
テクニカルSEOとは何ですか?
公開: 2023-09-01SEO を学び始めると、成功するには理解する必要のあるさまざまな側面があることにすぐに気づくでしょう。
オンページSEOからオンページSEO、コンテンツ制作まで。 Web サイトを必要な位置にランキングするには、SEO 内での特定の役割に関係なく、すべてをしっかりと把握する必要があります。
この記事では、技術的な SEO について説明します。 それが何であるか、Web サイトにとって重要な理由、技術的な観点から適切に最適化された Web サイトの特徴を正確に学びます。
また、クロールやインデックス作成からランキングまで、SEO の技術的な仕組みについての「概要」と、これら 3 つのステップをうまく連携させるために必要なものについても説明します。

画像クレジット: https://tsh.io/
テクニカルSEOとは何ですか?
テクニカル SEO は、Web サイトの「舞台裏」要素を最適化して、Google や Bing などの検索エンジンでのパフォーマンスを向上させるプロセスです。 このプロセスには、Googlebot などの検索エンジン ボットによるクロール、インデックス作成、ランキング (これについては後で詳しく説明します) を容易にするために、Web サイトのマークアップや構造を強化するなどの手順が含まれます。 タスクには、Web サイトの速度の改善、シンプルでわかりやすいサイト アーキテクチャの作成、「SEO フレンドリー」な URL の使用、充実した検索結果のためのスキーマ マークアップの適用などが含まれます。
基本的に、テクニカル SEO は、Web サイトのランキングを上げるプロセスにおいて検索エンジンを支援する強力な基盤を作成します。 これは最終的にオーガニック トラフィックの増加とユーザー エクスペリエンスの向上につながります。
Web サイトは、よく整理されたライブラリであると考えてください。 テクニカル SEO は、明確なタグ (URL 構造) を付けて本をきちんと棚に並べ、スムーズなナビゲーションのための標識を設定し (内部リンク)、歓迎的な雰囲気 (サイトの速度) を作り出すステップです。 図書館が整然としていて魅力的であれば、より多くの訪問者が必要な本を見つけることができ(ユーザーがコンテンツを発見する)、図書館員(検索エンジンボット)が本を分類して提案することができます(インデックス付けとランキング)。
なぜテクニカルSEOが重要なのでしょうか?
テクニカル SEO は、Web サイトの検索エンジンの可視性と全体的なパフォーマンスの基盤を形成するため、大部分の Web サイトにとって非常に重要です。 もちろん、公開するコンテンツは重要ですが、技術的に適切に最適化されていないと、検索エンジンがそのコンテンツを効果的に検出、インデックス付け、ランク付けできなくなる可能性があります。
テクニカル SEO の重要性は次のように要約できます。
まず、検索エンジンがコンテンツを効果的にクロールしてインデックスを作成できるようになります。 テクニカル SEO は、Web サイトの構造やナビゲーションなどの要素を最適化することで、検索エンジン ボットによる Web サイトのスムーズなクロールを促進します。 このアクセシビリティは、コンテンツが注目され、適切にインデックス付けされるようにするために不可欠です。
少し偏見があるかもしれませんが、私たちの Web サイトは、優れたアーキテクチャを備えたサイトの好例であると信じています。
次に、技術的な SEO は検索エンジンのランキングに直接影響します。 ウェブサイトの速度とモバイルの応答性は、Google の検索アルゴリズム内のランキング要素であることが確認されており、さらに、適切に構造化された HTML マークアップがあることが、検索エンジンがウェブサイトの品質と関連性を評価する方法において重要な役割を果たします。 適切に最適化された Web サイトは、検索エンジンで上位にランクされる可能性が高くなります。
最後に、テクニカル SEO は、Web サイトの優れたユーザー エクスペリエンスに貢献します。 技術的な SEO に取り組んでいる間、ページの読み込み時間の最適化や URL の改善などの実践もユーザー満足度を向上させます。 ユーザー エクスペリエンスが向上すると、直帰率が低下し、エンゲージメント率が高まり、間接的に Web サイトの検索パフォーマンスが向上します。
最終的に、テクニカル SEO は効果的な SEO 戦略を構築するための基礎となります。 これにより、コンテンツが一流であるだけでなく、見つけやすくアクセスしやすくなることが保証されます。 これは、検索エンジンと、さらに重要なことに、ユーザーの両方にとって魅力的です。
技術的に最適化された Web サイトの特徴は何ですか?
Web サイトが何百万ポンドもの収益を上げている e コマース Web サイトであっても、地元の配管会社のサービスを紹介するパンフレット Web サイトであっても、技術的な SEO の観点から十分に最適化されているという点では、すべての Web サイトに同じ特徴があります。 。
これは速い
適切に最適化された Web サイトは、すべてのデバイス (デスクトップ、タブレット、モバイル) およびネットワーク状況に応じて迅速に読み込まれます。 ページの読み込みが速いと、Web サイトでのユーザー エクスペリエンスが向上し、検索エンジンによって好まれ、ランキングの向上につながる可能性があります。
Google がコア ウェブ バイタル テストの合格を確認されたランキング要素としてリストしていることはわかっていますが、これは Google にとっては珍しいことであるため、ウェブサイトが高速で CWV テストに合格していることを確認することが重要です。
クロール可能です
これは当然のことですが、Web サイトは検索エンジンによってクロール可能である必要があります。 検索エンジン ボット (Googlebot など) が Web サイトを効果的にクロールできない場合、SERP でのページのランキングに問題が生じることになります。
robots.txt ファイルとメタ ロボット タグは適切に構成する必要があります。 これは、検索エンジン ボットがどのページをクロールしてインデックスを作成するか、どのページをそのままにしておくかをガイドするのに役立ちます。 Web サイト上のすべてのページをクロールする必要はありません。 特に管理ページと顧客データを含むページ。
リンクの公平性を維持します
技術的に十分に最適化された Web サイトは、リンクの公平性をできる限り維持するためにできる限りのことを行っています。
まず、Web サイトはユーザー (および検索エンジン ボット) をサイト内の関連コンテンツに誘導する内部リンクを使用します。 これにより、Web サイトのナビゲーションが改善され、他のページへのリンクの共有が促進され、ユーザーが Web サイトに長く留まることができます。
次に、Web サイトには (理想的には) 壊れたリンクや不要なリダイレクト チェーンが完全になくなります。 これにより、シームレスなユーザー エクスペリエンスと検索エンジンによる効率的なクロールが保証されます。
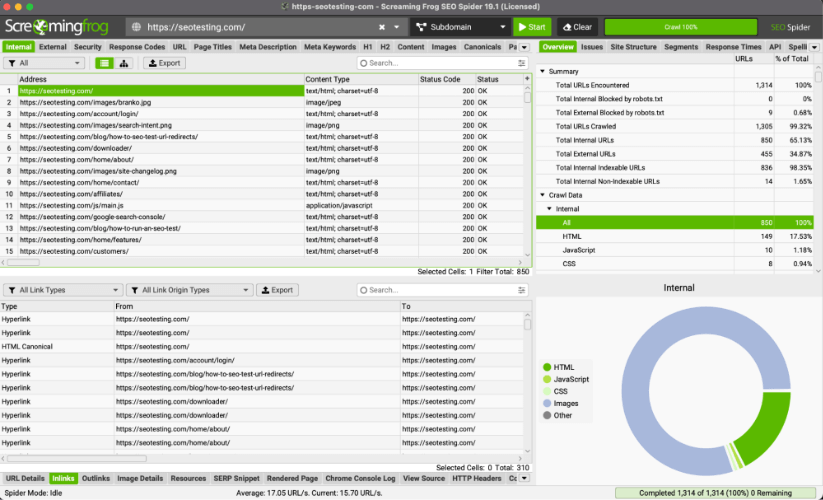
プロのヒント: ScreamingFrog を使用すると、壊れたリンクを特定し、存在する必要のないチェーンをリダイレクトできます。
モバイルフレンドリーです
すべての Web サイトは、モバイル デバイスで応答性が高く機能するように設計する必要があります。 ブラウジングでのスマートフォンの使用が増え続ける中 (2023 年現在、Google の米国のオーガニック検索トラフィックの 63% はモバイル デバイスからのものです)、モバイル フレンドリーさはユーザー エクスペリエンスとランキングの両方において重要な要素です。
安全です
すべての Web サイトは、Web サイトで安全な HTTPS プロトコルが使用されていることを確認する必要があります。
これにより、Web サイトで適切なデータ暗号化が行われるようになり、ユーザーが Web サイトを使用する際の信頼が高まります。 この信頼は、クレジット カード情報などの財務データが Web サイト上で受け渡される場合に特に重要です。
Google は、HTTPS プロトコルの使用がランキング要因であることも認めています。 アルゴリズムがこれにどのような重みを置いているかはわかりませんが、YMYL (Your Money Your Life) Web サイトを扱う場合、これがより重要な要素であると推測できます。
構造化データを使用します
スキーマ マークアップは Web サイトに実装され、コンテンツに関する追加のコンテキストを提供します。 これにより、検索エンジンは Web サイトを表示するときに SERP 内にリッチ スニペットを表示できるようになり、クリックスルー率が向上し、サイトへのトラフィックが増加します。
這う
このテーマについては、2023 年の SEO の学習方法に関する記事で簡単に説明しましたが、ここでは、Web サイトを HTML、CSS、JavaScript のページから SERP のランキングに導くテクニカル SEO の 4 つの段階を見ていきます。 クロール、レンダリング、インデックス作成、ランキング。
この旅の最初のステップは這うことです。
クロールとは、Google や Bing などの検索エンジンがインターネット上の Web サイトのコンテンツを体系的に閲覧し、詳細を学習するプロセスを指します。 クロールの目的は、Web ページに関する情報を収集することです。これには次のものが含まれます。
- その内容。
- 彼らの構造。
- その他の関連情報。
検索エンジンはこのデータを使用して効果的にインデックス付けとランク付けを行い (これについては後ほど説明します)、Web ページを SERP 内に表示します。
検索エンジンは、クローラーと呼ばれるボットを使用して、オンラインの膨大な Web ページをナビゲートします。 クローラーはまず、いくつかのよく知られた Web ページ (多くの場合、人気のあるページや頻繁に更新されるページ) にアクセスします。 そこから、これらのページにあるリンクをたどって新しいページを「発見」し、それをレンダリング、インデックス付け、ランク付けできます。
XML サイトマップ
XML サイトマップは、Web サイト上のすべての URL の構造化されたリストを検索エンジンに提供するファイルです。 これは、検索エンジン クローラーが Web サイトのコンテンツの構成を理解し、すべての重要なページを効果的に検出してインデックス付けできるようにするツールです。
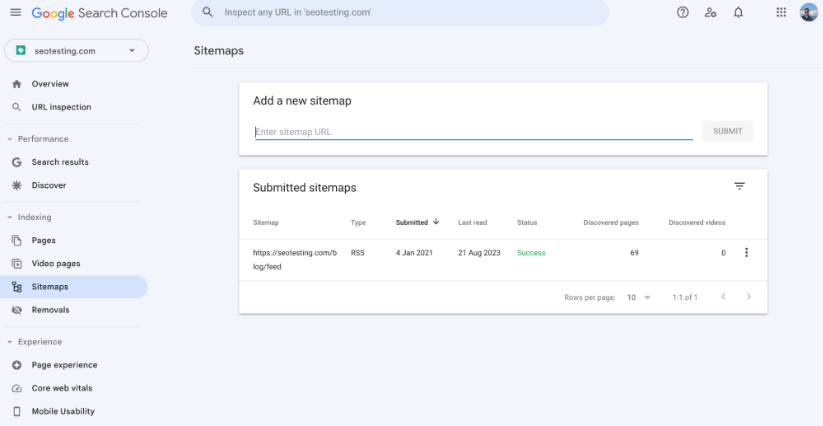
Web サイトに XML サイトマップがあることを確認することは、技術的な SEO に関して不可欠です。これは、いくつかの異なる方法でページがクロールされるのに役立つためです。
サイトに XML サイトマップを配置すると、クロールしてインデックスを作成する URL の一元的なリストが検索エンジン ボットに提供されます。 これにより、製品リスト ページや製品表示ページなどの重要なページがすべて、検索エンジンのインデックスに確実に含まれるようになり、できれば検索エンジンの結果ページにも含まれるようになります。
サイトマップを使用して優先度を指定し、サイト上の各 URL の頻度を変更することもできます。 検索エンジンはこれらのルールに正確に従っていない可能性があることに注意することが重要ですが、これにより、クローラーは Web サイト上のさまざまなページの重要性と、ページの更新頻度を把握できるようになります。
検索エンジンはさまざまな要素を使用して最初にクロールしてインデックスを付けるページを決定しますが、サイトマップは重要な (または新しく更新された) ページを強調表示するのに役立ちます。 これにより、検索エンジン ボットをこれらのページに誘導し、迅速にクロールしてインデックスを作成できるようになります。 サイトマップが設定されていない場合は、内部リンクや外部リンクなどを使用して、これらのページを自動的に見つけるためにクローラーに依存することになります。これには非常に長いプロセスがかかります。
数十万 (または数百万の URL) がある大規模なサイトでは、サイトマップ (および複数のサイトマップ) を使用すると、クローラーがインデックスを作成するすべてのページをより効率的に検出できるようになります。 これは、クロールの予算をより効率的に管理するのに役立つため、実行するのに最適です。 小規模な Web サイトではクロール バジェットに問題がないため、これは問題ではありません。
サイトの構造
Web サイトの構造は、検索エンジン ボットがそのコンテンツをどのようにナビゲートしてインデックスを作成するかを決定する上で重要な役割を果たします。 適切に整理されたサイト構造は、検索エンジン ボットによる効率的なクロールを促進するだけでなく、実際のユーザーが Web サイトで得る全体的なエクスペリエンスも向上させます。
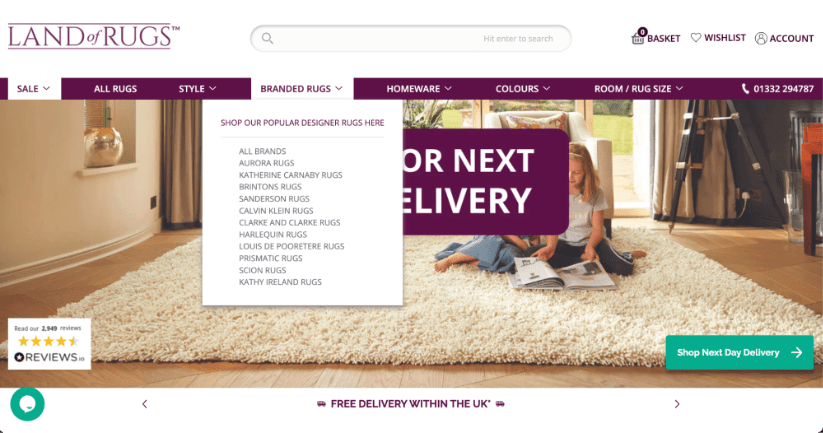
これは、優れたサイト構造を備えた e コマース Web サイトの例です。 この例のすべての重要なページ (製品リスト ページ) には、ホームページのナビゲーション バーから簡単にアクセスでき、これらのページにできる限り多くのリンク エクイティが渡され、クローラーが簡単に見つけられるようになります。
ページがシンプルでわかりやすいカテゴリとサブカテゴリに編成されていると、クローラーがリンクをたどり、体系的にコンテンツにインデックスを付けることがはるかに簡単になります。 この階層構造により、重要なページがホームページの近くに配置されるため、すぐに発見され、インデックスが作成される可能性が高まります。
Web サイトの構造内に内部リンクを設けると、検索エンジンのクローラーがサイトのさまざまなセクションをより効果的に通過できるようになります。 関連性の高い内部リンクを適切に配置すると、リンクの公平性がページ全体に分散され、クローラーがコンテンツ全体に内部リンクを配置しない場合よりもはるかに広範囲のコンテンツを発見できるようになります。
孤立したページ (ページへのリンクがないページ) は、クローラーにとって大きな課題となるため、避けるべきです。 適切な内部リンクを備えた堅牢なサイト構造であれば、これを回避できます。
全体として、Web サイトの構造は、検索エンジンがコンテンツをクロールしてインデックスを作成する方法を決定する重要なフレームワークとして機能します。 明確なサイト階層を実装し、関連するコンテキスト リンクを追加し、(必要に応じて) クロール予算の割り当てを最適化することで、Web サイトの所有者やマーケティング担当者は、検索エンジンが Web サイトをクロールする方法にプラスの影響を与えることができます。
URL構造
Web サイトの URL 構造は、Web サイトのクロールに直接影響します。 URL 構造がよく整理された (そして説明的な) 構造になっていると、クローラーが各ページのコンテンツを理解する効率が向上します。 明確な (そして短い) URL は、Web サイト内のページの位置のトピックと階層に関する貴重なコンテキストを提供します。
たとえば、https://example.com/blog/head-topic-1 のような URL は、このページがブログ内で Web サイトの重要なトピックの 1 つに関する重要なページであることを検索エンジン クローラーに伝えます。
一方、複雑な URL や意味不明な URL (良い例は https://example.com/12642/test-category/test-page125253/) は、Web サイトを移動するときにクローラーを混乱させる可能性があります。 これにより、コンテンツを解釈する能力が妨げられ、Web サイト内のページの関連性や重要性が損なわれます。 不要なパラメーターや記号のないクリーンな URL 構造により、ページが効果的にクロールされる可能性が高まります。
さらに、クロールとは直接関係ありませんが、URL 構造は Web サイトのユーザー エクスペリエンスとクリックスルー率に直接影響します。 簡潔で関連性の高い URL は、検索結果でユーザーのクリックを引き付ける可能性が非常に高く、Web サイト全体の検索エンジンのランキングに (間接的に) 影響を与える可能性があります。
Robots.txt ファイル
robots.txt ファイルは、検索エンジンが Web サイトを移動およびクロールする方法に対して多大な影響力を持っています。 この文書はサイトの中核に位置し、Web サイトをどのようにクロールすべきかを規定する、検索エンジン クローラーに対するガイドラインを詳しく説明します。 どのページをクロールできるか、どのページをそのままにしておくべきかが含まれます。

この段階で注意すべき点は、robots.txt ファイルは Web サイトの特定のページまたはセクションへのクローラーの侵入を阻止することはできますが、別の手段を介してページがクロールされないことを保証するものではありません。 一部の検索エンジンでは、サイトの内部リンクなど、他の方法でページが見つかった場合でも、クロールから除外されるページを登録する場合があります。
robots.txt ファイルにエラーや厳格なルールが含まれていると、検索エンジンが重要なコンテンツをクロールできなくなり、SERP における Web サイトのパフォーマンスに「影を落とす」可能性があります。 すべてのルールが正しく機能していることを確認するために、robots.txt ファイルを定期的に監視することが重要です。
ログファイルの分析
Web サイトのログ ファイルを分析すると、検索エンジンが Web サイトをクロールする方法に大きな影響を与える可能性があります。これは、マーケティング担当者が適切なツールを使用して自分で実行できることです。 ログ ファイルは基本的に、Web サイトの検索エンジンが訪問する部分と、検索エンジン クローラーが Web サイトのこれらの部分を訪問する頻度を示す記録です。 基本的に、これにより、Web サイト上のどのページが検索エンジンによって重要であると見なされているかを判断でき、これを利用して優位性を得ることができます。
これは、マーケティング担当者がどのページにもっと時間(そして潜在的にお金)を費やす価値があるかを判断するのに役立ち、検索エンジンが適切な内容に注意を払うようになります。 また、ログ ファイル分析により、検索エンジンが Web サイトを理解しやすく、ナビゲートしやすいと判断しているか、それとも問題が発生しているかを知ることができます。 これにより、ページの接続方法を修正したり (通常は内部リンクを通じて)、Web アドレスをより適切に整理したりするなどの変更を行うことができます。
これに関する私のお気に入りの講演の 1 つは、2018 年に HubSpot の有機的成長担当副社長だったマシュー バービー氏によるものです。講演の正確な部分は 25:07 にあります。
レンダリング
レンダリングとは、検索エンジンが Web サイトのコンテンツと構造を分析および理解し、SERP でのランキングを決定するプロセスを指します。 このプロセスには、クロール (これについてはすでに説明しました) とインデックス作成 (これについてはすぐに説明します) という 2 つの主要なステップが含まれます。
クロール中、検索エンジン ボットは Web を横断し、Web ページにアクセスして HTML データを収集します。 ただし、すべてのコンテンツが HTML マークアップにすぐに表示されるわけではありません。 ここでレンダリングが登場します。
レンダリングでは、基本的な HTML 解析を超えて、生の HTML では表示されない可能性がある、最新の Web サイトでよく使用される動的要素が考慮されます。 これには、JavaScript、AJAX、またはその他のスクリプト言語を通じてロードされたコンテンツと、ページの CSS スタイルシートが含まれます。 検索エンジン ボットは、ユーザー エクスペリエンスをシミュレートしようとして、JavaScript を実行し、完全にレンダリングされたコンテンツを収集します。このコンテンツは、Web ページに関する情報のデータベースであるインデックスを構築するために使用されます。
最適な SEO 結果を得るには、Web サイトが検索エンジン ボットによって簡単に表示できるようにすることが重要です。 これには、サーバーサイド レンダリング (SSR) や JavaScript を多用する Web サイトのプリレンダリングなどの技術の使用が含まれます。 メタデータ (メタ タグや説明など) を提供すると、検索エンジンがコンテンツのコンテキストや意味を理解するのに役立ちます。 正規タグを適切に処理し、リダイレクトを管理することも、重複コンテンツの問題を防ぐために重要です。
インデックス作成
インデックス作成とは、Web ページに関する情報を収集、整理、および保存して、ユーザーが関連するクエリを検索するときに情報を迅速に取得して検索結果に表示できるようにするプロセスを指します。 Web クローラーが Web ページをクロールしてそのコンテンツを表示すると、その情報が検索エンジンのインデックスに追加されます。
インデックスは本質的に、インターネット上の Web サイトのコンテンツと Web ページの構造に関する情報を含む巨大なデータベースです。 この膨大な情報データベースにアクセスできると、検索エンジンはインデックスから関連するページを見つけて SERP に表示することで、ユーザーのクエリに迅速に応答できます。
インデックス作成プロセス中に、検索エンジンは、クロールおよびレンダリングされた Web ページからコンテンツ、メタデータ、画像、リンクなどの重要な情報を抽出します。 この情報は構造化された方法で保存されるため、検索エンジンはユーザーのクエリと関連するページを迅速に照合できるようになります。
ページのインデックスを効率的に作成するには、いくつかのことを検討する必要があります。
重複コンテンツとキーワードのカニバリゼーション問題に対処する
重複コンテンツやキーワードのカニバリゼーションの問題に対処すると、ページのインデックスを迅速に作成できるようになり、大きなメリットが得られます。
重複したコンテンツを削除することで、検索エンジンの混乱を防ぎ、コンテンツのプライマリ バージョンを正確に識別できるようになります。
さらに、複数のページが同じキーワードをターゲットとするキーワードの共食い問題を解決すると、各ページの焦点についての明確なシグナルが検索エンジンに提供されます。 この明確さは、検索エンジンがすべてのページの正確な目的を理解できるため、効率的なインデックス作成とランキングに役立ちます。
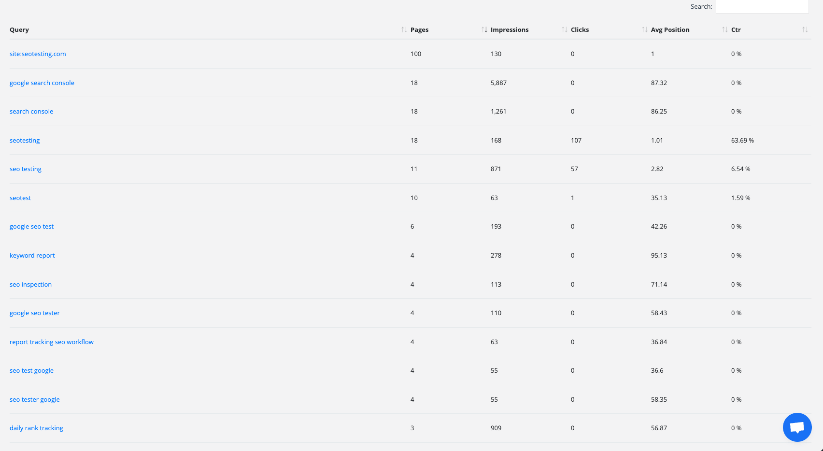
SEOTesting 内のキーワードカニバリゼーションレポートを示す画像。 このレポートは、Web サイト上のキーワードのカニバリゼーションの問題を迅速に特定して修正するのに役立ちます。
メタデータ (タイトル タグやメタ ディスクリプションなど) を最適化し、内部リンク構造を調整することも、迅速かつ簡単なインデックス作成に役立ちます。 これらのアクションが正しく実行されると、検索エンジンは最も関連性の高い重要なページに誘導されます。
さらに、コンテンツを統合し、キーワードの共食いを回避すると、コンテンツの権限が 1 つのページに集中します。 これにより、ページの権威が高まり、検索エンジンがその権威あるページを優先し、SERP 内でより目立つようにランク付けするようになります。
リダイレクトの監査
Web サイトのリダイレクトがどのように機能するかを調べると、検索エンジンがコンテンツのインデックスを作成する速度を向上させることができます。 また、Web サイト全体のパフォーマンスの向上にも役立ちます。 リダイレクトはマーケットのように機能し、必要に応じてユーザーと検索エンジンの両方を別のページに誘導します。 適切に管理しないと、インデックス作成プロセスが遅くなったり、ページのインデックスが完全に停止されたりする可能性があります。 「リダイレクト監査」を実行すると、いくつかの有意義な方法でインデックス作成を強化できます。
まず、過剰なリダイレクトに対処すると、Web サイトのインデックス作成時に検索エンジンがより効果的に機能するようになります。場合によっては、複数のリダイレクトが発生し、コンテンツのインデックス作成が遅くなる可能性があります。 不要なリダイレクトを見つけて削除することで、検索エンジンがコンテンツに迅速にアクセスできるようになり、インデックスが迅速に作成される (したがってランク付けされる) 可能性も高まります。
リダイレクト監査を完了すると、SEO に関する一般的な技術的な問題に取り組むこともできます。 リダイレクトチェーン。 このような連鎖は、あるリダイレクトが別のリダイレクトにつながり、そのリダイレクトが別のリダイレクトにつながり、さらにそのリダイレクトが別のリダイレクトにつながる場合に発生する可能性があります。 検索エンジンを混乱させ、多くの時間を費やしてしまう可能性があります。 検索エンジン ボットがページのインデックス作成に時間がかかりすぎると、次のステップに進み、そのページのインデックスを作成しないことがわかっています。 監査により、これらのチェーンを見つけて修正できるため、検索エンジンが問題なくコンテンツにアクセスできるようになります。
最後に、このような監査は、検索エンジンが Web サイトを正確に理解するのに役立ちます。 リダイレクトが適切に構造化されている場合、検索エンジンはコンテンツの重要性をより適切に解釈できます。 検索エンジンがコンテンツの重要性をよりよく理解すると、重要なページが迅速にインデックスされる可能性が高くなります。
HTTP および HTTPS エラーを修正する
HTTP エラーと HTTPS エラーを修正することは、ページのインデックスが適切に作成されるようにするために不可欠です。 検索エンジン ボットがこの種のエラーに遭遇すると、コンテンツにアクセスして理解することが困難になります。 検索エンジン ボットがコンテンツにアクセスできない、またはコンテンツを理解できない場合、インデックスを作成することはできません。
これらの問題に対処すると、次の方法でインデックス作成が改善されます。
まず、「404 Not Found」などの HTTP エラーを解決すると、ユーザーと検索エンジンの両方がページにアクセスできるようになります。 ページがこれらのエラーを返すと、検索エンジンはそれらをコンテンツが欠落していると解釈し、検索結果から除外されます。 これらのエラーを修正すると、クローラーにコンテンツのインデックスを作成するための「明確なパス」が与えられ、インデックスが作成されてランク付けされる可能性が高まります。
次に、HTTP から HTTPS への移行は、セキュリティとインデックス作成にとって重要です。 検索エンジンは、ランキング アルゴリズムにおいて、安全でない Web サイト (HTTP) よりも安全な Web サイト (HTTPS) を大幅に優先します。 Googleもこれを認めています! HTTPS に移行し、ユーザーに安全なブラウジング エクスペリエンスを確保することで、サイトの信頼性が向上し、インデックス付けおよびランク付けの能力が間接的に向上します。
最後に、一貫した HTTPS の実装と HTTPS 関連のエラーの解決により、ユーザーと検索エンジンが「混合コンテンツ」の問題に遭遇するのを防ぎます。 混合コンテンツは、セキュアな要素と非セキュアな要素が同じページに読み込まれるときに発生します。 これにより、セキュリティ警告が発生し、ユーザー エクスペリエンスに悪影響を及ぼす可能性があります。
基本的に、HTTP および HTTPS エラーに対処すると、検索エンジンがコンテンツにアクセスして理解するのを妨げる障壁が取り除かれます。 この非常に積極的なアプローチにより、インデックス作成プロセスが最適化され、検索結果の可視性が向上し、サイトのユーザー エクスペリエンスが向上します。
Google Search Consoleで「ページインデックスレポート」を確認してください。
Google Search Console は、コンテンツがどのようにインデックスに登録されているかを評価するための宝の山です。 ページ インデックス作成レポートでは、Web サイト上のインデックスが作成されていないすべてのページを確認できます。 ページがインデックスに登録されていない理由も確認できます。
以下に例を示します。
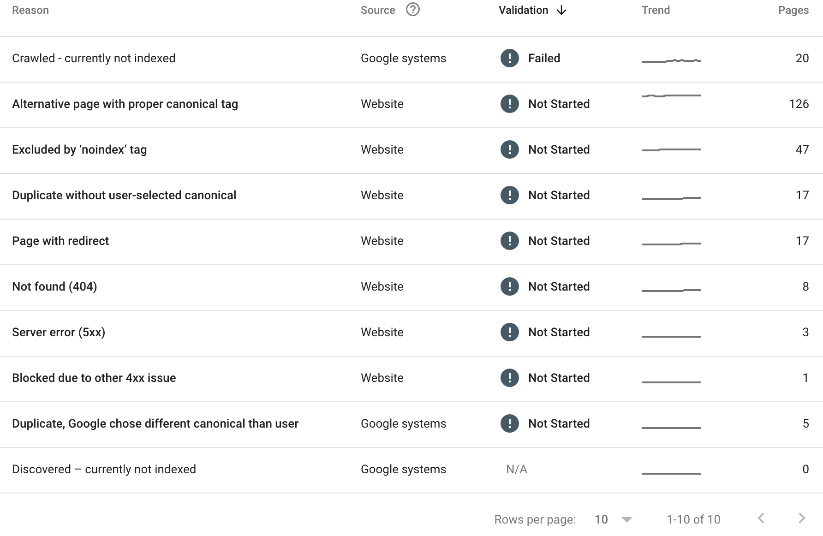
上記 (SEOTesting のページ インデックス作成レポート) では、次のことがわかります。
- 20 ページがクロールされましたが、現在インデックスが作成されていません。
- 126 ページには適切な canonical タグが付いています。
- 47 ページが「noindex」タグによって除外されました。
- 17 ページが重複していたことが判明し、ユーザーが選択した正規版はありませんでした。
- 17 ページにリダイレクトが設定されています。
- 8 ページが 404 エラーを返しました。
- 3 ページが 5xx サーバー エラーを返しました。
- 別の 4xx 問題により 1 ページがブロックされました。
- 5 ページが重複として見つかり、Google は別の正規版を選択しました。
上記の理由すべてが問題であるわけではありませんが、マーケティング チームとして、特定のページがインデックスに登録されていない理由を突き止め、これらの問題をできる限り修正することは価値があります。
ランキング
検索エンジンのランキングは、クロール、レンダリング、インデックス作成プロセスの最終結果であり、検索エンジンはここで Web ページが SERP に表示される順序を決定します。 目標は、検索クエリに基づいて、最も関連性が高く価値のあるコンテンツをユーザーに提示することです。
ランキングの中核は、さまざまな要素を評価して Web ページの関連性と権威性を決定する複雑なアルゴリズムに依存しています。 基本的な側面の 1 つはキーワードの関連性、つまりユーザーが検索で入力した単語やフレーズとコンテンツがどの程度一致するかです。 キーワードとの関連性が高いページは、ランクが高くなる傾向があります。
ただし、キーワードの関連性だけでは十分ではありません。 検索エンジンは、Web サイトの品質と権威性も考慮します。 評判が良く、権威があり、関連性がある (これは非常に重要です) サイトからのバックリンクは、ページの信頼性を示す強力な指標です。 ページに高品質のバックリンクが多いほど、上位にランクされる可能性が高くなります。
ユーザーがウェブサイト上で体験していることも、ランキングに大きな影響を与えます。 読み込みが速く、モバイル対応で、ユーザーにスムーズなブラウジング体験を提供するページは、検索エンジンで非常に好まれます。 ユーザーをサイトに長く留めて閲覧できる魅力的で価値のあるコンテンツは、検索エンジンに対して、あなたの Web サイトが上位にランクされる価値があるというシグナルを送ります。
パーソナライゼーションはランキングのもう 1 つの側面です。 検索エンジンは、ユーザーの位置、検索履歴、好みを考慮して検索結果を調整し、ユーザーに可能な限り最高のエクスペリエンスを提供します。 これは、同じクエリでもユーザーごとに異なる結果が得られる可能性が高いことを意味します。
他のブログ投稿でどのような言及があったとしても、Google (および他の検索エンジン) がさまざまなクエリのさまざまな要素をどの程度重視しているかはわからないということを覚えておくことが重要です。 1 つの質問については、信頼できる関連性の高いバックリンクにもっと依存する必要があるかもしれません。 もう 1 つは、ユーザー エクスペリエンスが適切であることを確認する必要があるかもしれません。 これはすべて、業界での時間、つまりアルゴリズムを学習し、成長するにつれて改善することにかかっています。
SERP で成功するには、SEO のさまざまな側面を理解することが不可欠です。 この記事では、テクニカル SEO の重要性、最適化されたサイトの特徴、クロールからランキングまでのテクニカル SEO の仕組みについて説明しました。
テクニカル SEO は Web サイトの強力な基盤を構築し、要素を最適化して速度と構造を向上させます。 これにより、ナビゲーション、コンテンツの理解、ユーザー エクスペリエンスが向上します。
つまり、技術的なSEOが鍵となります。 エラーを修正し、サイト構造を最適化することで、オンラインでの存在感を高めることができます。
SEO テストを日常に取り入れて、Google Search Console の使用を強化し、SEO を次のレベルに引き上げたいと考えていますか? SEOTesting を試してみてください。 現在、14 日間の無料トライアルを実施中です。サインアップにクレジット カードは必要ありません。 今すぐこのツールを試してみて、ご意見をお聞かせください。