
Python を使用した動的 Web ページのスクレイピング – ハウツーガイド
公開: 2024-06-08動的 Web スクレイピングには、JavaScript または Python を介してリアルタイムでコンテンツを生成する Web サイトからのデータの取得が含まれます。 静的 Web ページとは異なり、動的コンテンツは非同期で読み込まれるため、従来のスクレイピング手法は非効率的になります。
動的 Web スクレイピングでは次のものが使用されます。
- AJAX ベースの Web サイト
- シングルページ アプリケーション (SPA)
- 遅延読み込み要素のあるサイト
主要なツールとテクノロジー:
- Selenium – ブラウザーの操作を自動化します。
- BeautifulSoup – HTML コンテンツを解析します。
- リクエスト– Web ページのコンテンツを取得します。
- lxml – XML と HTML を解析します。
動的 Web スクレイピング Python では、リアルタイム データを効果的に収集するには、Web テクノロジーをより深く理解する必要があります。
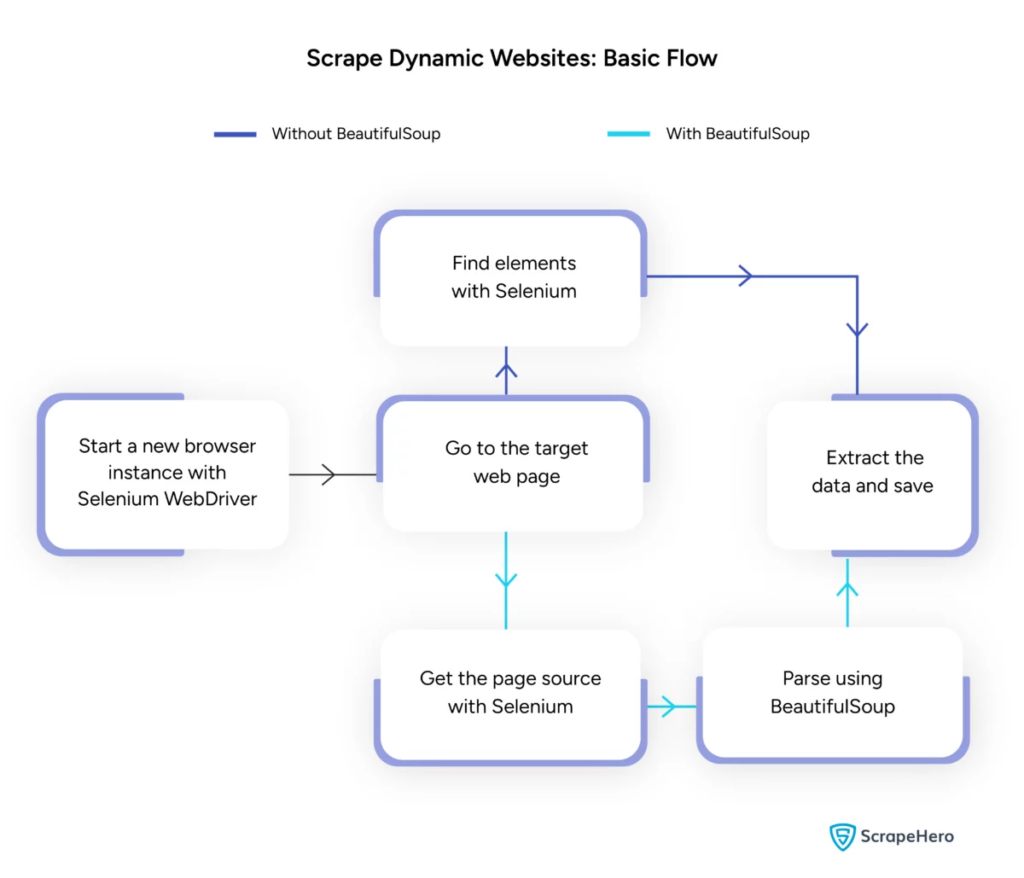
画像出典: https://www.scrapehero.com/scrape-a-dynamic-website/
Python環境のセットアップ
動的 Web スクレイピング Python を開始するには、環境を正しくセットアップすることが不可欠です。 次の手順を実行します:
- Python のインストール: Python がマシンにインストールされていることを確認します。 最新バージョンは Python の公式 Web サイトからダウンロードできます。
- 仮想環境を作成します。

仮想環境をアクティブ化します。

- 必要なライブラリをインストールします。

- コード エディターのセットアップ: スクリプトの作成と実行には、PyCharm、VSCode、Jupyter Notebook などの IDE を使用します。
- HTML/CSS に慣れる: Web ページの構造を理解すると、データを効率的に移動して抽出するのに役立ちます。
これらの手順により、動的な Web スクレイピング Python プロジェクトの強固な基盤が確立されます。
HTTP リクエストの基本を理解する
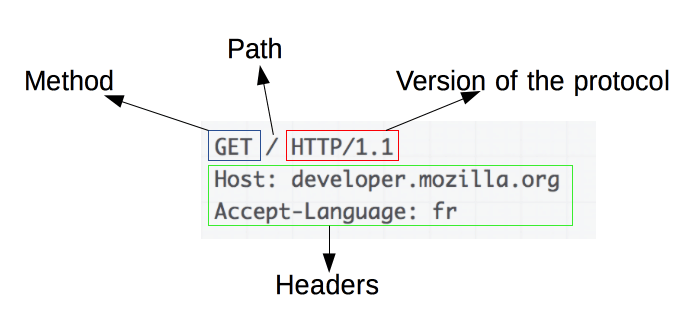
画像ソース: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP リクエストは Web スクレイピングの基礎です。 Web ブラウザや Web スクレイパーなどのクライアントがサーバーから情報を取得したい場合、HTTP リクエストを送信します。 これらのリクエストは特定の構造に従います。
- Method : GET や POST など、実行されるアクション。
- URL : サーバー上のリソースのアドレス。
- ヘッダー: コンテンツ タイプやユーザー エージェントなど、リクエストに関するメタデータ。
- Body : リクエストとともに送信されるオプションのデータ。通常は POST で使用されます。
効果的な Web スクレイピングには、これらのコンポーネントを解釈して構築する方法を理解することが不可欠です。 リクエストのような Python ライブラリはこのプロセスを簡素化し、リクエストを正確に制御できるようにします。
Python ライブラリのインストール
画像ソース: https://ajaytech.co/what-are-python-libraries/
Python を使用した動的 Web スクレイピングの場合は、Python がインストールされていることを確認してください。 ターミナルまたはコマンド プロンプトを開き、pip を使用して必要なライブラリをインストールします。
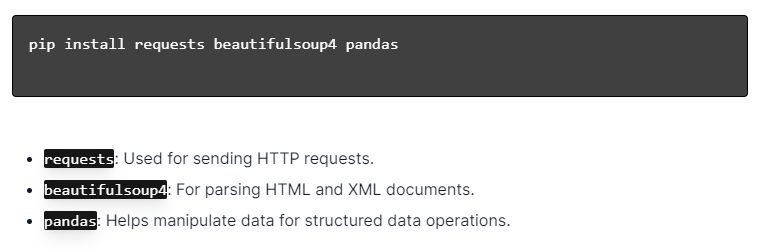
次に、これらのライブラリをスクリプトにインポートします。

これにより、各ライブラリは、リクエストの送信、HTML の解析、データの効率的な管理などの Web スクレイピング タスクに利用できるようになります。
単純な Web スクレイピング スクリプトの構築
Python で基本的な動的 Web スクレイピング スクリプトを構築するには、まず必要なライブラリをインストールする必要があります。 「requests」ライブラリは HTTP リクエストを処理し、「BeautifulSoup」は HTML コンテンツを解析します。

従うべき手順:
- 依存関係をインストールします。

- ライブラリをインポートする:

- HTML コンテンツを取得します。
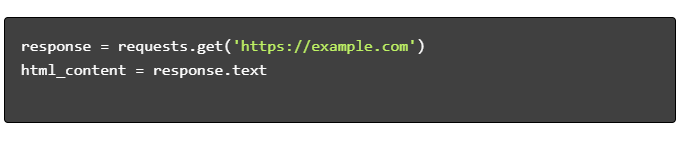
- HTML を解析します。

- データの抽出:

Python を使用した動的 Web スクレイピングの処理
動的な Web サイトはコンテンツをその場で生成しますが、多くの場合、より高度な技術が必要になります。
次の手順を検討してください。
- ターゲット要素の特定: Web ページを検査して動的コンテンツを見つけます。
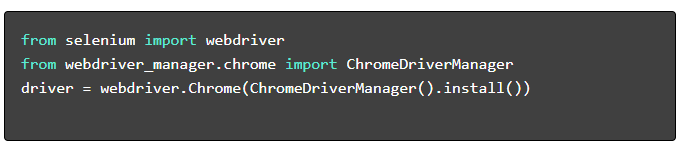
- Python フレームワークを選択する: Selenium や Playwright などのライブラリを利用します。
- 必要なパッケージをインストールします。
- WebDriver のセットアップ:

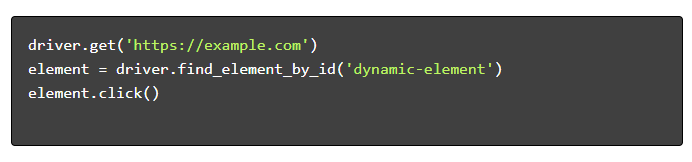
- ナビゲートとインタラクション:
Webスクレイピングのベストプラクティス
効率性と合法性を確保するために、Web スクレイピングのベスト プラクティスに従うことをお勧めします。 以下に重要なガイドラインとエラー処理戦略を示します。
- Robots.txt を尊重する: ターゲット サイトの robots.txt ファイルを常に確認してください。
- スロットリング: サーバーの過負荷を防ぐために遅延を実装します。
- User-Agent : 潜在的なブロックを回避するには、カスタムの User-Agent 文字列を使用します。
- 再試行ロジック: try-excel ブロックを使用し、サーバーのタイムアウトを処理するための再試行ロジックを設定します。
- ロギング: デバッグ用に包括的なログを維持します。
- 例外処理: 特にネットワーク エラー、HTTP エラー、解析エラーを捕捉します。
- キャプチャ検出: CAPTCHA を検出して解決またはバイパスするための戦略を組み込みます。
動的 Web スクレイピングの一般的な課題
キャプチャ
多くの Web サイトでは、自動化されたボットを防ぐために CAPTCHA を使用しています。 これを回避するには:
- 2Captcha などの CAPTCHA 解決サービスを使用します。
- CAPTCHA を解決するために人間の介入を実装します。
- プロキシを使用してリクエスト速度を制限します。
IPブロッキング
サイトでは、リクエストが多すぎる IP をブロックする場合があります。 これに対抗するには次のようにします。
- ローテーションプロキシの使用。
- リクエストのスロットリングを実装します。
- ユーザーとエージェントのローテーション戦略を採用します。
JavaScript のレンダリング
一部のサイトは JavaScript 経由でコンテンツを読み込みます。 この課題には次の方法で対処します。
- ブラウザの自動化に Selenium または Puppeteer を使用する。
- 動的コンテンツのレンダリングに Scrapy-splash を採用。
- JavaScript と対話するためのヘッドレス ブラウザの探索。
法的問題
Web スクレイピングは利用規約に違反する場合があります。 次の方法でコンプライアンスを確保します。
- 法律相談の相談。
- 公的にアクセス可能なデータのスクレイピング。
- robots.txt ディレクティブを尊重します。
データ解析
一貫性のないデータ構造を処理するのは困難な場合があります。 解決策には次のようなものがあります。
- HTML 解析に BeautifulSoup などのライブラリを使用します。
- テキスト抽出に正規表現を使用します。
- 構造化データに JSON および XML パーサーを利用します。
スクレイピングされたデータの保存と分析
スクレイピングされたデータの保存と分析は、Web スクレイピングの重要なステップです。 データの保存場所は、ボリュームと形式によって決まります。 一般的なストレージ オプションには次のものがあります。
- CSV ファイル: 小規模なデータセットや単純な分析に簡単です。
- データベース: 構造化データ用の SQL データベース。 非構造化の NoSQL。
データを保存したら、Python ライブラリを使用して分析を実行できます。
- Pandas : データの操作とクリーニングに最適です。
- NumPy : 数値演算に効率的です。
- Matplotlib と Seaborn : データの視覚化に適しています。
- Scikit-learn : 機械学習用のツールを提供します。
適切なデータストレージと分析により、データへのアクセス性と洞察が向上します。
結論と次のステップ
動的な Web スクレイピング Python を一通り説明したので、強調表示されているツールとライブラリについての理解を微調整することが不可欠です。
- コードを確認する: 最終的なスクリプトを参照し、可能な場合はモジュール化して再利用性を高めます。
- 追加のライブラリ: より複雑なニーズに対応するために、Scrapy や Splash などの高度なライブラリを探索します。
- データ ストレージ: 大規模なデータセットを管理するための SQL データベースまたはクラウド ストレージなど、堅牢なストレージ オプションを検討します。
- 法的および倫理的考慮事項: 潜在的な侵害を避けるために、Web スクレイピングに関する法的ガイドラインを常に最新の状態に保ってください。
- 次のプロジェクト: 複雑さの異なる新しい Web スクレイピング プロジェクトに取り組むことで、これらのスキルがさらに強化されます。
Python を使用したプロフェッショナルな動的 Web スクレイピングをプロジェクトに統合したいと考えていますか? 内部での処理を複雑にすることなく大規模なデータ抽出を必要とするチームのために、PromptCloud はカスタマイズされたソリューションを提供します。 PromptCloud のサービスを探索して、堅牢で信頼性の高いソリューションを見つけてください。 今すぐご連絡ください。