
動的 Web サイトからのデータ抽出: 課題と解決策
公開: 2023-11-23インターネットには、広範で拡大し続けるデータが蓄積されており、洞察、情報に基づいた意思決定、革新的なソリューションを求める企業、研究者、個人に多大な価値を提供します。 ただし、この貴重な情報の大部分は動的な Web サイト内に存在します。
従来の静的 Web サイトとは異なり、動的 Web サイトはユーザーの操作や外部イベントに応じてコンテンツを動的に生成します。 これらのサイトは JavaScript などのテクノロジーを活用して Web ページのコンテンツを操作するため、データを効果的に抽出する従来の Web スクレイピング技術にとっては大きな課題となっています。
この記事では、動的な Web ページのスクレイピングの領域を深く掘り下げていきます。 このプロセスに関連する典型的な課題を検討し、これらのハードルを克服するための効果的な戦略とベスト プラクティスを紹介します。
動的 Web サイトを理解する
動的 Web ページのスクレイピングの複雑さを掘り下げる前に、動的 Web サイトの特徴を明確に理解することが重要です。 均一なコンテンツを普遍的に提供する静的な Web サイトとは対照的に、動的な Web サイトは、ユーザーの好み、検索クエリ、リアルタイム データなどのさまざまなパラメーターに基づいてコンテンツを動的に生成します。
動的 Web サイトでは、多くの場合、高度な JavaScript フレームワークを利用して、クライアント側で Web ページのコンテンツを動的に変更および更新します。 このアプローチによりユーザーの対話性は大幅に向上しますが、プログラムでデータを抽出しようとすると課題が生じます。
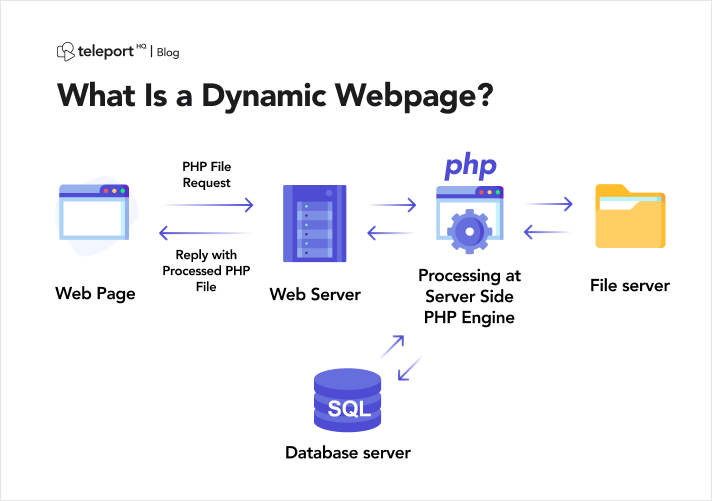
画像ソース: https://teleporthq.io/
動的Webページスクレイピングにおける一般的な課題
動的な Web ページのスクレイピングでは、コンテンツの動的な性質により、いくつかの課題が生じます。 最も一般的な課題には次のようなものがあります。
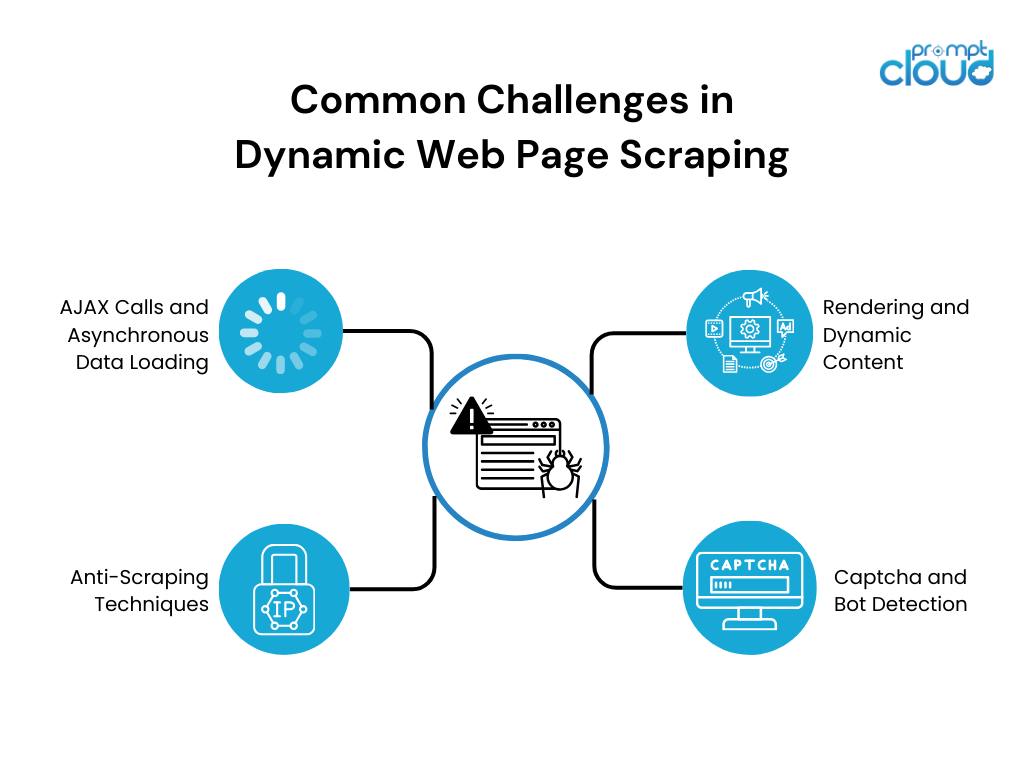
- レンダリングと動的コンテンツ:動的 Web サイトは、コンテンツを動的にレンダリングするために JavaScript に大きく依存しています。 従来の Web スクレイピング ツールは、JavaScript 駆動のコンテンツとの対話に苦労し、不完全または不正確なデータ抽出を引き起こします。
- AJAX 呼び出しと非同期データ読み込み:多くの動的 Web サイトは、AJAX (Asynchronous JavaScript and XML) 呼び出しを使用して、ページ全体を再読み込みせずに Web サーバーからデータを取得します。 この非同期データの読み込みにより、完全なデータ セットを収集することが困難になる可能性があります。これは、データ セットが段階的に読み込まれたり、ユーザーの操作によってトリガーされたりする可能性があるためです。
- キャプチャとボットの検出:データのスクレイピングと保護を防ぐために、Web サイトではキャプチャやボット検出メカニズムなどのさまざまな対策を採用しています。 これらのセキュリティ対策はスクレイピングの取り組みを妨げるため、克服するには追加の戦略が必要です。
- アンチスクレイピング技術: Web サイトでは、スクレーパーを阻止するために、IP ブロック、レート制限、難読化された HTML 構造などのさまざまなアンチスクレイピング技術が採用されています。 これらの手法では、検出を回避して目的のデータを正常にスクレイピングするための適応型スクレイピング戦略が必要です。
動的 Web ページのスクレイピングを成功させるための戦略
課題はありますが、動的な Web ページをスクレイピングする際に直面する障害を克服するために採用できる戦略やテクニックがいくつかあります。 これらの戦略には次のものが含まれます。

- ヘッドレス ブラウザの使用: Puppeteer や Selenium などのヘッドレス ブラウザを使用すると、JavaScript の実行と動的コンテンツのレンダリングが可能になり、動的 Web サイトからデータを正確に抽出できます。
- ネットワーク トラフィックの検査:ネットワーク トラフィックを分析すると、動的な Web サイト内のデータ フローについての洞察が得られます。 この知識を利用して、AJAX 呼び出しを識別し、応答を傍受し、必要なデータを抽出できます。
- 動的コンテンツの解析:動的コンテンツが JavaScript によってレンダリングされた後に HTML DOM を解析すると、必要なデータを抽出するのに役立ちます。 Beautiful Soup や Cheerio などのツールを利用して、更新された DOM からデータを解析して抽出できます。
- IP ローテーションとプロキシ: IP アドレスをローテーションし、プロキシを使用すると、IP ブロッキングとレート制限の課題を克服できます。 これにより、分散スクレイピングが可能になり、Web サイトがスクレイパーを単一のソースとして識別するのを防ぎます。
- キャプチャとアンチスクレイピング技術への対処:キャプチャに直面した場合、キャプチャ解決サービスを採用するか人間によるエミュレーションを実装することで、これらの対策を回避することができます。 さらに、難読化された HTML 構造は、DOM トラバーサルやパターン認識などの技術を使用してリバース エンジニアリングできます。
動的 Web スクレイピングのベスト プラクティス
動的 Web ページをスクレイピングするときは、スクレイピング プロセスを倫理的に成功させるために、特定のベスト プラクティスに従うことが重要です。 いくつかのベスト プラクティスは次のとおりです。
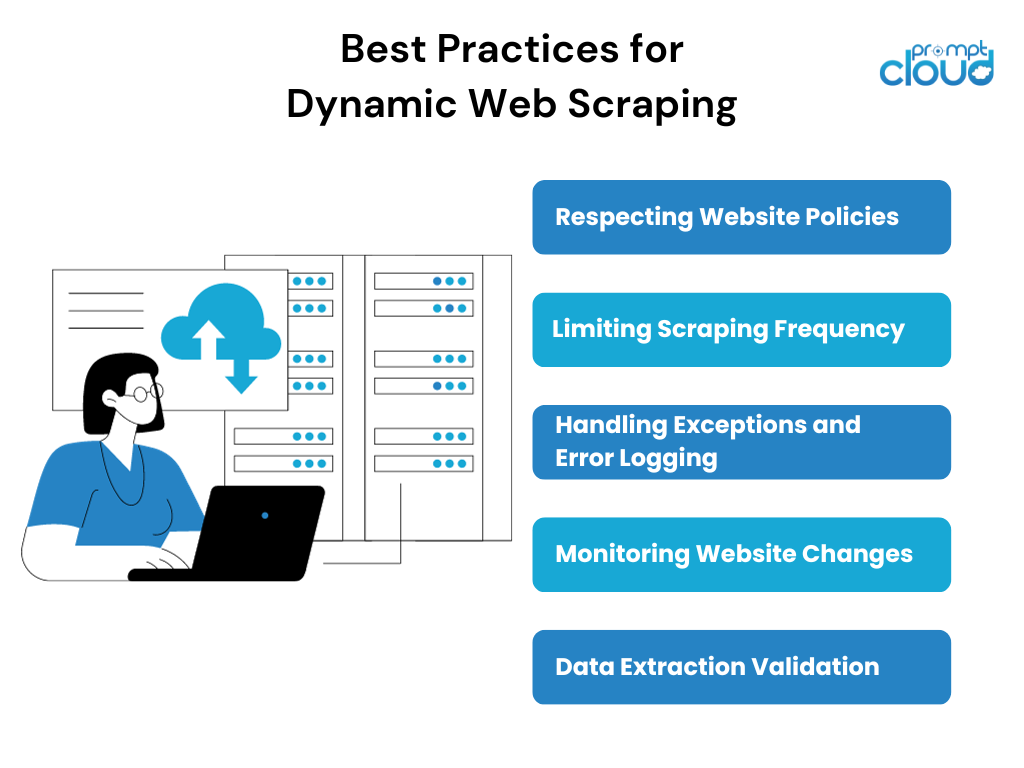
- Web サイトのポリシーの尊重: Webサイトをスクレイピングする前に、Web サイトの利用規約、robots.txt ファイル、および言及されている特定のスクレイピング ガイドラインを確認し、尊重することが不可欠です。
- スクレイピングの頻度を制限する:過剰なスクレイピングは、スクレイパーのリソースとスクレイピングされる Web サイトの両方に負担をかける可能性があります。 合理的なスクレイピング頻度制限を実装し、Web サイトによって設定されたレート制限を尊重することは、調和のとれたスクレイピング プロセスを維持するのに役立ちます。
- 例外の処理とエラー ログ:動的 Web スクレイピングには、ネットワーク エラー、キャプチャ リクエスト、Web サイト構造の変更などの予測不可能なシナリオの処理が含まれます。 適切な例外処理とエラー ログのメカニズムを実装すると、これらの問題を特定して対処するのに役立ちます。
- Web サイトの変更の監視:動的 Web サイトは頻繁に更新や再設計が行われるため、既存のスクレイピング スクリプトが機能しなくなる可能性があります。 ターゲット Web サイトの変更を定期的に監視し、スクレイピング戦略を迅速に調整することで、中断のないデータ抽出が保証されます。
- データ抽出の検証:抽出されたデータを Web サイトのユーザー インターフェイスで検証および相互参照することは、スクレイピングされた情報の正確性と完全性を確保するのに役立ちます。 この検証手順は、進化するコンテンツを含む動的 Web ページをスクレイピングする場合に特に重要です。
結論
動的な Web ページ スクレイピングの力により、動的な Web サイト内に隠された貴重なデータにアクセスする機会が広がります。 動的 Web サイトのスクレイピングに関連する課題を克服するには、技術的な専門知識と倫理的なスクレイピング慣行の遵守を組み合わせる必要があります。
動的な Web ページ スクレイピングの複雑さを理解し、この記事で概説した戦略とベスト プラクティスを実装することで、企業や個人は Web データの可能性を最大限に引き出し、さまざまなドメインで競争力を得ることができます。
動的 Web ページのスクレイピングで遭遇するもう 1 つの課題は、抽出する必要があるデータの量です。 動的な Web ページには大量の情報が含まれることが多く、関連データを効率的に収集して抽出することが困難になります。
このハードルを克服するために、企業は Web スクレイピング サービス プロバイダーの専門知識を活用できます。 PromptCloud の強力なスクレイピング インフラストラクチャと高度なデータ抽出技術により、企業は大規模なスクレイピング プロジェクトを簡単に処理できます。
PromptCloud の支援により、組織は動的な Web ページから貴重な洞察を抽出し、実用的なインテリジェンスに変換できます。 今すぐ PromptCloud と提携して、動的な Web ページ スクレイピングのパワーを体験してください。 sales@promptcloud.com までお問い合わせください。