
AI によるコンテンツのクロールをブロックする方法
公開: 2023-10-24Google Bard や Bing Chat などの AI 生成ツールは、Web を含む多くのコンテンツ ソースから構築されています。 多くの人が驚いたことに、検索エンジンは従来の Web 検索でクロール中に見つけたすべてのコンテンツに対して AI モデルを静かにトレーニングしてきました。
Bing と Google は、Web 検索用にインデックスを作成したままにして、コンテンツが AI トレーニングに使用されるのをブロックする方法を発表しました。
では、AI をブロックする必要がありますか?どうすればよいでしょうか?
- AI をブロックする必要がありますか?
- AI ボットをブロックするにはどうすればよいですか?
- Bing の AI をブロックする方法
- GoogleのAIをブロックする方法
- ChatGPTをブロックする方法
- テスト
AI をブロックする必要がありますか?
独自の製品を製造する企業は、自社のコンテンツを AI モデルに含めることが利点であると考えるかもしれません。 技術仕様や製品サポートなどの情報は、販売やカスタマー サポート コストの削減に役立つ場合があります。
しかし、他の多くのオンライン ビジネスにとって、コンテンツは製品です。 コンテンツの作成に投資されたエネルギーが、トラフィックという形で何の価値も提供することなく、大手テクノロジー企業が所有する AI 製品の改良に使用されるのではないかという懸念は当然あります。
GoogleとBingは、ソースをクレジットし、参照トラフィックを配信する方法を見つけようとしているが、従来のWeb検索よりも少なくなり、情報検索クエリよりもトランザクション的なものになる可能性が高い。
これらの AI からのコンテンツをブロックしても、クロール動作には影響しないことに注意することが重要です。 Googleは、「robots.txtのユーザーエージェントトークンは制御機能で使用されている」と述べています。 サイトはボットによって通常どおりクロールされ、検索インデックスが構築されます。
また、検索エンジンが特定のページのクロールをすでにブロックされている場合は、AI に対して特にブロックする必要はありません。
AI ボットをブロックするにはどうすればよいですか?
現在、ほとんどの SEO によく知られている方法、robots.txt ファイルとページレベルのロボット ディレクティブを使用して、Google、Bing、ChatGPT をブロックすることが可能です。
Google と ChatGPT は URL パターンを指定できる robots.txt メソッドを選択し、Bing は個々のページに適用される robots ディレクティブの使用を選択しました。
robots.txt には、Web サイト全体を 1 か所で簡単に構成できるという利点があります。 すべての単一ページを取得してテストする必要があるページ レベルのロボット ディレクティブと比較して、どの URL がブロックされているかは非常に透明です。
Bing の AI をブロックする方法
Bing は、nocache または noarchive ロボット ディレクティブを検索します。これらは、メタ タグとして、または X-Robots-Tag 応答ヘッダーとしてページに追加できます。
Nocache を使用すると、Microsoft の AI モデルのトレーニングで URL、タイトル、スニペットのみを使用して、Bing Chat の回答にページを含めることができます。
Noarchive では、Bing Chat にページを含めることは許可されておらず、Microsoft の AI モデルのトレーニングにコンテンツが使用されることはありません。
ページに Nocache と Noarchive の両方がある場合は、制限の少ない Nocache が優先されます。
「 robots 」トークンはディレクティブをすべてのクローラーに適用します。 これには、検索結果にキャッシュされたリンクとともにページが表示されないようにする Google も含まれます。
<meta name=”ロボット” content=”noarchive”>
他の検索エンジンへの影響を避けるために、より具体的な「 bingbot 」または「 msnbot 」トークンを使用できます。
<meta name=”bingbot” content=”nocache”>
GoogleのAIをブロックする方法
Google は、Bard および同等の Vertex API で使用したくないページに一致する URL パターンを指定できる robots.txt メソッドを選択しました。 現在、これは Search Generative Experience (SGE) には適用されません。
これらは、Google 拡張のユーザー エージェント トークンと照合されます。 トークンの大文字と小文字は関係ありません。
ユーザーエージェント: Google-Extended
許可しない: /
Google 拡張トークン専用のルール ブロックがない場合は、ワイルドカード トークン (*) と照合されます。
ユーザーエージェント: *
許可しない: /
Googlebot 用の特定のルール ブロックと、別個のワイルドカード ブロックがある場合は注意してください。 Google 拡張は、Googlebot ブロックではなく、ワイルドカード ブロックと一致します。
ユーザーエージェント: Googlebot
許可する: /
ユーザーエージェント: *

許可しない: /
より正確にルールをブロックする前に、複数のユーザー エージェントをリストすることができます。
ユーザーエージェント: Google-Extended
ユーザーエージェント: Googlebot
許可する: /
ユーザーエージェント: *
許可しない: /
ChatGPTをブロックする方法
ChatGPT は robots.txt 方式も選択しました。
Chat GPT には、ChatGPT ユーザーに代わってクエリを実行する ChatGPT-User と、モデルの構築に使用される OpenAI の Web クローラーである GPTBot という 2 つの異なるユーザー エージェント トークンがあります。
現在、オプトアウト システムは両方のユーザー エージェントを同じように扱うため、1 つのエージェントを禁止する robots.txt は両方をカバーします。 これは将来変更される可能性があるため、個別にブロックすることをお勧めします。
ユーザーエージェント: GPTBot
ユーザーエージェント: ChatGPT ユーザー
許可しない: /
テスト
Web サイト全体をブロックしている場合、テストは簡単です。
Google と ChatGPT がブロックされているかどうかを確認するには、robots.txt にブロックしたいボットに対するすべてを禁止するルールがあるかどうかを確認する必要があります。
ユーザーエージェント: Google-Extended
ユーザーエージェント: GPTbot
許可しない: /
一部の URL のみをブロックしたい場合は、より複雑な robots.txt ディレクティブのセットが必要になる場合があります。 ブロックされると予想される URL とブロックされない URL をいくつかテストすることを検討してください。
Tom は、robots.txt で特定の URL がブロックされているかどうかをテストするのに役立つ無料の robots.txt ツールです。 URL のリストの形式でテストを定義し、各 URL に対して予想される不許可ステータスを定義できます。
Google-Extended、GPTBot、および ChatGPT-User ユーザー エージェント トークンを使用して構成すると、それぞれでブロックされている URL と、それが予想されるテスト結果と一致するかどうかを表示できます。
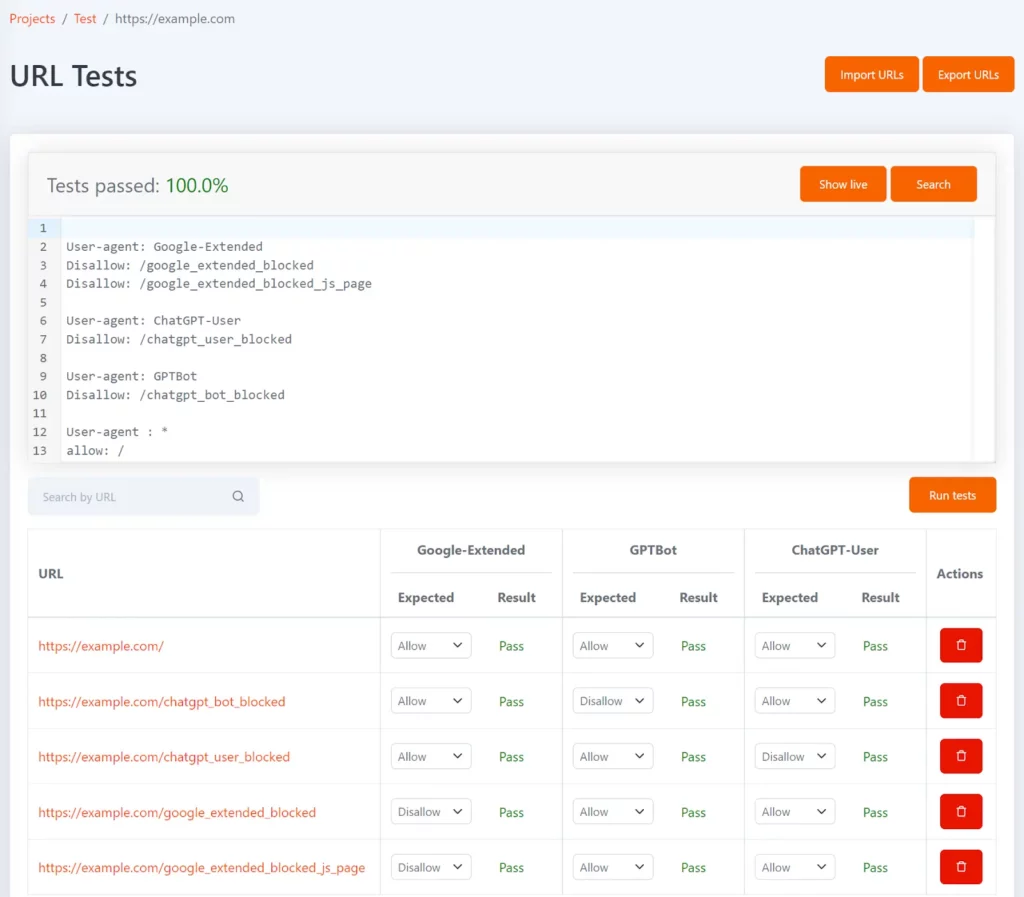
robots.txt ファイルが更新されるたびにテストが再実行され、結果が予期したものと一致しない場合は通知されます。
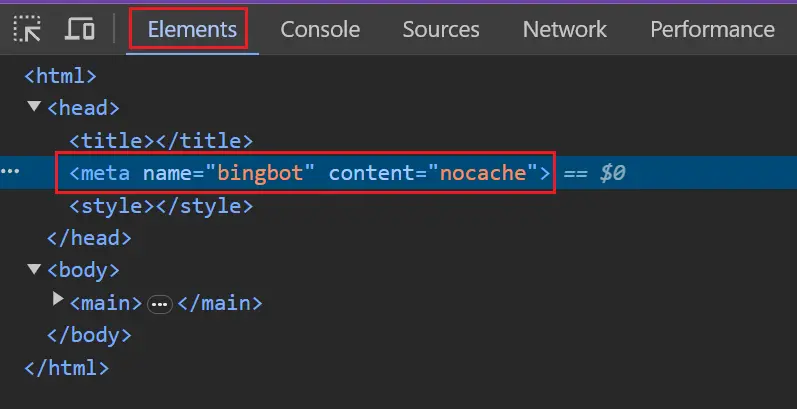
Bing がブロックされているかどうかをテストするには、ブラウザーで主要なページ テンプレートを検査し、ロボット タグがあることを確認します。
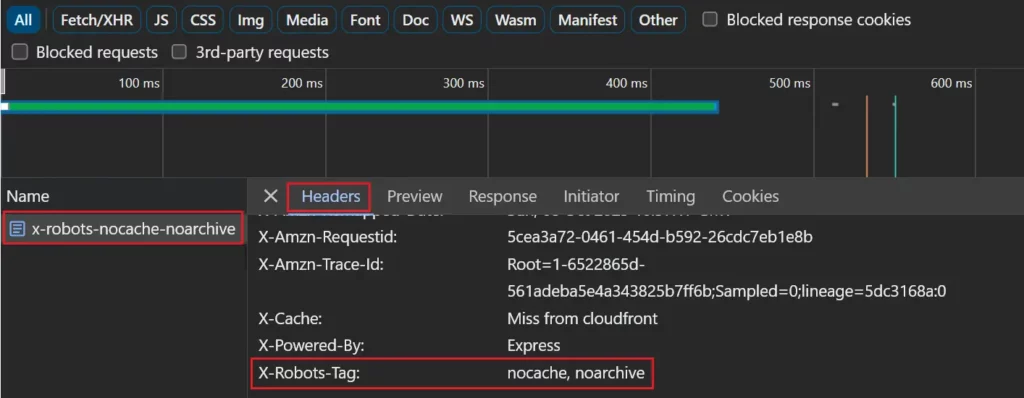
X-Robots-Tag 応答ヘッダーを使用している場合は、ネットワーク リクエストのリストでページを選択し、[ヘッダー] タブを表示すると、ネットワーク タブで確認できます。
特定のページ セットをブロックしている場合、テストはより複雑になりますが、役立つツールがいくつかあります。
Lumar クローラーは、Google と Bing の AI がブロックされているすべてのページを自動的に報告するようになりました。
追加の技術サポートが必要ですか? Semetrical のテクノロジー提供について詳しく知るか、詳細についてお問い合わせください。