
効果的な B2C データ分析プロセスを設計する方法
公開: 2022-10-28生産的なデータ分析プロセスにより、マーケティング チームは現在と過去の両方のパフォーマンスを正しく測定し、信頼できる予測を行い、それに応じて戦略を最適化できます。
これは、Amazon、Netflix、Walmart などのトップ B2C ブランドの成功の重要な要因となっています。 消費者が日々のニーズを満たすためにデジタル手段を模索し続ける中、あらゆる業界の B2C マーケティング担当者は、顧客に質の高い体験を提供し、ROI を高めるためのデータ分析の重要性を認識しています。
このガイドでは、データ分析を設定することの重要性について説明し、会社での設計と実装のプロセスについて説明します。
カスタマージャーニーの複雑化
包括的なデータ分析セットアップの必要性は、ますます複雑化するカスタマー ジャーニーと、パーソナライズされたエクスペリエンスに対する顧客の期待から生じています。
実際、顧客の 71% はパーソナライズされた対話を標準と見なしており、76% はそれが得られないと不満を感じています。 ガートナーの調査によると、パーソナライゼーションに失敗したブランドは、顧客の 38% を失うリスクがあります。 さらに分解してみましょう。

米国とヨーロッパの多くの地域では、平均的な世帯が少なくとも 7 台の接続されたデバイスにアクセスでき、その多くは検索、メール、ソーシャル メディアなどを通じてブランドと関わるために使用できます。 これにより、B2C 企業はより多くの顧客にリーチする機会を得ることができますが、マーケティングと販売はより多くの時間と困難を伴います。
発見段階からコンバージョンまで、顧客は長い道のりを歩み、通常は平均 8 つのタッチポイントを獲得します。 顧客の 92% が、最初は購入するつもりがなくオンライン ストアにアクセスしたとします。 実際、これらの顧客の 25% は競合他社の価格と機能を比較するためにアクセスし、45% は特定の製品やサービスについて詳しく知るためにアクセスしています。 SNSや比較サイト、検索エンジンなど、オンラインストアの外でもマーケティング活動は続いています。 購入が完了した後もカスタマー ジャーニーは続き、これらの人々はパーソナライズされたレコメンデーションやオファーを切望しています。
とはいえ、複数のタッチポイントにまたがる顧客へのマーケティングでは、膨大な量のデータが取得および生成されます。 このデータには、コンバージョン ジャーニーのさまざまな段階における消費者の行動、独自のニーズ、および最も魅力的なパーソナライズされたオファーを作成する方法に関する情報が含まれています。
複数のソースからの大量のデータを処理するには、時間がかかり、費用がかかり、エラーが発生しやすくなる可能性があります。 多くの場合、企業はサイロ化された低品質のデータに行き着き、顧客に提供するエクスペリエンスの品質を低下させます。 これにより、世界の消費者売上高が約 4.7 兆ドル失われることになります。
この悪循環を断ち切るには、企業は最新のテクノロジーとデータ管理手法を活用する必要があります。
データ駆動型の運用: データのアクセシビリティとクリーン データ
InfoTrust と Forrester によるウェビナーで、シニア アナリストの Richard Joyce 氏は次のように述べています。
データアクセシビリティとは、組織内で使用できるようにデータにアクセスできるようにすることです。 これは、さまざまな部門の人やデータ処理のさまざまな経験を持つ人々が、どこでどのようにデータにアクセスまたは要求し、使用可能な状態でデータを取得できるかを知っていることを意味します。
クリーンなデータへのアクセシビリティは、データ駆動型の B2C 企業の核となる側面の 1 つです。 これにより、顧客対応部門はミッション クリティカルなインサイトを利用できるようになり、前述のように、コンバージョンの増加と純利益の増加につながります。 データ アクセシビリティの多くの利点には、次のようなものもあります。
意思決定の改善
さまざまな部門の幹部がデータにアクセスして使用できるようになると、各リーダーは、会社の全体的な業績と、チームの活動が最終目標にどのように貢献しているかを理解しやすくなります。
この情報は、彼らが決定を下し、会社を目標に近づけながら肯定的な結果を生み出す戦略を実行するのに役立ちます。 意思決定に使用されるデータの品質を決して無視してはならないことを強調することが重要です。
Gartner によると、企業は低品質のデータに基づく意思決定により、年間平均 1,500 万ドルを失っています。
データ品質を測定して改善する方法を学ぶ
強化されたデータ品質
サイロは、ビジネスにおける低品質データの主な原因です。 データがさまざまな部門にサイロ化されていると、重複や矛盾が発生するのは避けられず、会社の顧客、パートナー、および製品の全体像を構築することが難しくなります。 MIT によると、データの品質が低いと、企業は収益の 15% から 25% を失う可能性があります。
しかし、データにアクセスできるようになると、状況は好転します。 チームはより最新のデータを取得し、重複や矛盾した情報が排除され、より優れた洞察が生成され、会社はより多くの利益を得ることができます。
より効果的な予算配分
適切に整理されたデータにアクセスできると、最良の結果をもたらすチャネルと戦略を特定することが可能になります。 これを知ることで、各費用を正当化し、パフォーマンスの高い分野により多くの予算を割り当てることができます。
カスタマー エクスペリエンスの向上
顧客対応チーム間で消費者データを相互受粉することで、さまざまな部門が顧客の行動や顧客のジャーニーのあらゆる段階での独自のニーズについてより深い洞察を得ることができます。 これは、販売促進コンテンツの生成、パーソナライズされたオファーの作成、クライアントとのより良い関係の確立に役立ちます。

B2C 企業向けのデータ分析プロセスの設計
データ分析には、データ分析ライフ サイクルと広く呼ばれる 6 つの主要なフェーズが含まれます。
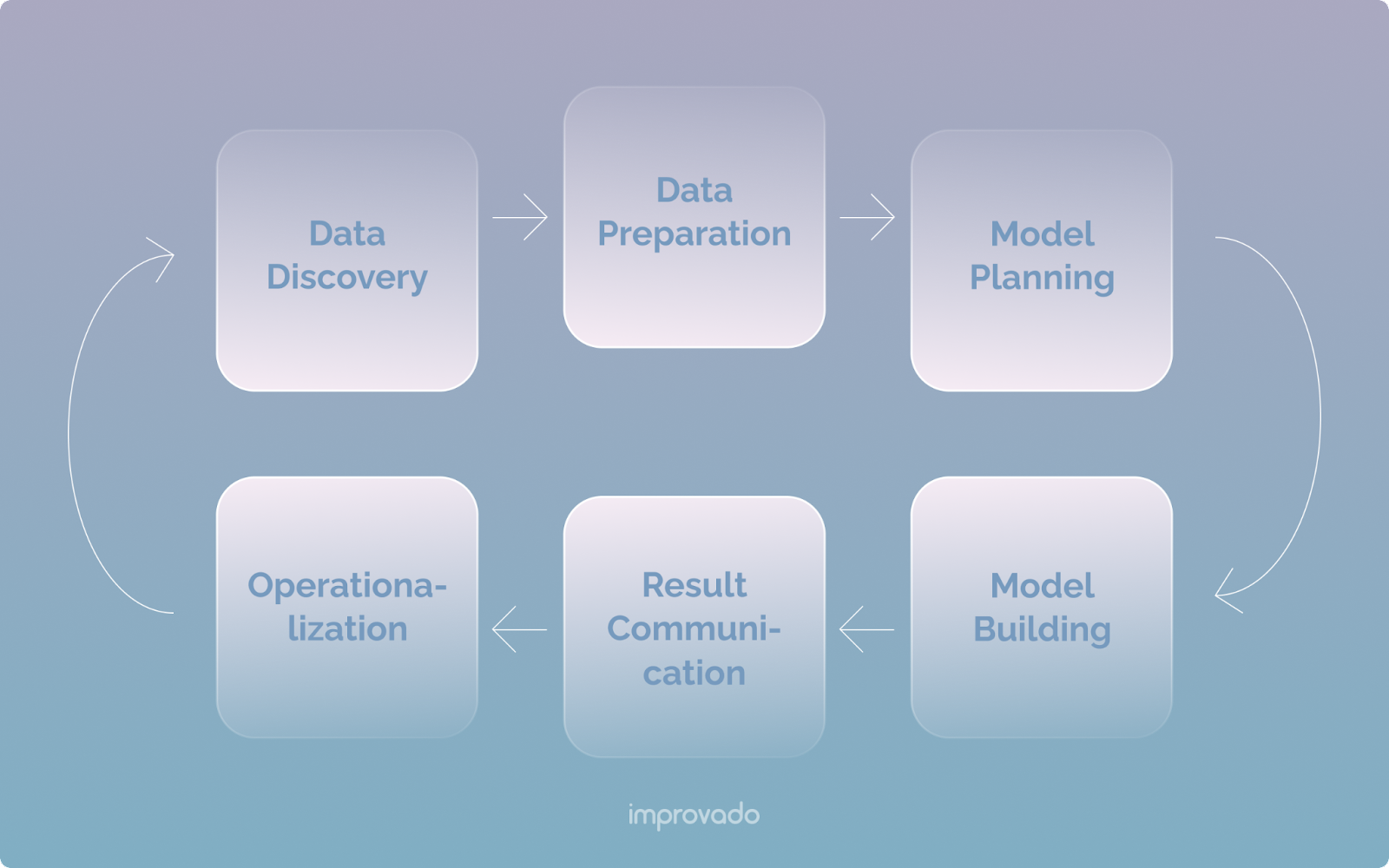
このセクションでは、データ分析ライフ サイクルのさまざまなフェーズを使用して B2C 分析プロセスを構築する方法について説明します。
発見と準備
発見段階では、データ自体よりもビジネス ニーズに重点が置かれます。 ここでは、チームの明確な目標を設定し、それを達成する方法について戦略を立てる必要があります。 業界の傾向を調査し、利用可能なリソースと技術要件を評価する必要があります。
その後、会社のデータ ソースと、データで伝えたいストーリーを特定します。 このデータは通常、現在の市場シナリオに基づいてビジネス ニーズを解決する仮説テストを通過します。
発見段階の後、準備段階が続きます。 ここでは、ビジネス目標からデータ要件に焦点が移ります。 データ準備には、内部および外部ソースから受信するビジネス データの取得、処理、およびクリーニングが含まれます。 収集されたデータは、構造化 (パターンが定義されている)、半構造化、または非構造化のいずれかです。
B2C ブランドとして、データ ソースには Amazon Advertising、Facebook Ads、Shopify が含まれる場合があります。
モデルの計画と構築
必要なデータをキャプチャしたので、次のステップは、データを読み込んで変換することです。 それがモデル計画フェーズのすべてです。
データを分析サンドボックスにロードするために使用できる手法がいくつかあります。 主なタイプは次の 2 つです。
- 抽出、変換、ロード (ETL): この手順では、サンドボックスにロードする前に、定義済みのビジネス ルールを使用してデータを抽出および変換します。
- 抽出、読み込み、変換 (ELT): ここでは、生データをサンドボックスに読み込み、後でデータを変換します。
ETL プロセスの初心者向けガイドを読む
このフェーズでは、ダーティ データをフィルタリングするか、完全に削除することができます。 採用する可能性のあるその他の手法には、データの集約、統合、スクラビングなどがあります。
構築フェーズには、トレーニングおよび本番用のデータセットの開発が含まれます。 ここでは、デシジョン ツリー、ロジスティック回帰、ニューラル ネットワークなどの手法を利用します。 この段階では、設計されたモデルの実行もカバーされ、実行環境の性質が定義および準備されるため、より堅牢な環境が必要な場合に簡単に拡張できます。
結果連絡
この段階では、モデルの実行結果を社内の利害関係者に知らせる必要があります。 利害関係者はレポートを精査して、発見フェーズで規定されたビジネス基準を満たしているかどうかを判断します。 これには、分析からの重要な調査結果の特定、結果に関連するビジネス目標の測定、および会社の利害関係者向けの要約の作成が含まれます。
運用化
この段階では、サンドボックスからデータを移動し、実際の環境でモデルを実装します。 データは常に監視および分析され、生成されたモデルが期待どおりの結果を返すようにします。 結果が期待どおりでない場合は、いつでも戻って微調整を行うことができます。
Impprovado によるデータ分析の自動化
データ パイプラインを手動で構築および管理することは、特にペタバイトのデータを持つエンタープライズ レベルの企業にとって、時間がかかり、リソースを大量に消費し、エラーが発生しやすいプロセスになる可能性があります。
エンタープライズ レベルの企業のデータ エンジニアは平均して、1 日の勤務時間の 40% を不良データや破損したデータ パイプラインの修正に費やしています。
手動 ETL のエラーが発生しやすい性質は、データ エンジニアがパイプライン内でインシデントを検出するペースが遅いことによって悪化します。 Wakefield 氏によると、エンジニアはエラーの検出に平均 4 時間、修正に約 9 時間かかります。
これにより、不良データが頻繁に発生し、これらの企業の収益の 26% に影響を与えています。 不良データの脅威を抑えるために、企業は Impprovado のような自動化された ETL プラットフォームを活用する必要があります。
Impprovado は、オムニチャネル マーケティング分析とレポート作成を大規模に自動化する収益データ プラットフォームです。 このプラットフォームは、企業のデータ分析ライフ サイクル (集約、変換、およびクレンジング) の重要な領域を自動化し、クリーンで分析可能なデータを目的のウェアハウス、BI、分析、または視覚化ツールに提供します。
これにより、レポート作成にかかる時間が最大 90% 短縮され、会社のデータをより詳細に管理できるようになり、最終的に ROI が向上します。
時代の先を行く
消費者の状況が日ごとに複雑化する中、データ駆動型の組織は、自動化されたオムニチャネルの収益プラットフォームで分析スタックを強化し、手動の ETL を後回しにすることで、常に先を行ってきました。
これにより、既存のデータを一元化し、新しいデータ ソースに合わせてスケーリングし、影響力のある成長志向の洞察を明らかにすることに集中できます。
Improvado が貴社の堅牢でスケーラブルなデータ分析プロセスの確立にどのように役立つかについて詳しく知りたい場合は、お気軽にお問い合わせください。 喜んでお手伝いいたします。