
Quale tecnologia utilizzano i motori di ricerca per eseguire la scansione dei siti Web?
Pubblicato: 2023-03-02
Se ti sei mai chiesto quale tecnologia utilizzano i motori di ricerca per eseguire la scansione dei siti Web, preparati a ricevere finalmente una risposta alle tue domande. Scoprirai cos'è un web crawler, i diversi tipi di web crawler utilizzati dai principali motori di ricerca e in cosa consiste il processo di indicizzazione della ricerca. Imparerai anche come tutto ciò influenzerà i risultati dei motori di ricerca e come i proprietari di siti web possono dire ai web crawler dei motori di ricerca di indicizzare i contenuti secondo i loro desideri. Scopriamo di più su questa tecnologia utilizzata dai motori di ricerca per fornire accuratamente miliardi di risultati di ricerca pertinenti alle persone che cercano informazioni sul world wide web.
Cosa sono i web crawler o i bot dei motori di ricerca?
I web crawler bot, noti anche come spider, sono programmi automatizzati che aziende come Google e Microsoft utilizzano per insegnare ai loro motori di ricerca ciò che è presente in ogni pagina Web accessibile di ogni sito Web che possono trovare su Internet. È solo imparando quali informazioni sono incluse in una pagina Web che questi motori di ricerca possono recuperare accuratamente queste informazioni quando uno dei loro utenti digita una query di ricerca che richiede di conoscere un argomento specifico.
I tipi di bot del crawler web
Ogni motore di ricerca ha i suoi web crawler. Ecco alcuni dei più utilizzati.
Googlebot
Google è il motore di ricerca più popolare del pianeta e utilizza due versioni di web crawler per indicizzare centinaia di miliardi di pagine web. GoogleBot Desktop esaminerà le pagine che imitano il comportamento di qualcuno che utilizza un computer desktop per navigare in Internet, mentre GoogleBot Mobile farà lo stesso per gli utenti di smartphone.
Il GoogleBot è uno dei tipi più efficaci di robot di ricerca mai realizzati e può eseguire rapidamente la scansione e l'indicizzazione delle pagine web. Tuttavia, ha qualche problema a eseguire la scansione di strutture di siti Web molto complesse. Inoltre, spesso GoogleBot può impiegare molti giorni o settimane per eseguire la scansione di una pagina Web appena pubblicata, il che significa che non verrà visualizzata nei risultati pertinenti per un po' di tempo.
Bigbot
Il Bingbot è la risposta di Microsoft a Google sul proprio motore di ricerca Bing. Funziona in modo simile al web crawler di Google e include anche uno strumento di recupero che indica come il bot eseguirà la scansione di una pagina, permettendoti di vedere se ci sono problemi qui.
Slurp Bot
Lo Slurp Bot è il web crawler utilizzato da Yahoo, sebbene utilizzi anche Bingbot per fornire i risultati dei motori di ricerca. Il proprietario del sito web deve consentire l'accesso allo Slurp Bot se desidera che il contenuto della sua pagina web appaia nei risultati di ricerca di Yahoo Mobile. Inoltre, lo Slurp Bot può anche accedere ai siti partner di Yahoo per aggiungere contenuti ai loro siti Web Yahoo News, Yahoo Sports e Yahoo Finance.
DuckDuckBot
Questo è il web crawler utilizzato da DuckDuckGo, un motore di ricerca noto per fornire un livello di privacy senza pari per i suoi utenti non monitorando la loro attività come fanno molti popolari. Forniscono risultati di ricerca ottenuti dal loro DuckDuckBot, nonché siti Web di crowdsourcing come Wikipedia e altri motori di ricerca.
Baiduspider e Yandex Bot
Questi sono i robot crawler utilizzati rispettivamente dai motori di ricerca Baidu dalla Cina e Yandex dalla Russia. Baidu detiene oltre l'80% del mercato dei motori di ricerca nella Cina continentale.
Come funzionano la scansione Web, l'indicizzazione della ricerca e il posizionamento nei motori di ricerca
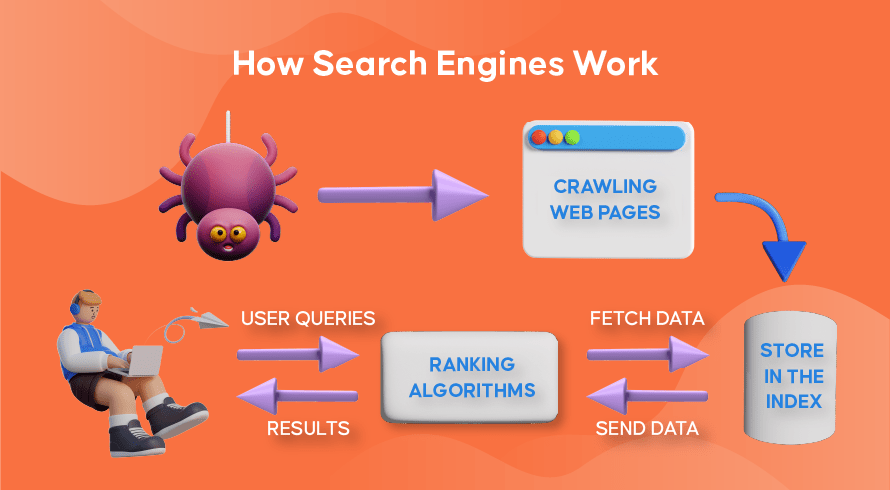
Ora esploriamo come la maggior parte dei motori di ricerca utilizza i web crawler per trovare, archiviare, organizzare e recuperare le informazioni contenute nei siti web.
Come funzionano i web crawler
Il processo di ricerca di contenuti nuovi e aggiornati sui siti Web è chiamato "web crawling", da cui il nome dei programmi software che svolgono questa funzione. I bot inizieranno prima a eseguire la scansione di alcune pagine Web, ne troveranno il contenuto e quindi seguiranno i collegamenti ipertestuali inclusi in quella pagina Web per scoprire nuovi URL, portando a ancora più contenuti.
Come funziona l'indicizzazione sui motori di ricerca
Dopo che i bot scoprono contenuti nuovi o aggiornati tramite la scansione del Web, tutto ciò che trovano viene aggiunto a un enorme database chiamato "indice del motore di ricerca". È come una biblioteca in cui i libri sono come pagine web, organizzati per un facile recupero in seguito. Contenente in ogni libro la maggior parte del testo contenuto in una pagina web che possiamo vedere (escluse parole come 'a', 'an' e 'the') così come i metadati che solo i crawler vedono. I metadati sono ciò che i motori di ricerca utilizzano per comprendere il contenuto di una pagina web. Il meta titolo e la meta descrizione sono esempi di metadati.
Come funziona il ranking di ricerca
Ogni volta che un utente digita una query di ricerca, il rispettivo motore di ricerca controllerà il suo indice, troverà le informazioni più pertinenti che corrispondono a questa richiesta, organizzerà l'elenco dei collegamenti Web che contengono il contenuto pertinente e lo presenterà all'utente nel motore di ricerca pagine dei risultati (SERP).
Questa organizzazione delle SERP si chiama 'search ranking' e viene eseguita da un algoritmo di ricerca che tiene conto dei dati raccolti inclusi i metadati, la credibilità del sito web (authority), oltre a parole chiave e link. I siti Web ritenuti fonti molto credibili e contenenti contenuti altamente pertinenti che saranno utili agli utenti si classificheranno in alto, ricevendo i migliori risultati nelle SERP. Questo è il motivo per cui ogni proprietario di un sito Web ha strategie per classificare il proprio sito Web nelle SERP.
Come entra in gioco l'ottimizzazione per i motori di ricerca (SEO).
I proprietari di siti web possono ottimizzare i contenuti delle loro pagine in modo tale che i motori di ricerca li riconoscano più facilmente come pertinenti e utili per i loro utenti. Ciò spingerà queste pagine in cima alle SERP, portando più traffico organico al sito web. L'inclusione strategica di parole chiave pertinenti nella copia della pagina, la creazione di collegamenti e l'uso di immagini e video originali sono alcuni dei modi in cui è possibile utilizzare le tecniche SEO.
Inoltre, i siti Web possono anche utilizzare vari strumenti come SEMrush per trovare e risolvere vari problemi sulle loro pagine come collegamenti interrotti che miglioreranno ulteriormente il loro posizionamento agli occhi dei motori di ricerca.

Dire ai motori di ricerca come scansionare il tuo sito web

A volte ti accorgerai che i web crawler non hanno svolto adeguatamente la loro funzione, causando la mancanza di pagine importanti del tuo sito web dall'indice. Ciò significa che le query di ricerca pertinenti non verranno presentate con i tuoi contenuti, rendendo difficile per i potenziali clienti trovare la strada per le tue pagine. Fortunatamente, ci sono modi per comunicare con i motori di ricerca, permettendoti un po' di controllo su ciò che viene indicizzato e ciò che viene ignorato.
Il file robots.txt memorizzato nella directory principale del tuo sito web è ciò che indica ai web crawler quali pagine vuoi scansionare, quali ignorare e come è organizzata l'architettura del tuo sito web. Potresti voler impedire l'indicizzazione di pagine specifiche se vengono utilizzate per test o promozioni speciali e URL duplicati utilizzati nell'e-commerce.
GoogleBot, ad esempio, procederà comunque alla scansione completa di un sito Web se non è presente alcun file robots.txt. Quando rileva il tuo file robots.txt, GoogleBot seguirà le tue istruzioni durante la scansione. Se ha problemi a rilevare il file o incontra un errore, potrebbe non eseguire la scansione del tuo sito web. Devi utilizzare correttamente il file robots.txt, organizzare l'architettura del tuo sito Web e utilizzare le migliori pratiche SEO on-page per evitare problemi con la scansione. Puoi eseguire un audit del sito web per analizzare e identificare eventuali problemi che affliggono il tuo sito web.
Hai bisogno di servizi SEO per il tuo sito web?
Se stai cercando un fornitore di servizi che capisca come funzionano i web crawler e l'indicizzazione della ricerca per migliorare il posizionamento del tuo sito web, allora Inquivix è il partner SEO che stavi cercando. Forniamo un set completo di servizi SEO on-page dalla creazione di contenuti, all'ottimizzazione dell'architettura del sito e all'analisi delle prestazioni del sito web per continuare a migliorare la qualità della tua esperienza sul sito web. Per saperne di più, visita i servizi SEO on-page di Inquivix oggi stesso!
Domande frequenti
I motori di ricerca utilizzano programmi chiamati "web crawler", noti anche come "spider" o "bot" per scoprire contenuti nuovi e aggiornati nelle pagine di un sito web. Seguirà quindi i collegamenti inclusi nella pagina per trovare altre pagine. Il contenuto trovato su una pagina viene salvato in un indice che viene utilizzato per recuperare informazioni per i risultati di ricerca quando un utente lo richiede.
GoogleBot Desktop e GoogleBot Mobile sono i web crawler più popolari nella maggior parte dei paesi, seguiti da Bingbot, Slurp Bot e DuckDuckBot. Baiduspider è utilizzato principalmente in Cina mentre Yandex Bot è utilizzato in Russia.