- Direttive supportate
- User-agent*
- Permettere
- Non consentire
- Mappa del sito
- Direttive non supportate
- Ritardo di scansione
- Noindex
- Non seguire
- Hai bisogno di un file robots.txt?
- Creazione di un file robots.txt
- File Robots.txt: best practices SEO
- Utilizzare una nuova riga per ogni direttiva
- Usa i caratteri jolly per semplificare le istruzioni
- Usa il simbolo del dollaro "$" per specificare la fine di un URL
- Utilizzare ogni user-agent solo una volta
- Utilizzare istruzioni specifiche per evitare errori involontari
- Inserisci i commenti nel file robots.txt con un hash
- Utilizza diversi file robots.txt per ogni sottodominio
- Non bloccare buoni contenuti
- Non abusare del ritardo di scansione
- Presta attenzione alla distinzione tra maiuscole e minuscole
- Altre buone pratiche:
- Utilizzo di robots.txt per impedire l'indicizzazione dei contenuti
- Utilizzo di robots.txt per proteggere i contenuti privati
- Utilizzo di robots.txt per nascondere contenuti duplicati dannosi
- Accesso completo per tutti i bot
- Nessun accesso per tutti i bot
- Blocca una sottodirectory per tutti i bot
- Blocca una sottodirectory per tutti i bot (con un file consentito)
- Blocca un file per tutti i bot
- Blocca un tipo di file (PDF) per tutti i bot
- Blocca tutti gli URL parametrizzati solo per Googlebot
- Come verificare la presenza di errori nel file robots.txt
- URL inviato bloccato da robots.txt
- Bloccato da robots.txt
- Indicizzato, sebbene bloccato da robots.txt
- Robots.txt vs meta robot vs x-robot
- Ulteriori letture
- Avvolgendo
Che cos'è un file robots.txt?
Il robots.txt, o protocollo di esclusione robot, è un insieme di standard Web che controlla il modo in cui i robot dei motori di ricerca eseguono la scansione di ogni pagina Web, fino ai markup dello schema su quella pagina. È un file di testo standard che può persino impedire ai crawler Web di accedere all'intero sito Web oa parti di esso.
Mentre aggiusti la SEO e risolvi problemi tecnici, puoi iniziare a ottenere entrate passive dagli annunci. Una singola riga di codice sul tuo sito web restituisce pagamenti regolari!
Al Sommario ↑Come appare un file robots.txt?
La sintassi è semplice: dai regole ai bot specificando il loro user-agent e le loro direttive. Il file ha il seguente formato di base:
Mappa del sito: [Posizione URL della mappa del sito]
User-agent: [identificatore bot]
[direttiva 1]
[direttiva 2]
[direttiva...]
User-agent: [un altro identificatore di bot]
[direttiva 1]
[direttiva 2]
[direttiva...]
Come trovare il file robots.txt
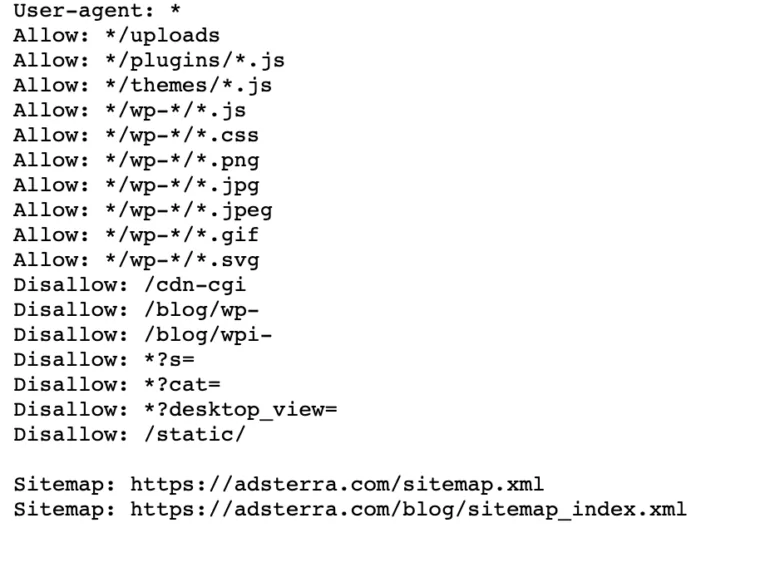
Se il tuo sito web ha già un file robot.txt, puoi trovarlo andando a questo URL: https://nomedominio.com/robots.txt nel tuo browser. Ad esempio, ecco il nostro file
Come funziona un file Robots.txt?
Un file robots.txt è un file di testo semplice che non contiene alcun codice di markup HTML (da cui l'estensione .txt). Questo file, come tutti gli altri file sul sito Web, è archiviato sul server Web. È improbabile che gli utenti visitino questa pagina perché non è collegata a nessuna delle tue pagine, ma la maggior parte dei bot web crawler la cerca prima di eseguire la scansione dell'intero sito web.
Un file robots.txt può fornire istruzioni ai bot ma non può imporre tali istruzioni. Un buon bot, come un web crawler o un news feed bot, controllerà il file e seguirà le istruzioni prima di visitare qualsiasi pagina di dominio. Ma i bot dannosi ignoreranno o elaboreranno il file per trovare pagine Web vietate.
In una situazione in cui un file robots.txt contiene comandi in conflitto, il bot utilizzerà il set di istruzioni più specifico.
Al Sommario ↑sintassi Robots.txt
Un file robots.txt è costituito da diverse sezioni di "direttive", ciascuna che inizia con uno user-agent. Lo user-agent specifica il bot di scansione con cui comunica il codice. Puoi indirizzare tutti i motori di ricerca contemporaneamente o gestire i singoli motori di ricerca.
Ogni volta che un bot esegue la scansione di un sito Web, agisce sulle parti del sito che lo stanno chiamando.
User-agent: *
Non consentire: /
User-agent: Googlebot
Non consentire:
User-agent: Bingbot
Non consentire: /non-per-bing/
Direttive supportate
Le direttive sono linee guida che vuoi che gli user-agenti che dichiari seguano. Google attualmente supporta le seguenti direttive.
User-agent*
Quando un programma si connette a un server web (un robot o un normale browser web), invia un'intestazione HTTP chiamata "user-agent" contenente informazioni di base sulla sua identità. Ogni motore di ricerca ha uno user-agent. I robot di Google sono conosciuti come Googlebot, Yahoo - come Slurp e Bing - come BingBot. L'agente utente avvia una sequenza di direttive, che possono essere applicate a agenti utente specifici oa tutti gli agenti utente.
Permettere
La direttiva allow dice ai motori di ricerca di eseguire la scansione di una pagina o di una sottodirectory, anche una directory con restrizioni. Ad esempio, se desideri che i motori di ricerca non siano in grado di accedere a tutti i post del tuo blog tranne uno, il tuo file robots.txt potrebbe avere il seguente aspetto:
User-agent: *
Non consentire: /blog
Consenti: /blog/post-consentito
Tuttavia, i motori di ricerca possono accedere a /blog/allowed-post ma non sono in grado di accedere a:
/blog/un-altro-post
/blog/ancora-un-altro-post
/blog/download-me.pd
Non consentire
La direttiva disallow (che viene aggiunta al file robots.txt di un sito Web) dice ai motori di ricerca di non eseguire la scansione di una pagina specifica. Nella maggior parte dei casi, ciò impedirà anche la visualizzazione di una pagina nei risultati di ricerca.
Puoi utilizzare questa direttiva per istruire i motori di ricerca a non eseguire la scansione di file e pagine in una cartella specifica che stai nascondendo al pubblico in generale. Ad esempio, il contenuto su cui stai ancora lavorando ma pubblicato per errore. Il tuo file robots.txt potrebbe avere questo aspetto se desideri impedire a tutti i motori di ricerca di accedere al tuo blog:
User-agent: *
Non consentire: /blog
Ciò significa che anche tutte le sottodirectory della directory /blog non verranno sottoposte a scansione. Ciò impedirebbe anche a Google di accedere agli URL contenenti /blog.
Al Sommario ↑Mappa del sito
Le Sitemap sono un elenco di pagine di cui desideri eseguire la scansione e l'indicizzazione dei motori di ricerca. Se utilizzi la direttiva Sitemap, i motori di ricerca conosceranno la posizione della tua Sitemap XML. L'opzione migliore è inviarli agli strumenti per i webmaster dei motori di ricerca perché ognuno può fornire ai visitatori informazioni preziose sul tuo sito web.
È importante notare che ripetere la direttiva Sitemap per ogni agente utente non è necessario e non si applica a un agente di ricerca. Aggiungi le istruzioni della mappa del sito all'inizio o alla fine del file robots.txt.
Un esempio di una direttiva Sitemap nel file:
Mappa del sito: https://www.domain.com/sitemap.xml
User-agent: Googlebot
Non consentire: /blog/
Consenti: /blog/titolo del post/
User-agent: Bingbot
Non consentire: /servizi/
Al Sommario ↑Direttive non supportate
Le seguenti sono direttive che Google non supporta più , alcune delle quali tecnicamente non sono mai state approvate.
Ritardo di scansione
Yahoo, Bing e Yandex rispondono rapidamente all'indicizzazione dei siti Web e reagiscono alla direttiva crawl-delay, che li tiene sotto controllo per un po'.
Applica questa riga al tuo blocco:
User-agent: Bingbot
Ritardo di scansione: 10
Significa che i motori di ricerca possono attendere dieci secondi prima di eseguire la scansione del sito Web o dieci secondi prima di riaccedere al sito Web dopo la scansione, che è la stessa cosa ma leggermente diversa a seconda dello user-agent in uso.
Noindex
Il meta tag noindex è un ottimo modo per impedire ai motori di ricerca di indicizzare una delle tue pagine. Il tag consente ai robot di accedere alle pagine Web, ma informa anche i robot di non indicizzarli.
- Intestazione della risposta HTTP con tag noindex. Puoi implementare questo tag in due modi: un'intestazione di risposta HTTP con un X-Robots-Tag o un tag <meta> posizionato all'interno della sezione <head>. Ecco come dovrebbe apparire il tuo tag <meta>:
<meta name=”robot” content=”noindex”>
- Codice di stato HTTP 404 e 410. I codici di stato 404 e 410 indicano che una pagina non è più disponibile. Dopo la scansione e l'elaborazione di 404/410 pagine, le rimuovono automaticamente dall'indice di Google. Per ridurre il rischio di pagine di errore 404 e 410, esegui regolarmente la scansione del tuo sito Web e utilizza i reindirizzamenti 301 per indirizzare il traffico a una pagina esistente, ove necessario.
Non seguire
Nofollow indirizza i motori di ricerca a non seguire i collegamenti su pagine e file in un percorso specifico. Dal 1 marzo 2020, Google non considera più gli attributi nofollow come direttive. Saranno invece dei suggerimenti, proprio come i tag canonici. Se desideri un attributo "nofollow" per tutti i link in una pagina, usa il meta tag del robot, l'intestazione x-robots o l'attributo link rel= "nofollow" .
In precedenza potevi utilizzare la seguente direttiva per impedire a Google di seguire tutti i link sul tuo blog:
User-agent: Googlebot
Nofollow: /blog/
Hai bisogno di un file robots.txt?
Molti siti web meno complessi non ne hanno bisogno. Sebbene Google di solito non indicizzi le pagine Web bloccate da robots.txt, non c'è modo di garantire che queste pagine non vengano visualizzate nei risultati di ricerca. Avere questo file ti dà più controllo e sicurezza dei contenuti del tuo sito web rispetto ai motori di ricerca.
I file Robots ti aiutano anche a realizzare quanto segue:
- Impedisci la scansione dei contenuti duplicati.
- Mantieni la privacy per le diverse sezioni del sito web.
- Limita la scansione interna dei risultati di ricerca.
- Prevenire il sovraccarico del server.
- Prevenire gli sprechi da “crawl budget”.
- Mantieni immagini, video e file di risorse fuori dai risultati di ricerca di Google.
Queste misure alla fine influiscono sulle tue tattiche SEO. Ad esempio, il contenuto duplicato confonde i motori di ricerca e li costringe a scegliere quale delle due pagine classificare per prima. Indipendentemente da chi ha creato il contenuto, Google potrebbe non selezionare la pagina originale per i primi risultati di ricerca.

Nei casi in cui Google rileva contenuti duplicati destinati a ingannare gli utenti o manipolare le classifiche, regolerà l'indicizzazione e la classifica del tuo sito web. Di conseguenza, il posizionamento del tuo sito potrebbe risentire o essere completamente rimosso dall'indice di Google, scomparendo dai risultati di ricerca.
Il mantenimento della privacy per le diverse sezioni del sito Web migliora anche la sicurezza del tuo sito Web e lo protegge dagli hacker. A lungo termine, queste misure renderanno il tuo sito web più sicuro, affidabile e redditizio.
Sei il proprietario di un sito web che vuole trarre profitto dal traffico? Con Adsterra, otterrai entrate passive da qualsiasi sito web!
Al Sommario ↑Creazione di un file robots.txt
Avrai bisogno di un editor di testo come Blocco note.
- Crea un nuovo foglio, salva la pagina vuota come "robots.txt" e inizia a digitare le direttive nel documento .txt vuoto.
- Accedi al tuo cPanel, vai alla directory principale del sito, cerca la cartella public_html .
- Trascina il file in questa cartella e quindi ricontrolla se l'autorizzazione del file è impostata correttamente.
Puoi scrivere, leggere e modificare il file come proprietario, ma non sono consentite terze parti. Nel file dovrebbe essere visualizzato un codice di autorizzazione "0644" . In caso contrario, fai clic con il pulsante destro del mouse sul file e scegli "permesso file".
File Robots.txt: best practices SEO
Utilizzare una nuova riga per ogni direttiva
È necessario dichiarare ogni direttiva su una riga separata. In caso contrario, i motori di ricerca saranno confusi.
User-agent: *
Non consentire: /directory/
Non consentire: /un'altra-directory/
Usa i caratteri jolly per semplificare le istruzioni
Puoi utilizzare i caratteri jolly (*) per tutti gli user-agent e abbinare i pattern URL quando dichiari le direttive. Il carattere jolly funziona bene per gli URL che hanno uno schema uniforme. Ad esempio, potresti voler impedire la scansione di tutte le pagine dei filtri con un punto interrogativo (?) negli URL.
User-agent: *
Non consentire: /*?
Usa il simbolo del dollaro "$" per specificare la fine di un URL
I motori di ricerca non possono accedere agli URL che terminano con estensioni come .pdf. Ciò significa che non potranno accedere a /file.pdf, ma potranno accedere a /file.pdf?id=68937586, che non termina con ".pdf". Ad esempio, se vuoi impedire ai motori di ricerca di accedere a tutti i file PDF sul tuo sito web, il tuo file robots.txt potrebbe avere il seguente aspetto:
User-agent: *
Non consentire: /*.pdf$
Utilizzare ogni user-agent solo una volta
In Google, non importa se utilizzi lo stesso user-agent più di una volta. Compilerà semplicemente tutte le regole delle varie dichiarazioni in un'unica direttiva e la seguirà. Tuttavia, dichiarare ogni user-agent solo una volta ha senso perché crea meno confusione.
Mantenere le vostre direttive ordinate e semplici riduce il rischio di errori critici. Ad esempio, se il tuo file robots.txt conteneva i seguenti agenti utente e direttive.
User-agent: Googlebot
Non consentire: /a/
User-agent: Googlebot
Non consentire: /b/
Utilizzare istruzioni specifiche per evitare errori involontari
Quando si impostano le direttive, la mancata fornitura di istruzioni specifiche può creare errori che possono danneggiare il tuo SEO. Supponiamo di avere un sito multilingue e di lavorare su una versione tedesca per la sottodirectory /de/.
Non vuoi che i motori di ricerca possano accedervi perché non è ancora pronto. Il seguente file robots.txt impedirà ai motori di ricerca di indicizzare quella sottocartella e il suo contenuto:
User-agent: *
Non consentire: /de
Tuttavia, impedirà ai motori di ricerca di eseguire la scansione di pagine o file che iniziano con /de. In questo caso, l'aggiunta di una barra finale è la soluzione semplice.
User-agent: *
Non consentire: /de/
Al Sommario ↑Inserisci i commenti nel file robots.txt con un hash
I commenti aiutano gli sviluppatori e forse anche te a capire il tuo file robots.txt. Inizia la riga con un cancelletto (#) per includere un commento. I crawler ignorano le righe che iniziano con un hash.
# Questo indica al bot Bing di non eseguire la scansione del nostro sito.
User-agent: Bingbot
Non consentire: /
Utilizza diversi file robots.txt per ogni sottodominio
Robots.txt influisce solo sulla scansione del suo dominio host. Avrai bisogno di un altro file per limitare la scansione su un sottodominio diverso. Ad esempio, se ospiti il tuo sito web principale su example.com e il tuo blog su blog.example.com, avrai bisogno di due file robots.txt. Inseriscine uno nella directory principale del dominio principale, mentre l'altro file dovrebbe trovarsi nella directory principale del blog.
Non bloccare buoni contenuti
Non utilizzare un file robots.txt o un tag noindex per bloccare qualsiasi contenuto di qualità che desideri rendere pubblico per evitare effetti negativi sui risultati SEO. Controlla attentamente i tag noindex e non consenti regole sulle tue pagine.
Non abusare del ritardo di scansione
Abbiamo spiegato il ritardo della scansione, ma non dovresti usarlo frequentemente perché limita la scansione di tutte le pagine da parte dei bot. Potrebbe funzionare per alcuni siti Web, ma potresti danneggiare le tue classifiche e il traffico se hai un sito Web di grandi dimensioni.
Presta attenzione alla distinzione tra maiuscole e minuscole
Il file Robots.txt fa distinzione tra maiuscole e minuscole, quindi devi assicurarti di creare un file robots nel formato corretto. Il file robots dovrebbe essere denominato "robots.txt" con tutte le lettere minuscole. Altrimenti, non funzionerà.
Altre buone pratiche:
- Assicurati di non bloccare la scansione dei contenuti o delle sezioni del tuo sito web.
- Non utilizzare robots.txt per mantenere i dati sensibili (informazioni utente private) fuori dai risultati SERP. Utilizzare un metodo diverso, come la crittografia dei dati o la meta direttiva noindex , per limitare l'accesso se altre pagine si collegano direttamente alla pagina privata.
- Alcuni motori di ricerca hanno più di un agente utente. Google, ad esempio, utilizza Googlebot per le ricerche organiche e Googlebot-Image per le immagini. Non è necessario specificare le direttive per i crawler multipli di ciascun motore di ricerca poiché la maggior parte dei programmi utente dello stesso motore di ricerca segue le stesse regole.
- Un motore di ricerca memorizza nella cache i contenuti di robots.txt ma li aggiorna quotidianamente. Se modifichi il file e desideri aggiornarlo più velocemente, puoi inviare l'URL del file a Google.
Utilizzo di robots.txt per impedire l'indicizzazione dei contenuti
La disabilitazione di una pagina è il modo più efficace per impedire ai bot di scansionarla direttamente. Tuttavia, non funzionerà nelle seguenti situazioni:
- Se un'altra fonte ha collegamenti alla pagina, i bot continueranno a eseguirne la scansione e l'indicizzazione.
- I bot illegittimi continueranno a eseguire la scansione e l'indicizzazione del contenuto.
Utilizzo di robots.txt per proteggere i contenuti privati
Alcuni contenuti privati, come PDF o pagine di ringraziamento, possono comunque essere indicizzabili anche se blocchi i bot. Posizionare tutte le tue pagine esclusive dietro un login è uno dei modi migliori per rafforzare la direttiva disallow. I tuoi contenuti rimarranno disponibili, ma i tuoi visitatori faranno un passo in più per accedervi.
Utilizzo di robots.txt per nascondere contenuti duplicati dannosi
Il contenuto duplicato è identico o molto simile ad altri contenuti nella stessa lingua. Google cerca di indicizzare e mostrare pagine con contenuti unici. Ad esempio, se il tuo sito ha versioni "normali" e "stampanti" di ogni articolo e un tag noindex non blocca nessuno dei due, ne elencherà uno.
Esempio di file robots.txt
Di seguito sono riportati alcuni file robots.txt di esempio. Questi sono principalmente per idee, ma se uno di questi soddisfa le tue esigenze, copialo e incollalo in un documento di testo, salvalo come "robots.txt" e caricalo nella directory corretta.
Accesso completo per tutti i bot
Esistono diversi modi per dire ai motori di ricerca di accedere a tutti i file, incluso avere un file robots.txt vuoto o nessuno.
User-agent: *
Non consentire:
Nessun accesso per tutti i bot
Il seguente file robots.txt indica a tutti i motori di ricerca di evitare di accedere all'intero sito:
User-agent: *
Non consentire: /
Blocca una sottodirectory per tutti i bot
User-agent: *
Non consentire: /cartella/
Blocca una sottodirectory per tutti i bot (con un file consentito)
User-agent: *
Non consentire: /cartella/
Consenti: /cartella/pagina.html
Blocca un file per tutti i bot
User-agent: *
Non consentire: /questo-è-un-file.pdf
Blocca un tipo di file (PDF) per tutti i bot
User-agent: *
Non consentire: /*.pdf$
Blocca tutti gli URL parametrizzati solo per Googlebot
User-agent: Googlebot
Non consentire: /*?
Come verificare la presenza di errori nel file robots.txt
Gli errori in Robots.txt possono essere gravi, quindi è importante monitorarli. Controlla regolarmente il rapporto "Copertura" in Search Console per problemi relativi a robot.txt. Alcuni degli errori che potresti riscontrare, cosa significano e come risolverli sono elencati di seguito.
URL inviato bloccato da robots.txt
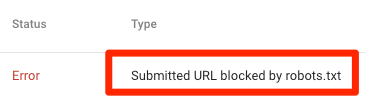
Indica che robots.txt ha bloccato almeno uno degli URL nelle tue Sitemap. Se la tua mappa del sito è corretta e non include pagine canonizzate, non indicizzate o reindirizzate, robots.txt non dovrebbe bloccare le pagine che invii. In tal caso, identifica le pagine interessate e rimuovi il blocco dal file robots.txt.
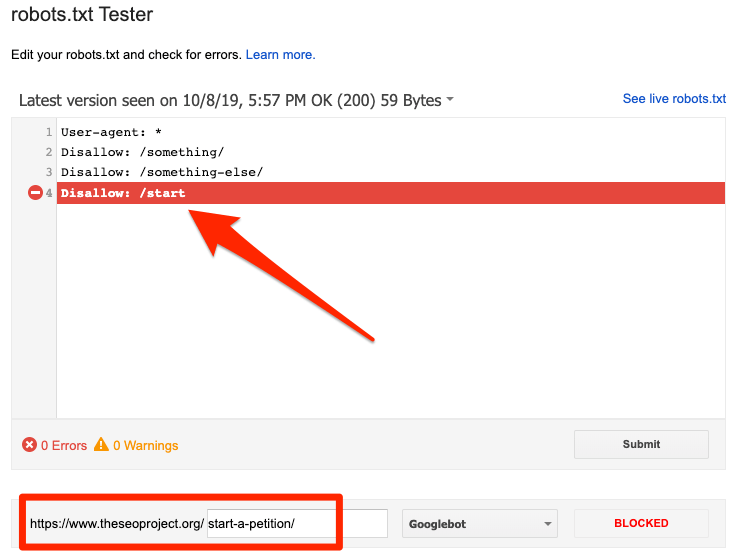
Puoi utilizzare il tester robots.txt di Google per identificare la direttiva di blocco. Fai attenzione quando modifichi il tuo file robots.txt perché un errore può influire su altre pagine o file.
Bloccato da robots.txt
Questo errore indica che robots.txt ha bloccato contenuti che Google non può indicizzare. Rimuovi il blocco di scansione in robots.txt se questo contenuto è fondamentale e deve essere indicizzato. (Inoltre, controlla che il contenuto non sia non indicizzato.)
Se desideri escludere contenuti dall'indice di Google, utilizza il meta tag di un robot o x-robots-header e rimuovi il blocco di scansione. Questo è l'unico modo per mantenere i contenuti fuori dall'indice di Google.
Indicizzato, sebbene bloccato da robots.txt
Significa che Google indicizza ancora alcuni dei contenuti bloccati da robots.txt. Robots.txt non è la soluzione per impedire la visualizzazione dei tuoi contenuti nei risultati di ricerca di Google.
Per impedire l'indicizzazione, rimuovi il blocco di scansione e sostituiscilo con un meta tag robots o un'intestazione HTTP x-robots-tag. Se hai bloccato accidentalmente questo contenuto e desideri che Google lo indicizzi, rimuovi il blocco di scansione in robots.txt. Può aiutare a migliorare la visibilità del contenuto nelle ricerche su Google.
Robots.txt vs meta robot vs x-robot
Cosa differenzia questi tre comandi del robot? Robots.txt è un semplice file di testo, mentre meta e x-robots sono meta direttive. Al di là dei loro ruoli fondamentali, i tre hanno funzioni distinte. Robots.txt specifica il comportamento di scansione per l'intero sito Web o directory, mentre i meta e x-robot definiscono il comportamento di indicizzazione per singole pagine (o elementi di pagina).
Ulteriori letture
Risorse utili
- Wikipedia: Protocollo di esclusione dei robot
- La documentazione di Google su Robots.txt
- Documentazione Bing (e Yahoo) su Robots.txt
- Direttive spiegate
- Documentazione Yandex su Robots.txt
Avvolgendo
Ci auguriamo che tu abbia compreso appieno l'importanza del file robot.txt e dei suoi contributi alla pratica SEO complessiva e alla redditività del sito web. Se stai ancora lottando per ottenere entrate dal tuo sito web, non avrai bisogno di codifica per iniziare a guadagnare con gli annunci Adsterra. Inserisci un codice pubblicitario sul tuo sito Web HTML, WordPress o Blogger e inizia a realizzare un profitto oggi!