
Webスクレイピング入門: ツールとテクニック
公開: 2023-09-13Web スクレイピングは、Web サイトからデータを自動的に抽出するプロセスです。 さまざまな目的で情報を収集しようとしているデータ アナリスト、研究者、企業にとって不可欠なスキルとなっています。 この記事では、Web スクレイピングの概要、Web スクレイピングが提供する利点、利用可能なさまざまなツール、基本的なテクニックと高度なテクニック、一般的な課題、Web スクレイピングを始めるときに従うべきベスト プラクティスについて説明します。
Webスクレイピングを理解する
Web スクレイピングには、HTTP リクエストを Web サイトに送信し、HTML コンテンツを解析して、必要なデータを抽出することが含まれます。 Web ページからテキスト、画像、表、リンクなどの情報を取得できます。 Web スクレイピングは、データ抽出、データ分析、競合情報、監視に一般的に使用されます。
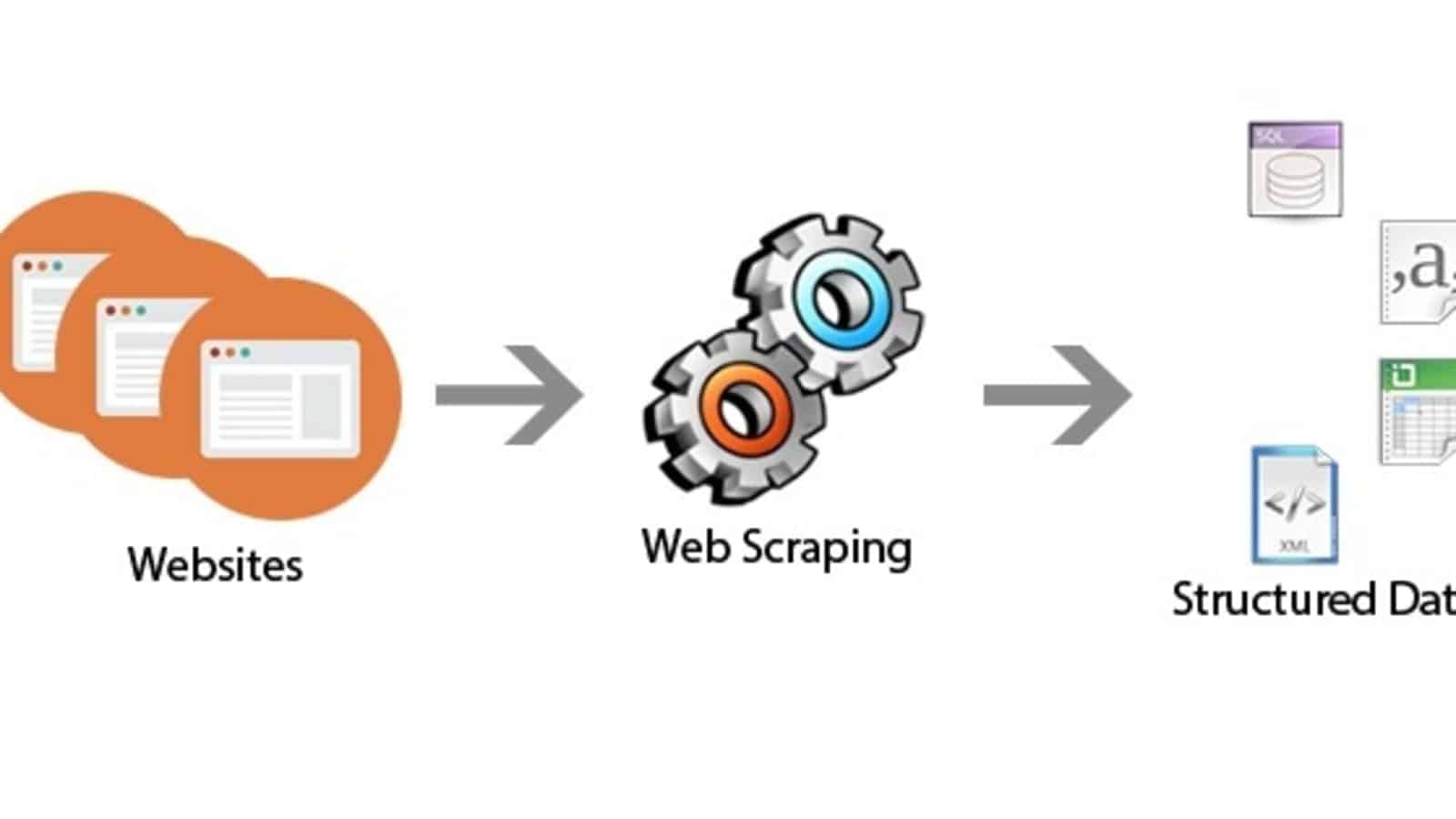
Webスクレイピングのメリット
Web スクレイピングには、次のような多くの利点があります。
- データ収集: Web スクレイピングを使用すると、複数のソースから大量のデータを迅速かつ効率的に収集できます。
- 自動データ抽出: Web サイトからデータを手動でコピーして貼り付ける代わりに、Web スクレイピングによってデータ抽出プロセスが自動化されます。
- リアルタイム データ: Web スクレイピングを使用すると、Web サイトからリアルタイム データにアクセスでき、最新の情報を確実に入手できます。
- 競合分析: Web スクレイピングを使用すると、競合 Web サイトを監視し、ビジネス分析のための貴重なデータを抽出できます。
- 研究と分析: Web スクレイピングは、分析と洞察のためのデータを収集するための強力なツールを研究者に提供します。
適切な Web スクレイピング ツールの選択
Web スクレイピング プロジェクトを成功させるには、適切な Web スクレイピング ツールを選択することが重要です。 考慮すべき一般的なツールをいくつか示します。
- Beautiful Soup: HTML および XML ファイルを解析するための Python ライブラリ。 Web ページからデータを移動、検索、抽出するためのシンプルかつ柔軟な手段を提供します。
- Selenium: Web スクレイピングにも使用できる Web テスト ツール。 これにより、コンテンツのレンダリングに JavaScript に大きく依存する Web サイトとの対話が可能になります。
適切な Web スクレイピング ツールを選択するときは、プログラミング言語への習熟度、プロジェクトの複雑さ、特定の要件などの要素を考慮してください。
基本的な Web スクレイピング テクニック
Web スクレイピングを始めるときは、Web ページからデータを抽出する基本的なテクニックから始めることができます。 一般的に使用されるいくつかのテクニックを次に示します。

- HTML 解析: Beautiful Soup や lxml などの HTML 解析ライブラリを使用して、Web ページの HTML 構造をナビゲートし、関連データを抽出します。
- XPath および CSS セレクター: XPath または CSS セレクターを使用して、Web ページ上の特定の要素を識別し、そのコンテンツを取得します。
- API 統合: 一部の Web サイトでは、HTML をスクレイピングする必要がなく、構造化された形式でデータにアクセスして抽出できる API (アプリケーション プログラミング インターフェイス) を提供しています。
Web サイトをスクレイピングする前に、Web サイトの利用規約を確認し、スクレイピング活動が合法的かつ倫理的であることを確認する必要があることに注意することが重要です。
高度な Web スクレイピング技術
Web スクレイピングに習熟すると、より複雑なスクレイピング シナリオを処理するための高度なテクニックを探索できるようになります。 高度なテクニックには次のようなものがあります。
- JavaScript の処理: JavaScript を使用してコンテンツを動的にロードする Web サイトでは、データを効果的に収集するために Selenium などのツールが必要です。
- ページネーションと無限スクロール: ページネーションされたコンテンツや無限スクロールのあるページを扱う場合は、ユーザー操作をシミュレートして複数のページからデータを抽出する必要があります。
- セッション管理: 一部の Web サイトでは、Cookie の処理やログイン状態の維持などのセッション管理が必要です。 Scrapy のようなツールには、これらのシナリオを処理するための機能が組み込まれています。
高度な Web スクレイピング技術を習得することで、さまざまな課題を克服し、最も複雑な Web サイトからでもデータを効率的にスクレイピングできます。
Webスクレイピングにおける一般的な課題

Web スクレイピングには多くの利点がありますが、特定の課題もあります。 Web スクレイピング中に直面する一般的な課題には次のようなものがあります。
- Web サイトの構造の変更: Web サイトでは HTML 構造が頻繁に変更されるため、既存の Web スクレイピング スクリプトが機能しなくなる可能性があります。 この課題を軽減するには、スクレイピング スクリプトの定期的なメンテナンスと監視が必要です。
- キャプチャと IP ブロック: Web サイトでは、スクレイピングを防止するために、キャプチャを実装したり、IP アドレスに基づいてアクセスを制限したりする場合があります。 これらの課題を克服するには、プロキシの使用、IP アドレスのローテーション、または機械学習技術の採用が必要になる場合があります。
- データ抽出の複雑さ: 一部の Web サイトでは、JavaScript レンダリングや AJAX などの複雑な技術を使用してデータをロードしているため、スクレイピング プロセスがより困難になります。 このようなシナリオを処理するには、可能な限り Selenium などのツールを使用するか、API を利用してください。
これらの課題を認識し、それに取り組むための戦略を立てることは、Web スクレイピング プロジェクトを成功させるのに役立ちます。
Webスクレイピングのベストプラクティス
スムーズかつ倫理的な Web スクレイピングを確保するには、ベスト プラクティスに従うことが不可欠です。 以下にいくつかのガイドラインを示します。
- Web サイトのポリシーを尊重する: Web サイトの利用規約を常に確認し、スクレイピングのガイドラインや制限に従ってください。
- サーバーの過負荷を回避する: サーバーの過負荷を回避し、Web サイトの帯域幅を尊重するために、リクエストのスクレイピングに遅延を実装します。
- 変更を追跡する: スクレイピングされた Web サイトを定期的に監視し、スクレイピング スクリプトの変更が必要となる可能性のある構造またはデータの変更がないか確認します。
- エラーを適切に処理する: Web スクレイピング中に発生する可能性のあるエラーや例外を処理するエラー処理メカニズムを実装します。
- 最新の情報を入手: 最新の Web スクレイピング技術、慣行、および法的考慮事項を常に把握し、効率的でコンプライアンスに準拠したスクレイピングを確保します。
これらのベスト プラクティスに従うと、Web サイトを効率的にスクレイピングできるだけでなく、データを抽出する Web サイトとの良好な関係を維持することもできます。
結論
Web スクレイピングは、Web サイトからデータを収集し、洞察を得る強力なツールです。 適切なツールを選択し、基本的および高度なテクニックを理解し、一般的な課題に対処し、ベスト プラクティスに従うことで、Web スクレイピングを効果的に活用できます。 常に Web サイトのポリシーを尊重し、最新の技術を常に最新の状態に保ち、データ抽出を責任を持って処理することを忘れないでください。 適切なアプローチを使用すれば、Web スクレイピングはさまざまなアプリケーションや業界に貴重なリソースを提供できます。