
Web ページ スクレイパーをマスターする: オンライン データを抽出するための初心者ガイド
公開: 2024-04-09Web ページ スクレイパーとは何ですか?
Web ページ スクレイパーは、Web サイトからデータを抽出するために設計されたツールです。 人間のナビゲーションをシミュレートして、特定のコンテンツを収集します。 初心者は、市場調査、価格監視、機械学習プロジェクトのデータ編集など、さまざまなタスクにこれらのスクレーパーを活用することがよくあります。
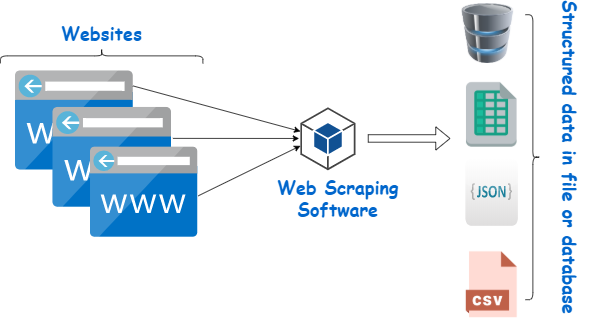
画像ソース: https://www.webharvy.com/articles/what-is-web-scraping.html
- 使いやすさ:ユーザーフレンドリーなので、最小限の技術スキルを持つ個人でも Web データを効果的にキャプチャできます。
- 効率:スクレーパーは大量のデータを迅速に収集でき、手動によるデータ収集作業をはるかに上回ります。
- 精度:自動スクレイピングにより人的エラーのリスクが軽減され、データの精度が向上します。
- 費用対効果が高い:手動入力の必要性がなくなり、人件費と時間を節約できます。
Web ページ スクレイパーの機能を理解することは、Web データの力を活用しようとしている人にとって非常に重要です。
Python を使用した単純な Web ページ スクレイパーの作成
Python で Web ページ スクレーパーの作成を開始するには、特定のライブラリ、つまり Web ページに対して HTTP リクエストを行うためのリクエストと、HTML および XML ドキュメントを解析するための bs4 の BeautifulSoup をインストールする必要があります。
- 収集ツール:
- ライブラリ:リクエストを使用して Web ページを取得し、BeautifulSoup を使用してダウンロードされた HTML コンテンツを解析します。
- Web ページをターゲットにする:
- スクレイピングするデータを含む Web ページの URL を定義します。
- コンテンツのダウンロード:
- リクエストを使用して、Web ページの HTML コードをダウンロードします。
- HTML を解析します。
- BeautifulSoup は、ダウンロードした HTML を、簡単にナビゲーションできるように構造化された形式に変換します。
- データの抽出:
- 必要な情報を含む特定の HTML タグを特定します (<div> タグ内の製品タイトルなど)。
- BeautifulSoup メソッドを使用して、必要なデータを抽出して処理します。
スクレイピングしたい情報に関連する特定の HTML 要素をターゲットにすることを忘れないでください。
Web ページをスクレイピングするための段階的なプロセス
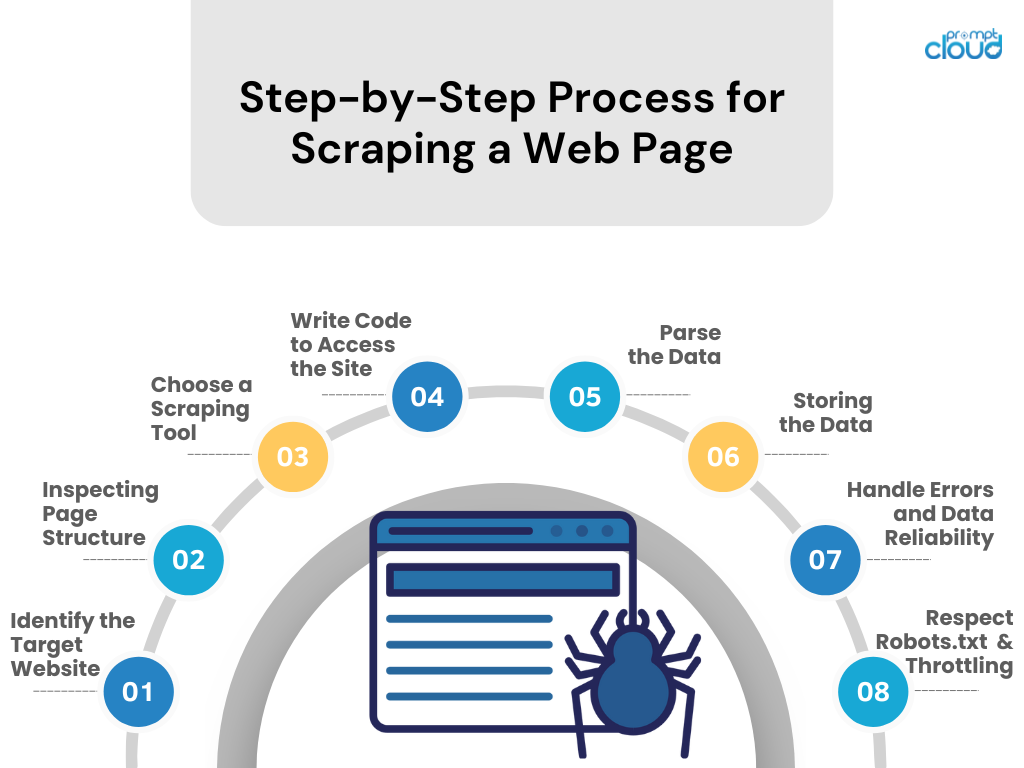
- ターゲット Web サイトを特定する
スクレイピングしたいWebサイトを調べます。 そうすることが合法的かつ倫理的であることを確認してください。 - ページ構造の検査
ブラウザの開発者ツールを使用して、HTML 構造、CSS セレクター、および JavaScript 駆動のコンテンツを調べます。 - スクレイピングツールを選択する
使い慣れたプログラミング言語 (Python の BeautifulSoup や Scrapy など) のツールまたはライブラリを選択します。 - サイトにアクセスするためのコードを作成する
利用可能な場合は API 呼び出し、または HTTP リクエストを使用して、Web サイトからデータをリクエストするスクリプトを作成します。 - データを解析する
HTML/CSS/JavaScript を解析して、Web ページから関連データを抽出します。 - データの保存
スクレイピングしたデータを CSV、JSON などの構造化形式で保存するか、データベースに直接保存します。 - エラーの処理とデータの信頼性
エラー処理を実装して、リクエストの失敗を管理し、データの整合性を維持します。 - Robots.txt とスロットリングを尊重する
サイトの robots.txt ファイルのルールに従い、リクエスト レートを制御してサーバーに負荷がかかることを避けてください。
ニーズに合わせた理想的な Web スクレイピング ツールの選択
Web をスクレイピングするときは、自分の習熟度や目標に合ったツールを選択することが重要です。 初心者は次の点を考慮する必要があります。

- 使いやすさ:視覚的な支援と明確なドキュメントを備えた直感的なツールを選択します。
- データ要件:ターゲット データの構造と複雑さを評価して、単純な拡張が必要か堅牢なソフトウェアが必要かを判断します。
- 予算:コストと機能を比較検討します。 多くの効果的なスクレイパーは無料枠を提供しています。
- カスタマイズ:ツールが特定のスクレイピングのニーズに適応できるようにします。
- サポート:役立つユーザー コミュニティへのアクセスは、トラブルシューティングと改善に役立ちます。
スムーズなスクレイピングを実現するには、賢明に選択してください。
Web ページ スクレイパーを最適化するためのヒントとコツ
- Python の BeautifulSoup や Lxml などの効率的な解析ライブラリを使用して、HTML 処理を高速化します。
- ページの再ダウンロードを回避し、サーバーの負荷を軽減するためにキャッシュを実装します。
- robots.txt ファイルを尊重し、レート制限を使用して、対象の Web サイトによって禁止されないようにします。
- ユーザー エージェントとプロキシ サーバーをローテーションして人間の動作を模倣し、検出を回避します。
- Web サイトのパフォーマンスへの影響を最小限に抑えるために、オフピーク時間にスクレイパーをスケジュールします。
- API エンドポイントが利用可能な場合は、構造化データを提供し、一般に効率が高いため、API エンドポイントを選択します。
- クエリを選択して不要なデータのスクレイピングを回避し、必要な帯域幅とストレージを削減します。
- Web サイト構造の変更に適応し、データの整合性を維持するために、スクレイパーを定期的に更新してください。
Web ページのスクレイピングにおける一般的な問題の処理とトラブルシューティング
Web ページ スクレイパーを使用する場合、初心者はいくつかの一般的な問題に直面する可能性があります。
- セレクターの問題: セレクターが Web ページの現在の構造と一致していることを確認してください。 ブラウザ開発者ツールなどのツールは、正しいセレクターを特定するのに役立ちます。
- 動的コンテンツ: 一部の Web ページは、JavaScript を使用してコンテンツを動的に読み込みます。 このような場合は、ヘッドレス ブラウザまたは JavaScript をレンダリングするツールの使用を検討してください。
- ブロックされたリクエスト: Web サイトがスクレイパーをブロックする場合があります。 ユーザー エージェントのローテーション、プロキシの使用、robots.txt の尊重などの戦略を採用して、ブロックを軽減します。
- データ形式の問題: 抽出されたデータはクリーニングまたはフォーマットする必要がある場合があります。 正規表現と文字列操作を使用してデータを標準化します。
具体的なトラブルシューティングのガイダンスについては、必ずドキュメントとコミュニティ フォーラムを参照してください。
結論
初心者でも Web ページ スクレーパーを使用して Web からデータを簡単に収集できるようになり、調査と分析がより効率的になります。 法的および倫理的な側面を考慮しながら適切な方法を理解することで、ユーザーは Web スクレイピングの可能性を最大限に活用することができます。 貴重な洞察と情報に基づいた意思決定が満載された Web ページ スクレイピングをスムーズに導入するには、次のガイドラインに従ってください。
よくある質問:
ページのスクレイピングとは何ですか?
データ スクレイピングまたは Web ハーベスティングとも呼ばれる Web スクレイピングは、人間のナビゲーション動作を模倣するコンピューター プログラムを使用して Web サイトからデータを自動的に抽出することで構成されます。 Web ページ スクレーパーを使用すると、膨大な量の情報を手動で編集するのではなく、重要なセクションのみに焦点を当てて迅速に分類できます。
企業は、コストの調査、評判の管理、傾向の分析、競合分析の実行などの機能に Web スクレイピングを適用します。 Web スクレイピング プロジェクトを実装するには、訪問した Web サイトが関連するすべての robots.txt および no-follow プロトコルのアクションと遵守を承認していることを確認することが保証されます。
ページ全体をスクレイピングするにはどうすればよいですか?
Web ページ全体をスクレイピングするには、通常 2 つのコンポーネントが必要です。Web ページ内で必要なデータを見つける方法と、そのデータを別の場所に保存するメカニズムです。 多くのプログラミング言語、特に Python と JavaScript が Web スクレイピングをサポートしています。
どちらにもさまざまなオープンソース ライブラリが存在し、プロセスをさらに簡素化します。 Python 開発者の間で人気のある選択肢には、BeautifulSoup、Requests、LXML、Scrapy などがあります。 あるいは、ParseHub や Octoparse などの商用プラットフォームを使用すると、技術に詳しくない人でも複雑な Web スクレイピング ワークフローを視覚的に構築できます。 必要なライブラリをインストールし、DOM 要素の選択の背後にある基本概念を理解したら、ターゲット Web ページ内で関心のあるデータ ポイントを特定することから始めます。
ブラウザ開発者ツールを利用して HTML タグと属性を検査し、これらの結果を、選択したライブラリまたはプラットフォームでサポートされている対応する構文に変換します。 最後に、CSV、Excel、JSON、SQL、またはその他のオプションの出力形式の設定と、データの保存先を指定します。
Google スクレーパーの使用方法を教えてください。
一般に信じられていることに反して、Google は複数の製品とのシームレスな統合を促進する API と SDK を提供しているにもかかわらず、パブリック Web スクレイピング ツール自体を直接提供していません。 それにもかかわらず、熟練した開発者は、Google のコア テクノロジーをベースに構築されたサードパーティ ソリューションを作成し、ネイティブ機能を超えて機能を効果的に拡張してきました。 例としては、SerpApi が挙げられます。SerpApi は、Google Search Console の複雑な側面を抽象化し、キーワード ランキングの追跡、オーガニック トラフィックの推定、バックリンクの探索のための使いやすいインターフェイスを提供します。
従来の Web スクレイピングとは技術的に異なりますが、これらのハイブリッド モデルは従来の定義を分ける境界線を曖昧にします。 他の例では、Google Maps Platform、YouTube Data API v3、または Google Shopping Services を駆動する内部ロジックの再構築に適用されたリバース エンジニアリングの取り組みが紹介されており、さまざまな程度の合法性と持続可能性のリスクにさらされているにもかかわらず、元の対応物に著しく近い機能が得られています。 最終的に、意欲的な Web ページ スクレーパーは、特定の経路に取り組む前に、さまざまなオプションを検討し、特定の要件に関連したメリットを評価する必要があります。
Facebookスクレーパーは合法ですか?
Facebook 開発者ポリシーに記載されているように、無許可の Web スクレイピングはコミュニティ標準への明らかな違反となります。 ユーザーは、指定された API レート制限を回避または超過するように設計されたアプリケーション、スクリプト、またはその他のメカニズムを開発または操作しないこと、またサイトまたはサービスのいかなる側面も解読、逆コンパイル、またはリバース エンジニアリングしようとしないことに同意します。 さらに、データ保護とプライバシーに関する期待を強調し、許可されたコンテキスト外で個人を特定できる情報を共有する前にユーザーの明示的な同意を要求します。
概説された原則を遵守しない場合は、警告から始まり、重大度レベルに応じてアクセス制限または特権の完全な剥奪に向けて段階的に懲戒処分が段階的に進められます。 承認されたバグ報奨金プログラムに基づいて活動しているセキュリティ研究者には例外が設けられているにもかかわらず、不必要な複雑化を回避するために未承認の Facebook スクレイピング活動を避けることを支持する一般的な意見が一致しています。 代わりに、プラットフォームによって承認された一般的な規範や慣例と互換性のある代替案を追求することを検討してください。