
Python 웹 크롤러 – 단계별 튜토리얼
게시 됨: 2023-12-07웹 크롤러는 데이터 수집 및 웹 스크래핑 분야에서 매력적인 도구입니다. 검색 엔진 인덱싱, 데이터 마이닝 또는 경쟁 분석과 같은 다양한 목적으로 사용될 수 있는 데이터를 수집하기 위해 웹 탐색 프로세스를 자동화합니다. 이 튜토리얼에서는 웹 데이터 처리에 있어 단순성과 강력한 기능으로 알려진 언어인 Python을 사용하여 기본 웹 크롤러를 구축하는 유익한 여정을 시작합니다.
풍부한 라이브러리 생태계를 갖춘 Python은 웹 크롤러 개발을 위한 탁월한 플랫폼을 제공합니다. 신진 개발자, 데이터 매니아 또는 단순히 웹 크롤러의 작동 방식에 대해 궁금한 점이 있는 분이라면 이 단계별 가이드를 통해 웹 크롤링의 기본 사항을 소개하고 자신만의 크롤러를 만들 수 있는 기술을 갖추실 수 있습니다. .
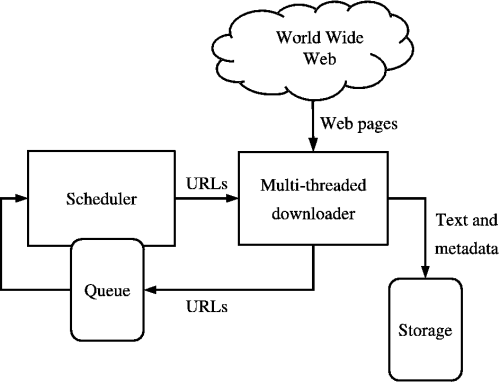
출처: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python 웹 크롤러 – 웹 크롤러를 구축하는 방법
1단계: 기본 사항 이해
스파이더라고도 알려진 웹 크롤러는 월드 와이드 웹(World Wide Web)을 체계적이고 자동화된 방식으로 탐색하는 프로그램입니다. 크롤러의 경우 단순성과 강력한 라이브러리로 인해 Python을 사용합니다.
2단계: 환경 설정
Python 설치 : Python이 설치되어 있는지 확인하세요. python.org에서 다운로드할 수 있습니다.
라이브러리 설치 : HTML을 구문 분석하려면 bs4의 HTTP 요청과 BeautifulSoup을 만들기 위한 요청이 필요합니다. pip를 사용하여 설치하십시오.
pip 설치 요청 pip install beautifulsoup4
3단계: 기본 크롤러 작성
가져오기 라이브러리 :
bs4 import BeautifulSoup에서 가져오기 요청
웹페이지 가져오기 :
여기서는 웹페이지의 콘텐츠를 가져옵니다. 'URL'을 크롤링하려는 웹페이지로 바꾸세요.
url = 'URL' 응답 = 요청.get(url) 콘텐츠 = response.content
HTML 콘텐츠를 구문 분석합니다 .
수프 = BeautifulSoup(content, 'html.parser')
정보 추출 :
예를 들어 모든 하이퍼링크를 추출하려면 다음을 수행할 수 있습니다.
Soup.find_all('a')의 링크: print(link.get('href'))
4단계: 크롤러 확장
상대 URL 처리 :
상대 URL을 처리하려면 urljoin을 사용하십시오.
urllib.parse에서 urljoin 가져오기
같은 페이지를 두 번 크롤링하지 마세요 .
중복을 피하기 위해 방문한 URL 세트를 유지하십시오.
지연 추가 :
존중하는 크롤링에는 요청 간 지연이 포함됩니다. time.sleep()을 사용하세요.
5단계: Robots.txt 존중
크롤러가 크롤링하지 말아야 할 사이트 부분을 나타내는 웹사이트의 robots.txt 파일을 준수하는지 확인하세요.
6단계: 오류 처리
연결 시간 초과 또는 액세스 거부와 같은 잠재적인 오류를 처리하려면 try-Exception 블록을 구현하세요.
7단계: 심층 분석
양식 제출이나 JavaScript 렌더링과 같은 더 복잡한 작업을 처리하도록 크롤러를 향상시킬 수 있습니다. JavaScript가 많은 웹사이트의 경우 Selenium 사용을 고려해보세요.
8단계: 데이터 저장
크롤링한 데이터를 저장하는 방법을 결정합니다. 옵션에는 간단한 파일, 데이터베이스 또는 서버로 직접 데이터 전송이 포함됩니다.
9단계: 윤리적으로 행동하세요
- 서버에 과부하를 주지 마십시오. 귀하의 요청에 지연을 추가하십시오.
- 웹사이트의 서비스 약관을 따르세요.
- 개인정보를 무단으로 스크랩하거나 저장하지 마세요.
차단되는 것은 웹 크롤링 시 흔히 발생하는 문제이며, 특히 자동화된 액세스를 감지하고 차단하는 조치를 갖춘 웹사이트를 처리할 때 더욱 그렇습니다. Python에서 이 문제를 해결하는 데 도움이 되는 몇 가지 전략과 고려 사항은 다음과 같습니다.
차단된 이유 이해하기
빈번한 요청: 동일한 IP에서 신속하고 반복적으로 요청하면 차단이 발생할 수 있습니다.
인간이 아닌 패턴: 봇은 페이지에 너무 빨리 액세스하거나 예측 가능한 순서로 액세스하는 등 인간의 탐색 패턴과 다른 동작을 나타내는 경우가 많습니다.
헤더 관리 부실: HTTP 헤더가 누락되거나 올바르지 않으면 요청이 의심스러워 보일 수 있습니다.

robots.txt 무시: 사이트의 robots.txt 파일에 있는 지침을 준수하지 않으면 차단될 수 있습니다.
차단을 피하기 위한 전략
robots.txt 존중 : 항상 웹사이트의 robots.txt 파일을 확인하고 준수하세요. 이는 윤리적인 관행이며 불필요한 차단을 방지할 수 있습니다.
순환 사용자 에이전트 : 웹사이트는 사용자 에이전트를 통해 귀하를 식별할 수 있습니다. 이를 회전시키면 봇으로 신고될 위험이 줄어듭니다. 이를 구현하려면 fake_useragent 라이브러리를 사용하세요.
from fake_useragent import UserAgent ua = UserAgent() 헤더 = {'User-Agent': ua.random}
지연 추가 : 요청 사이에 지연을 구현하면 사람의 행동을 모방할 수 있습니다. 무작위 또는 고정 지연을 추가하려면 time.sleep()을 사용하십시오.
import time time.sleep(3) # 3초 동안 기다립니다.
IP 교체 : 가능하다면 프록시 서비스를 이용해 IP 주소를 교체하세요. 이를 위해 무료 및 유료 서비스가 모두 제공됩니다.
세션 사용 : Python의 요청.세션 개체는 요청 전반에 걸쳐 일관된 연결을 유지하고 헤더, 쿠키 등을 공유하는 데 도움이 되어 크롤러가 일반 브라우저 세션처럼 보이도록 할 수 있습니다.
request.Session()을 세션으로 사용: session.headers = {'User-Agent': ua.random} response = session.get(url)
JavaScript 처리 : 일부 웹사이트는 콘텐츠를 로드하기 위해 JavaScript에 크게 의존합니다. Selenium이나 Puppeteer와 같은 도구는 JavaScript 렌더링을 포함하여 실제 브라우저를 모방할 수 있습니다.
오류 처리 : 강력한 오류 처리를 구현하여 블록이나 기타 문제를 적절하게 관리하고 대응합니다.
윤리적 고려사항
- 항상 웹사이트의 서비스 약관을 존중하세요. 사이트에서 웹 스크래핑을 명시적으로 금지하는 경우 이를 준수하는 것이 가장 좋습니다.
- 크롤러가 웹사이트 리소스에 미치는 영향에 유의하세요. 서버에 과부하가 걸리면 사이트 소유자에게 문제가 발생할 수 있습니다.
고급 기술
- 웹 스크래핑 프레임워크 : 다양한 크롤링 문제를 처리하는 기능이 내장된 Scrapy와 같은 프레임워크 사용을 고려해보세요.
- CAPTCHA 해결 서비스 : CAPTCHA 문제가 있는 사이트의 경우 CAPTCHA를 해결할 수 있는 서비스가 있지만 이를 사용하면 윤리적 문제가 발생합니다.
Python의 최고의 웹 크롤링 방법
웹 크롤링 활동에 참여하려면 기술적 효율성과 윤리적 책임 사이의 균형이 필요합니다. 웹 크롤링에 Python을 사용할 때는 데이터와 해당 데이터가 소스인 웹 사이트를 존중하는 모범 사례를 준수하는 것이 중요합니다. 다음은 Python의 웹 크롤링에 대한 몇 가지 주요 고려 사항과 모범 사례입니다.
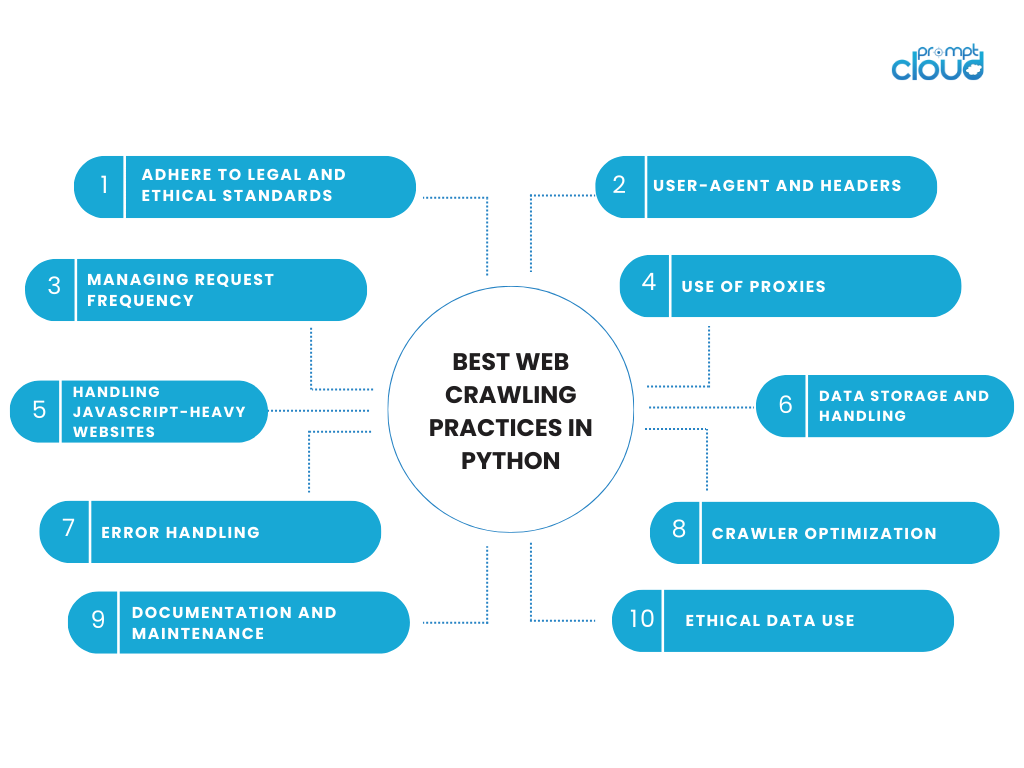
법적 및 윤리적 기준을 준수합니다.
- robots.txt 존중: 항상 웹사이트의 robots.txt 파일을 확인하세요. 이 파일은 웹사이트 소유자가 크롤링을 원하지 않는 사이트 영역을 간략하게 설명합니다.
- 서비스 약관 준수: 많은 웹사이트에는 서비스 약관에 웹 스크래핑에 대한 조항이 포함되어 있습니다. 이러한 조건을 준수하는 것은 윤리적이고 법적으로 신중한 일입니다.
- 서버 과부하 방지: 웹사이트 서버에 과도한 부하가 가해지지 않도록 합리적인 속도로 요청하세요.
사용자 에이전트 및 헤더
- 본인 확인: 연락처 정보나 크롤링 목적이 포함된 사용자 에이전트 문자열을 사용하세요. 이러한 투명성은 신뢰를 구축할 수 있습니다.
- 헤더를 적절하게 사용: HTTP 헤더를 잘 구성하면 차단될 가능성을 줄일 수 있습니다. 여기에는 사용자 에이전트, 수락 언어 등과 같은 정보가 포함될 수 있습니다.
요청 빈도 관리
- 지연 추가: 인간의 탐색 패턴을 모방하기 위해 요청 사이에 지연을 구현합니다. Python의 time.sleep() 함수를 사용하십시오.
- 속도 제한: 주어진 시간 내에 웹사이트에 보내는 요청 수를 확인하세요.
프록시 사용
- IP 순환: 프록시를 사용하여 IP 주소를 순환하면 IP 기반 차단을 피하는 데 도움이 될 수 있지만 책임감 있고 윤리적으로 수행되어야 합니다.
JavaScript가 많은 웹사이트 처리하기
- 동적 콘텐츠: JavaScript를 사용하여 콘텐츠를 동적으로 로드하는 사이트의 경우 Selenium 또는 Puppeteer(Python용 Pyppeteer와 결합)와 같은 도구를 사용하여 페이지를 브라우저처럼 렌더링할 수 있습니다.
데이터 저장 및 처리
- 데이터 저장: 데이터 개인 정보 보호법 및 규정을 고려하여 크롤링된 데이터를 책임감 있게 저장합니다.
- 데이터 추출 최소화: 필요한 데이터만 추출합니다. 꼭 필요하고 합법적인 경우가 아니면 개인정보나 민감한 정보를 수집하지 마세요.
오류 처리
- 강력한 오류 처리: 시간 초과, 서버 오류 또는 로드 실패 콘텐츠와 같은 문제를 관리하기 위해 포괄적인 오류 처리를 구현합니다.
크롤러 최적화
- 확장성: 크롤링되는 페이지 수와 처리되는 데이터 양 측면에서 규모 증가를 처리할 수 있도록 크롤러를 설계합니다.
- 효율성: 효율성을 위해 코드를 최적화합니다. 효율적인 코드는 시스템과 대상 서버 모두의 부하를 줄여줍니다.
문서화 및 유지 관리
- 문서 보관: 향후 참조 및 유지 관리를 위해 코드와 크롤링 논리를 문서화합니다.
- 정기 업데이트: 특히 대상 웹사이트의 구조가 변경되는 경우 크롤링 코드를 최신 상태로 유지하세요.
윤리적인 데이터 사용
- 윤리적 활용: 수집한 데이터를 사용자 개인 정보 보호 및 데이터 사용 규범을 존중하면서 윤리적으로 사용하십시오.
결론적으로
Python으로 웹 크롤러를 구축하는 과정을 마무리하면서 자동화된 데이터 수집의 복잡성과 이에 따른 윤리적 고려 사항을 살펴보았습니다. 이러한 노력은 우리의 기술적 능력을 향상시킬 뿐만 아니라 광대한 디지털 환경에서 책임 있는 데이터 처리에 대한 이해를 심화시킵니다.
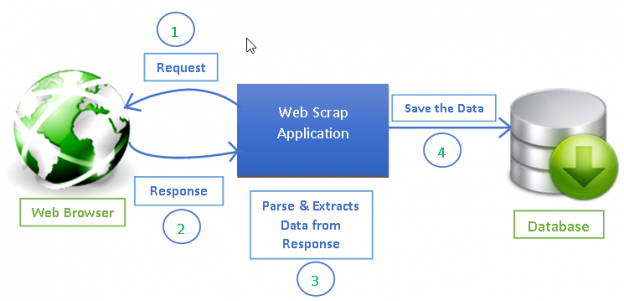
출처: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
그러나 웹 크롤러를 생성하고 유지 관리하는 것은 복잡하고 시간이 많이 걸리는 작업일 수 있으며, 특히 특정 대규모 데이터 요구 사항이 있는 기업의 경우 더욱 그렇습니다. PromptCloud의 맞춤형 웹 스크래핑 서비스가 작동하는 곳입니다. 웹 데이터 요구 사항에 맞는 효율적이고 윤리적인 맞춤형 솔루션을 찾고 있다면 PromptCloud는 귀하의 고유한 요구 사항에 맞는 다양한 서비스를 제공합니다. 복잡한 웹사이트 처리부터 깨끗하고 구조화된 데이터 제공에 이르기까지 웹 스크래핑 프로젝트가 번거롭지 않고 비즈니스 목표에 부합하도록 보장합니다.
자체 웹 크롤러를 개발하고 관리할 시간이나 기술 전문 지식이 없는 기업과 개인의 경우 이 작업을 PromptCloud와 같은 전문가에게 아웃소싱하면 게임 체인저가 될 수 있습니다. 이들 서비스는 시간과 자원을 절약할 뿐만 아니라 법적 및 윤리적 표준을 준수하면서 가장 정확하고 관련성 있는 데이터를 얻을 수 있도록 보장합니다.
PromptCloud가 특정 데이터 요구 사항을 어떻게 충족할 수 있는지 자세히 알아보고 싶으십니까? 자세한 내용을 알아보고 맞춤형 웹 스크래핑 솔루션이 귀하의 비즈니스를 발전시키는 데 어떻게 도움이 될 수 있는지 논의하려면 sales@promptcloud.com으로 연락하세요.
웹 데이터의 역동적인 세계에서 PromptCloud와 같은 신뢰할 수 있는 파트너가 있으면 비즈니스에 힘을 실어 데이터 중심 의사 결정에서 우위를 점할 수 있습니다. 데이터 수집 및 분석 영역에서는 올바른 파트너가 모든 변화를 가져온다는 점을 기억하십시오.
즐거운 데이터 헌팅!