
Rでの探索的因子分析
公開: 2017-02-16Rの探索的因子分析とは何ですか?
探索的因子分析 (EFA)、または R で因子分析として大まかに知られているのは、一連の変数間の潜在的な関係構造を特定し、それを少数の変数に絞り込むために使用される統計手法です。 これは基本的に、多数の変数の分散がいくつかの要約変数、つまり因子によって記述できることを意味します。 R での探索的因子分析の概要を次に示します。
名前が示すように、EFA は本質的に探索的です。潜在変数は実際にはわかりません。因子の数が少なくなるまでステップが繰り返されます。 このチュートリアルでは、R を使用した EFA について説明します。まず、データセットの基本的な考え方を理解しましょう。
1. データ
このデータセットには、自動車の購入時に顧客が考慮する 14 の異なる変数に対する 90 の回答が含まれています。 調査の質問は、1 が非常に低く、5 が非常に高い 5 段階のリッカート スケールを使用して組み立てられました。 変数は次のとおりです。
- 価格
- 安全性
- 外観
- スペースと快適さ
- テクノロジー
- アフターサービス
- 再販価値
- 燃料タイプ
- 燃料効率
- 色
- メンテナンス
- 試乗
- 商品レビュー
- お客様の声
コード化されたデータセットをダウンロードするには、ここをクリックしてください。
2.WebDataのインポート
次に、CSV 形式で存在するデータセットを R に読み取り、変数として格納します。
[code language=”r”] data <- read.csv(file.choose( ),header=TRUE) [/コード]
CSV ファイルを選択するためのウィンドウが開き、`header` オプションにより、ファイルの最初の行がヘッダーと見なされるようになります。 次のように入力して、データ フレームの最初の数行を表示し、データが正しく格納されていることを確認します。
[コード言語=”r”] ヘッド(データ) [/コード]
3. パッケージのインストール
次に、必要なパッケージをインストールして、さらに分析を実行します。 これらのパッケージは `psych` と `GPArotation` です。 以下のコードでは、インストールのために `install.packages()` を呼び出しています。
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/コード]
4. 因子の数
次に、因子分析のために選択する因子の数を調べます。 これを並列解析や固有値などの手法で評価します。
並列分析
Psych パッケージの fa.parallel 関数を使用して並列解析を実行します。 ここでは、データ フレームとファクタ メソッド (この場合は「minres」) を指定します。 以下を実行して許容可能な数の因子を見つけ、「スクリーン プロット」を生成します。
[コード言語 =”r”] 並列 <- fa.parallel(data, fm = 'minres', fa = 'fa') [/コード]
コンソールには、考慮できる要素の最大数が表示されます。 これがどのように見えるかです。
「並列分析は、因子の数 = 5 およびコンポーネントの数 = NA を示唆しています」
上記のコードから生成された `scree plot` を以下に示します。

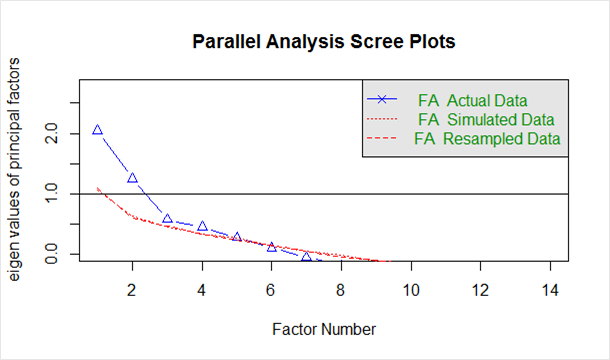
青い線は実際のデータの固有値を示し、2 つの赤い線 (互いに重なっている) はシミュレートされたデータとリサンプリングされたデータを示します。 ここでは、実際のデータの大幅な低下を見て、右側で横ばいになるポイントを見つけます。 また、変曲点、つまりシミュレートされたデータと実際のデータの間のギャップが最小になる傾向がある点を特定します。
このプロットと並列分析を見ると、因子数が 2 ~ 5 の間であればどこでも適切な選択です。
因子分析
因数の推定数に到達したので、因数の数として 3 から始めましょう。 因子分析を実行するために、`psych` パッケージの `fa() 関数を使用します。 以下に、提供する引数を示します。
- r – 生データまたは相関または共分散行列
- nfactors – 抽出する因子の数
- 回転 - 回転にはさまざまな種類がありますが、バリマックスとオブリミンが最も人気があります。
- fm – 「最小残差 (OLS)」、「最大尤度」、「主軸」などの因子抽出手法の 1 つ。
この場合、要因に相関関係があると考えられるため、斜め回転 (rotate = “oblimin”) を選択します。 Varimax 回転は、因子が完全に無相関であるという仮定の下で使用されることに注意してください。 多変量正規分布を仮定せずに「最大尤度」と同様の結果を提供し、主軸のような反復固有分解によって解を導出することが知られているため、「通常の最小二乗/Minres」因数分解 (fm = 「minres」) を使用します。
以下を実行して分析を開始します。
[code language=”r”] threefactor <- fa(data,nfactors = 3,回転 = “oblimin”,fm="minres") print(threefactor) [/コード]
因子と負荷を示す出力は次のとおりです。
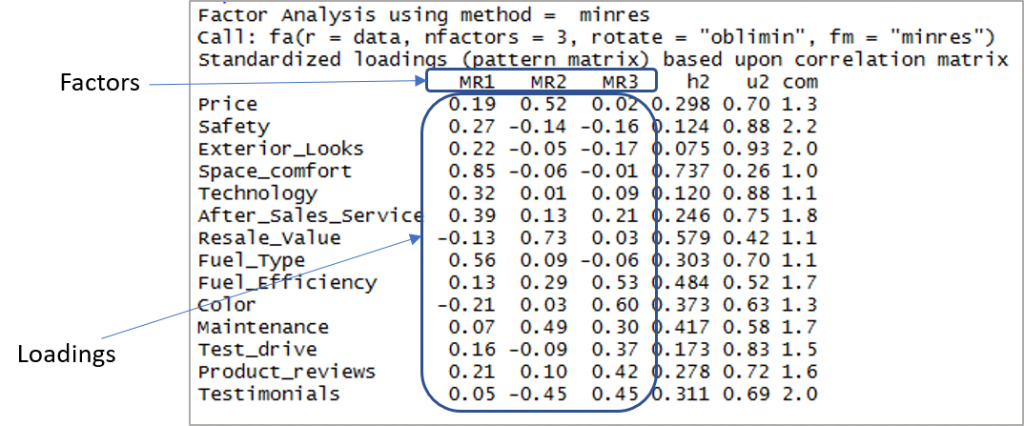
ここで、負荷が 0.3 を超え、複数の因子に負荷がかかっていないことを考慮する必要があります。 ここでは負の値が許容されることに注意してください。 そこで、まずカットオフを確立して視認性を向上させましょう。
[コード language=”r”] print(threefactor$loadings,cutoff = 0.3) [/コード]
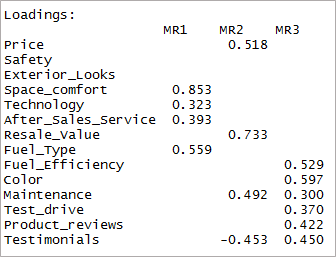
ご覧のように、2 つの変数が重要ではなくなり、他の 2 つの変数が二重読み込みになっています。 次に、「4」の要因を検討します。
[コード言語 =”r”] フォーファクター <- fa(data,nfactors = 4,回転 = “oblimin”,fm=”minres”) print(fourfactor$loadings,cutoff = 0.3) [/コード]
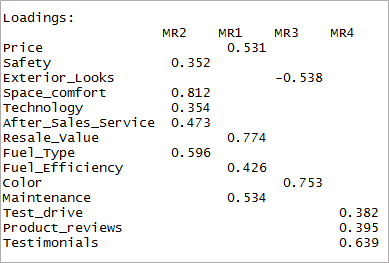
シングルロードのみになることがわかります。 これは単純構造として知られています。
次のようにヒットして、ファクター マッピングを確認します。
[コード言語=”r”] fa.diagram(fourfactor) [/コード]
妥当性テスト
単純な構造を達成したので、今度はモデルを検証します。 先に進むために、因子分析の出力を見てみましょう。

根は、残差の二乗 (RMSR) が 0.05 であることを意味します。 この値は 0 に近いはずなので、これは許容できます。次に、RMSEA (近似の二乗平均平方根誤差) インデックスを確認する必要があります。 その値 0.001 は、0.05 未満であるため、モデルが適切に適合していることを示しています。 最後に、Tucker-Lewis Index (TLI) は 0.93 で、0.9 を超えていることを考えると許容値です。
要因の命名

因子の妥当性を確立したら、因子に名前を付けます。 これは、変数の負荷に応じて因子を形成する分析の理論的な側面です。 この場合、因子を作成する方法は次のとおりです。
結論
r での分析に関するこのチュートリアルでは、EFA (R での探索的因子分析) の基本的な考え方、並列分析、およびスクリー プロットの解釈について説明しました。 次に、R での因子分析に移り、単純な構造を実現し、同じ構造を検証してモデルの妥当性を確認しました。 最後に、変数から因子の名前にたどり着きました。 さあ、試してみて、コメント セクションに結果を投稿してください。