
LLM용 추론 엔진 선택 및 구성
게시 됨: 2024-04-02추론 엔진 소개
추론 프로세스의 여러 단계에서 발생하는 비효율성을 완화하기 위해 개발된 많은 최적화 기술이 있습니다. 바닐라 변환기/기술을 사용하여 추론을 대규모로 확장하는 것은 어렵습니다. 추론 엔진은 최적화를 하나의 패키지로 마무리하고 추론 프로세스를 쉽게 해줍니다.
매우 작은 임시 테스트 세트 또는 빠른 참조를 위해 바닐라 변환기 코드를 사용하여 추론을 수행할 수 있습니다.
추론 엔진의 환경은 빠르게 진화하고 있습니다. 다양한 선택이 가능하기 때문에 특정 사용 사례에 대해 최선을 테스트하고 목록을 작성하는 것이 중요합니다. 아래에는 우리가 수행한 몇 가지 추론 엔진 실험과 그것이 우리 사례에 효과가 있었던 이유를 알아낸 이유가 나와 있습니다.
미세 조정된 Vicuna-7B 모델을 위해 우리는 다음을 시도했습니다.
- TGI
- vLLM
- 아프로디테
- 최적-Nvidia
- 파워인퍼
- 라마CPP
- Ctranslate2
우리는 이러한 엔진을 설정하기 위해 github 페이지와 빠른 시작 가이드를 검토했습니다. PowerInfer, LlaamaCPP, Ctranslate2는 그다지 유연하지 않으며 언급된 다른 엔진과 비교할 때 지속적인 일괄 처리, 페이징 주의 및 하위 수준 성능 유지와 같은 많은 최적화 기술을 지원하지 않습니다. .
더 높은 처리량을 얻으려면 추론 엔진/서버가 메모리와 컴퓨팅 기능을 최대화해야 하며 클라이언트와 서버 모두 요청을 처리하는 병렬/비동기 방식으로 작동하여 서버가 항상 작동하도록 해야 합니다. 앞서 언급했듯이 PagedAttention, Flash Attention, Continuous 일괄 처리와 같은 최적화 기술의 도움이 없으면 항상 최적이 아닌 성능으로 이어질 것입니다.
이와 관련하여 TGI, vLLM 및 Aphrodite가 더 적합한 후보이며 아래에 설명된 여러 실험을 수행하여 추론에서 최대 성능을 끌어낼 수 있는 최적의 구성을 찾았습니다. 지속적인 일괄 처리 및 페이징 주의와 같은 기술은 기본적으로 활성화되어 있으며, 아래 테스트를 위해 추론 엔진에서 추론적 디코딩을 수동으로 활성화해야 합니다.
추론 엔진의 비교 분석
TGI
TGI를 사용하려면 github 페이지의 '시작하기' 섹션을 통해 이동할 수 있습니다. 여기에서 docker는 TGI 엔진을 구성하고 사용하는 가장 간단한 방법입니다.
텍스트 생성 실행기 인수 -> 이 목록은 서버 측에서 사용할 수 있는 다양한 설정을 나열합니다. 중요한 몇 가지,
- –max-input-length : 모델에 대한 입력의 최대 길이를 결정합니다. 기본값은 1024이므로 대부분의 경우 변경이 필요합니다.
- –max-total-tokens: 최대 총 토큰, 즉 입력 + 출력 토큰 길이.
- –speculate, –Quantiz, –max-concurrent-requests -> 기본값은 128이며 분명히 더 적습니다.
로컬 미세 조정 모델을 시작하려면
docker run –gpus 장치=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
허브에서 모델을 시작하려면
모델 =”lmsys/vicuna-7b-v1.5″; 볼륨=$PWD/데이터; 토큰=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
더 자세한 이해를 위해 chatGPT에 위 명령에 대한 설명을 요청할 수 있습니다. 여기서는 9091 포트에서 추론 서버를 시작합니다. 그리고 모든 언어의 클라이언트를 사용하여 서버에 요청을 게시할 수 있습니다. 텍스트 생성 추론 API -> 요청을 위한 모든 엔드포인트 및 페이로드 매개변수를 언급합니다.
예:
페이로드=”<여기에 프롬프트 표시>”
컬 -XPOST "0.0.0.0:9091/생성" -H "콘텐츠 유형: 애플리케이션/json" -d "{"입력": $payload, "매개변수": {"max_new_tokens": 400,"do_sample":false ,"best_of": null,"repetition_penalty": 1,"return_full_text": false, "seed": null, "stop_sequences": null, "온도": 0.1, "top_k": 100, "top_p": 0.3," 자르기”: null,”전형적인_p”: null,”워터마크”: false,”decoder_input_details”: false}}”
관찰이 거의 없고,
- max-token-tokens에 따라 지연 시간이 증가합니다. 이는 긴 텍스트를 처리하는 경우 전체 시간이 증가한다는 것이 명백합니다.
- 추측은 도움이 되지만 사용 사례 및 입출력 분포에 따라 다릅니다.
- Eetq 양자화는 처리량을 높이는 데 가장 큰 도움이 됩니다.
- 다중 GPU가 있는 경우 각 GPU에서 1개의 API를 실행하고 로드 밸런서 뒤에 이러한 다중 GPU API를 사용하면 TGI 자체에 의한 샤딩보다 처리량이 더 높아집니다.
vLLM
vLLM 서버를 시작하려면 OpenAI 호환 REST API 서버/도커를 사용할 수 있습니다. 시작하는 것은 매우 간단합니다. Docker를 사용한 배포 — vLLM을 따르십시오. 로컬 모델을 사용하려는 경우 볼륨을 연결하고 경로를 모델 이름으로 사용하십시오.
도커 실행 –런타임 nvidia –gpus 장치=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – 모델/모델
위에서는 언급된 8000 포트에서 vLLM 서버를 시작합니다. 항상 인수를 가지고 놀 수 있습니다.
다음으로 게시물을 요청하세요.
“`껍질
페이로드=”<여기에 프롬프트 표시>”
컬 -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Content-Type: application/json” -d “{“prompt”: $payload,”model”:”/model” ,”max_tokens ": 400,"top_p": 0.3, "top_k": 100, "온도": 0.1}"

“``
아프로디테
“`껍질
pip 설치 아프로디테 엔진
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“``
또는
“``
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus 장치=1 –ipc 호스트 alpindale/aphrodite-engine
“``
Aphrodite는 시작하기 섹션에서 언급한 대로 pip와 docker 설치를 모두 제공합니다. Docker는 일반적으로 가동 및 테스트가 비교적 쉽습니다. 사용 옵션, 서버 옵션은 요청 방법을 도와줍니다.
- Aphrodite와 vLLM은 모두 openAI 서버 기반 페이로드를 사용하므로 해당 문서를 확인할 수 있습니다.
- 우리는 deepspeed-mii를 시도했는데, 레거시에서 새로운 코드베이스로 전환하는 상태이기 때문에(시도했을 때) 안정적이고 사용하기 쉬워 보이지 않았습니다.
- Optimum-NVIDIA는 다른 주요 최적화를 지원하지 않으며 차선의 성능을 초래합니다. 참조 링크.
- 임시 병렬 요청을 수행하는 데 사용한 코드인 요점을 추가했습니다.
측정항목 및 측정
우리는 다음을 시도하고 찾아보고 싶습니다:
- 최적의 번호 클라이언트/추론 엔진 서버용 스레드.
- 메모리 증가에 따른 처리량 증가 방법
- 텐서 코어를 통해 처리량이 증가하는 방법.
- 스레드와 클라이언트의 병렬 요청의 효과.
활용도를 관찰하는 가장 기본적인 방법은 Linux 유틸리티 nvidia-smi, nvtop을 통해 관찰하는 것입니다. 이를 통해 점유된 메모리, 컴퓨팅 활용도, 데이터 전송 속도 등을 알 수 있습니다.
또 다른 방법은 nsys와 함께 GPU를 사용하여 프로세스를 프로파일링하는 것입니다.
| S.No | GPU | vRAM 메모리 | 추론 엔진 | 스레드 | 시간(초) | 추측하다 |
| 1 | A6000 | 48 /48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 561 | – |
| 삼 | A6000 | 48 /48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 568 | – |
위의 실험에 따르면 128/256 스레드가 낮은 스레드 수보다 낫고 256 오버헤드를 초과하면 처리량이 감소하는 데 기여합니다. 이는 CPU와 GPU에 의존하는 것으로 확인되었으며, 자체적인 실험이 필요합니다. | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 945 | 8 |
추측 값이 높을수록 미세 조정된 모델이 더 많이 거부되어 처리량이 감소합니다. 추측 값의 1 / 2는 괜찮습니다. 이는 모델에 따라 다르며 사용 사례 전체에서 동일하게 작동한다고 보장되지는 않습니다. 그러나 결론은 추측적 디코딩이 처리량을 향상시킨다는 것입니다. | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 481 | 2 |
4090은 A6000에 비해 vRAM이 적음에도 불구하고 더 높은 텐서 코어 수와 메모리 대역폭 속도로 인해 성능이 뛰어납니다. | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2개의 24/48GB | TGI | 128 | 1205 | 2 |
높은 처리량을 위한 TGI 설정 및 구성
python/ruby와 같이 선택한 스크립팅 언어로 비동기 요청을 설정하고 우리가 찾은 구성에 동일한 파일을 사용합니다.
- 시퀀스 생성의 최대 출력 길이에 따라 소요되는 시간이 늘어납니다.
- 클라이언트와 서버의 128/256 스레드는 24, 64, 512보다 낫습니다. 더 낮은 스레드를 사용하면 컴퓨팅 활용도가 낮아지고 128과 같은 임계값을 초과하면 오버헤드가 높아져 처리량이 감소합니다.
- Go, Python/Ruby와 같은 언어로 스레딩하는 대신 'GNU 병렬'을 사용하여 비동기 요청에서 병렬 요청으로 점프할 때 6% 개선이 있습니다.
- 4090은 A6000보다 처리량이 12% 더 높습니다. 4090은 A6000에 비해 vRAM이 적음에도 불구하고 더 높은 텐서 코어 수와 메모리 대역폭 속도로 인해 성능이 뛰어납니다.
- A6000에는 48GB vRAM이 있으므로 추가 RAM이 처리량 향상에 도움이 되는지 결론을 내리기 위해 표의 실험 8에서 GPU 메모리의 일부를 사용해 보았습니다. 추가 RAM이 개선에 도움이 되지만 선형적으로는 도움이 되지 않는다는 것을 알 수 있습니다. 또한 분할을 시도하면(예: 각 API에 대해 절반의 메모리를 사용하여 동일한 GPU에서 2개의 API 호스팅) 요청을 병렬로 수락하는 대신 2개의 순차적 API가 실행되는 것처럼 동작합니다.
관찰 및 지표
아래는 일부 실험에 대한 그래프이며 고정 입력 세트를 완료하는 데 걸리는 시간은 낮을수록 좋습니다.
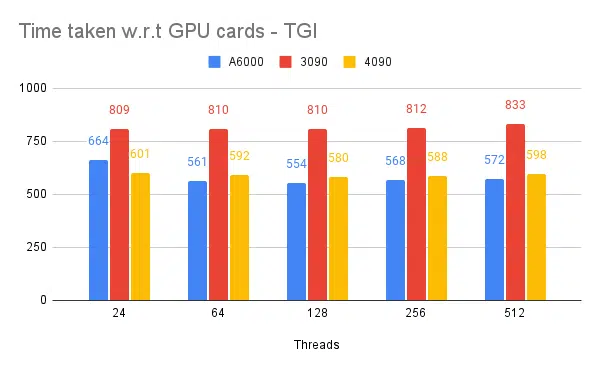
- 클라이언트 측 스레드가 언급되었습니다. 추론 엔진을 시작하는 동안 서버 측에 대해 언급해야 합니다.
테스트 추측:

다중 추론 엔진 테스트:
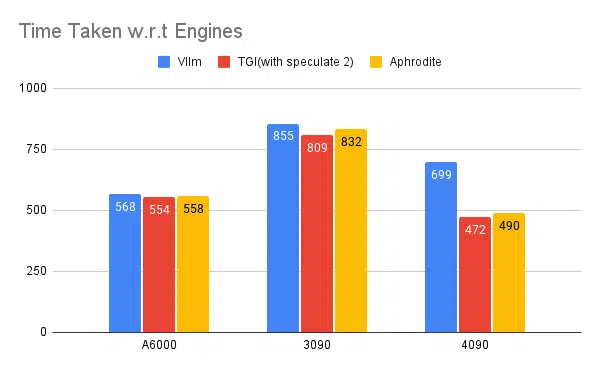
vLLM 및 Aphrodite와 같은 다른 엔진에서 수행된 동일한 종류의 실험에서 유사한 결과가 관찰되었습니다. 이 기사를 작성할 당시 vLLM 및 Aphrodite는 아직 추측 디코딩을 지원하지 않으므로 나머지보다 더 높은 처리량을 제공하므로 TGI를 선택하게 됩니다. 추측적 디코딩.
또한 관찰 가능성을 향상시켜 과도한 리소스 사용량이 있는 영역을 식별하고 성능을 최적화하도록 GPU 프로파일러를 구성할 수 있습니다. 추가 자료: Nvidia Nsight 개발자 도구 - Max Katz
결론
추론 생성 환경은 지속적으로 발전하고 있으며 LLM의 처리량을 개선하려면 GPU, 성능 지표, 최적화 기술 및 텍스트 생성 작업과 관련된 과제에 대한 올바른 이해가 필요합니다. 이는 작업에 적합한 도구를 선택하는 데 도움이 됩니다. GPU 내부와 텐서 코어 활용, 메모리 대역폭 최대화 등 GPU 내부가 LLM 추론에 어떻게 대응하는지 이해함으로써 개발자는 비용 효율적인 GPU를 선택하고 성능을 효과적으로 최적화할 수 있습니다.
다양한 GPU 카드는 다양한 기능을 제공하므로 특정 작업에 가장 적합한 하드웨어를 선택하려면 차이점을 이해하는 것이 중요합니다. 지속적인 일괄 처리, 페이징 주의, 커널 융합 및 플래시 주의와 같은 기술은 발생하는 문제를 극복하고 효율성을 향상시킬 수 있는 유망한 솔루션을 제공합니다. 우리가 얻은 실험과 결과를 바탕으로 TGI는 우리 사용 사례에 가장 적합한 선택으로 보입니다.
대규모 언어 모델과 관련된 다른 기사를 읽어보세요.
LLM 추론 최적화를 위한 GPU 아키텍처 이해
LLM 처리량 향상을 위한 고급 기술