
AI가 콘텐츠를 크롤링하지 못하도록 차단하는 방법
게시 됨: 2023-10-24Google Bard 및 Bing Chat과 같은 AI 생성 도구는 웹을 포함한 다양한 콘텐츠 소스에서 구축되었습니다. 많은 사람들이 놀랍게도 검색 엔진은 전통적인 웹 검색을 위해 크롤링하는 동안 찾은 모든 콘텐츠에 대해 조용히 AI 모델을 훈련해 왔습니다.
Bing과 Google은 이제 웹 검색용 색인을 유지하면서 콘텐츠가 AI 훈련에 사용되는 것을 차단하는 방법을 발표했습니다.
그렇다면 AI를 차단해야 하며 어떻게 해야 할까요?
- AI를 차단해야 할까요?
- AI 봇을 어떻게 차단하나요?
- Bing의 AI를 차단하는 방법
- Google의 AI를 차단하는 방법
- ChatGPT를 차단하는 방법
- 테스트
AI를 차단해야 할까요?
자체 제품을 만드는 회사는 자사의 콘텐츠를 AI 모델에 포함시키는 것이 이점이라고 생각할 수 있습니다. 기술 사양이나 제품 지원과 같은 정보는 판매 및 고객 지원 비용 절감에 도움이 될 수 있습니다.
하지만 다른 많은 온라인 비즈니스에서는 콘텐츠가 바로 제품입니다. 콘텐츠 제작에 투자된 에너지가 트래픽 형태의 가치를 제공하지 못한 채 거대 기술 기업이 소유한 AI 제품을 개선하는 데 사용될 것이라는 타당한 우려가 있습니다.
Google과 Bing은 소스에 대한 크레딧을 제공하고 일부 추천 트래픽을 제공하는 방법을 찾으려고 노력하고 있지만 이는 기존 웹 검색보다 적고 정보 검색 쿼리보다 거래가 많을 가능성이 높습니다.
이러한 AI의 콘텐츠를 차단해도 크롤링 동작에는 영향을 미치지 않는다는 점에 유의하는 것이 중요합니다. Google은 'robots.txt 사용자 에이전트 토큰이 제어 용량으로 사용됩니다'라고 말합니다. 귀하의 사이트는 검색 색인을 구축하기 위해 봇에 의해 정상적으로 크롤링됩니다.
그리고 검색 엔진이 이미 특정 페이지를 크롤링하지 못하도록 차단된 경우 AI에 대해 특별히 차단할 필요가 없습니다.
AI 봇을 어떻게 차단하나요?
현재 대부분의 SEO에 익숙한 방법, robots.txt 파일 및 페이지 수준 로봇 지시문을 사용하여 Google, Bing 및 ChatGPT를 차단할 수 있습니다.
Google과 ChatGPT는 URL 패턴을 지정할 수 있는 robots.txt 방법을 선택했으며 Bing은 개별 페이지에 적용되는 robots 지시문을 사용하기로 선택했습니다.
robots.txt는 한 곳에서 전체 웹사이트를 쉽게 구성할 수 있다는 장점이 있습니다. 모든 단일 페이지를 가져와 테스트해야 하는 페이지 수준 로봇 지시문과 비교하여 어떤 URL이 차단되고 있는지는 매우 투명합니다.
Bing의 AI를 차단하는 방법
Bing은 페이지에 메타 태그 또는 X-Robots-Tag 응답 헤더로 추가할 수 있는 nocache 또는 noarchive 로봇 지시문을 찾습니다.
Nocache를 사용하면 Microsoft의 AI 모델 교육에서 URL, 제목 및 조각만 사용하여 Bing Chat 답변에 페이지를 포함할 수 있습니다.
Noarchive는 Bing Chat에 페이지를 포함하는 것을 허용하지 않으며 Microsoft의 AI 모델을 교육하는 데 콘텐츠가 사용되지 않습니다.
페이지에 Nocache와 Noarchive가 모두 있는 경우 덜 제한적인 Nocache가 우선 적용됩니다.
' robots ' 토큰은 모든 크롤러에 지시어를 적용합니다. 여기에는 페이지가 검색결과에 캐시된 링크와 함께 표시되는 것을 방지하는 Google이 포함됩니다.
<메타 이름=”로봇” 콘텐츠=”noarchive”>
더 구체적인 ' bingbot ' 또는 ' msnbot ' 토큰을 사용하면 다른 검색 엔진에 영향을 주지 않을 수 있습니다.
<메타 이름=”bingbot” 콘텐츠=”nocache”>
Google의 AI를 차단하는 방법
Google은 Bard 및 해당 Vertex API에서 사용하고 싶지 않은 페이지와 일치하는 URL 패턴을 지정할 수 있는 robots.txt 방법을 선택했습니다. 현재 SGE(검색 생성 경험)에는 적용되지 않습니다.
Google 확장의 사용자 에이전트 토큰과 일치합니다. 토큰의 대소문자는 중요하지 않습니다.
사용자 에이전트: Google 확장
허용하지 않음: /
Google 확장 토큰에 대한 규칙 블록이 없는 경우 와일드카드 토큰(*)과 일치합니다.
사용자 에이전트: *
허용하지 않음: /
Googlebot에 대한 특정 규칙 블록과 별도의 와일드카드 블록이 있는 경우 주의하세요. Google 확장은 Googlebot 블록이 아닌 와일드카드 블록과 일치합니다.
사용자 에이전트: Googlebot
허용하다: /
사용자 에이전트: *

허용하지 않음: /
보다 정확하게 규칙을 차단하기 전에 여러 사용자 에이전트를 나열할 수 있습니다.
사용자 에이전트: Google 확장
사용자 에이전트: Googlebot
허용하다: /
사용자 에이전트: *
허용하지 않음: /
ChatGPT를 차단하는 방법
ChatGPT는 또한 robots.txt 방법을 선택했습니다.
Chat GPT에는 ChatGPT 사용자를 대신하여 쿼리하기 위한 ChatGPT-User와 모델 구축에 사용되는 OpenAI의 웹 크롤러인 GPTBot라는 두 가지 사용자 에이전트 토큰이 있습니다.
옵트아웃 시스템은 현재 두 사용자 에이전트를 동일하게 취급하므로 한 에이전트에 대해 허용되지 않는 robots.txt는 둘 다 포함합니다. 이는 향후 변경될 수 있으므로 별도로 차단하는 것이 좋습니다.
사용자 에이전트: GPTBot
사용자 에이전트: ChatGPT-사용자
허용하지 않음: /
테스트
전체 웹사이트를 차단하는 경우 테스트는 간단합니다.
Google 및 ChatGPT가 차단되었는지 확인하려면 robots.txt에 차단하려는 봇에 대한 모든 것을 허용하지 않는 규칙이 있는지 확인해야 합니다.
사용자 에이전트: Google 확장
사용자 에이전트: GPTbot
허용하지 않음: /
일부 URL만 차단하려면 더 복잡한 robots.txt 지시어 세트가 필요할 수 있습니다. 차단될 것으로 예상되는 URL과 차단되지 않을 것으로 예상되는 여러 URL을 테스트하는 것을 고려할 수 있습니다.
Tomo는 robots.txt에서 특정 URL이 차단되었는지 테스트하는 데 도움이 되는 무료 robots.txt 도구입니다. URL 목록 형식으로 테스트를 정의하고 각 URL에 대해 예상되는 허용되지 않는 상태를 정의할 수 있습니다.
Google 확장, GPTBot 및 ChatGPT-User 사용자 에이전트 토큰으로 구성하여 각각에 대해 차단된 URL과 예상 테스트 결과와 일치하는지 확인할 수 있습니다.
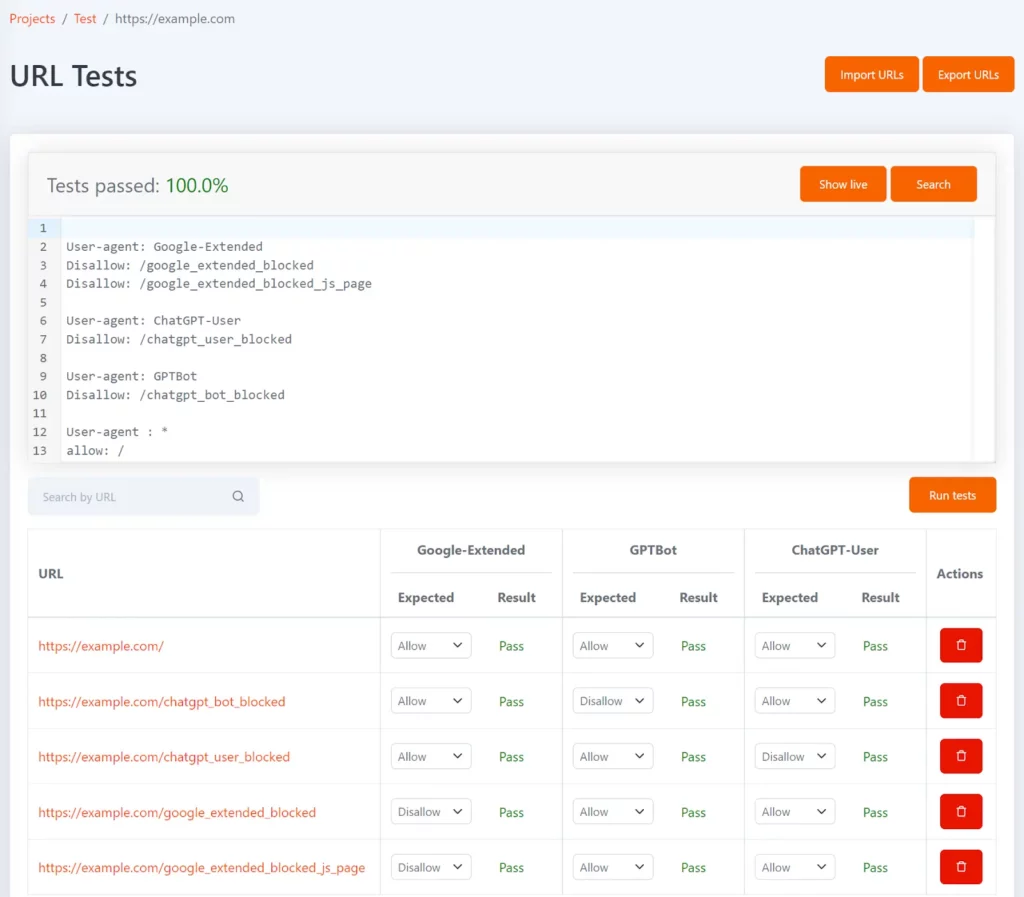
robots.txt 파일이 업데이트될 때마다 테스트가 다시 실행되며 결과가 예상한 것과 일치하지 않으면 알림을 받게 됩니다.
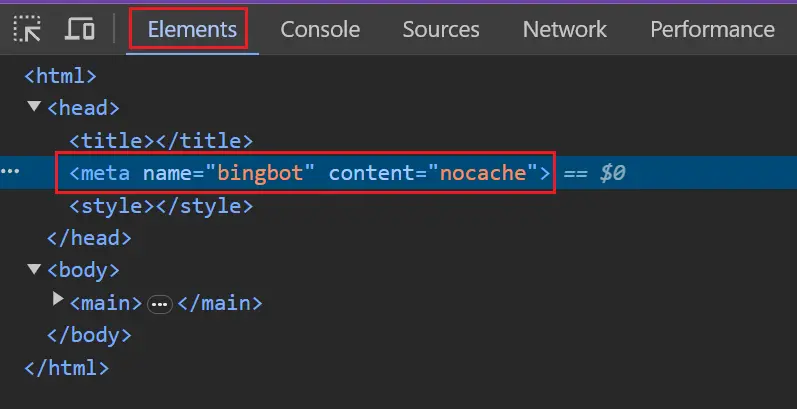
Bing이 차단되었는지 테스트하려면 브라우저에서 주요 페이지 템플릿을 검사하고 로봇 태그가 있는지 확인할 수 있습니다.
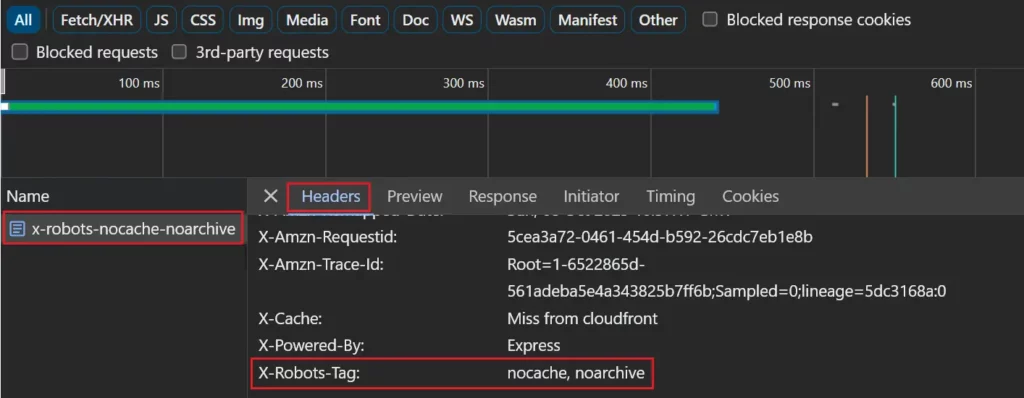
X-Robots-Tag 응답 헤더를 사용하는 경우 네트워크 요청 목록에서 페이지를 선택하고 '헤더' 탭을 보면 네트워크 탭에서 볼 수 있습니다.
특정 페이지 집합을 차단하는 경우 테스트가 더 복잡해지지만 도움이 될 수 있는 몇 가지 도구가 있습니다.
Lumar 크롤러는 이제 Google 및 Bing의 AI가 차단된 모든 페이지를 자동으로 보고합니다.
추가 기술 지원이 필요합니까? Semetrical의 기술 제공 에 대해 자세히 알아보거나 더 많은 정보를 원하시면 연락주세요 !