
R 및 Python을 사용하여 BigQuery에 데이터를 업로드하는 방법
게시 됨: 2023-06-06웹 분석 세계는 Universal Analytics가 데이터 처리를 중단하고 Google Analytics 4(GA4)로 대체되는 운명적인 7월 1일을 향해 계속 돌진하고 있습니다. 주요 변경 사항 중 하나는 GA4에서 최대 14개월 동안만 플랫폼에 데이터를 유지할 수 있다는 것입니다. 이것은 UA의 주요 변경 사항이지만 이에 대한 대가로 GA4 데이터를 무료로 BigQuery에 최대 제한까지 푸시할 수 있습니다.
BigQuery는 GA4 이후의 데이터 스토리지에 매우 유용한 리소스입니다. 몇 달 만에 그 어느 때보다 중요해짐에 따라 모든 데이터 스토리지 요구 사항에 사용하기 시작하는 것이 그 어느 때보다 좋습니다. 종종 업로드하기 전에 어떤 방식으로든 데이터를 조작하는 것이 좋습니다. 이를 위해 특히 이러한 종류의 조작을 반복적으로 수행해야 하는 경우 R 또는 Python으로 작성된 스크립트를 사용하는 것이 좋습니다. 또한 이러한 스크립트에서 바로 BigQuery에 데이터를 업로드할 수 있으며, 이것이 바로 이 블로그에서 안내할 내용입니다.
R에서 BigQuery로 업로드
R은 데이터 과학을 위한 매우 강력한 언어이며 BigQuery에 데이터를 업로드하기 위해 가장 쉽게 사용할 수 있는 언어입니다. 첫 번째 단계는 필요한 모든 라이브러리를 가져오는 것입니다. 이 튜토리얼에서는 다음 라이브러리가 필요합니다.
library(googleAuthR)
library(bigQueryR)
이전에 이러한 라이브러리를 사용한 적이 없다면 콘솔에서 install.packages(<PACKAGE NAME>) 실행하여 설치하십시오.
다음으로 API 작업에서 가장 까다롭고 지속적으로 가장 실망스러운 부분인 권한 부여를 해결해야 합니다. 다행스럽게도 R을 사용하면 비교적 간단합니다. 인증 자격 증명이 포함된 JSON 파일이 필요합니다. 이는 BigQuery가 있는 곳과 동일한 Google Cloud Console에서 찾을 수 있습니다. 먼저 Google Cloud Console로 이동하여 'API 및 서비스'를 클릭합니다.
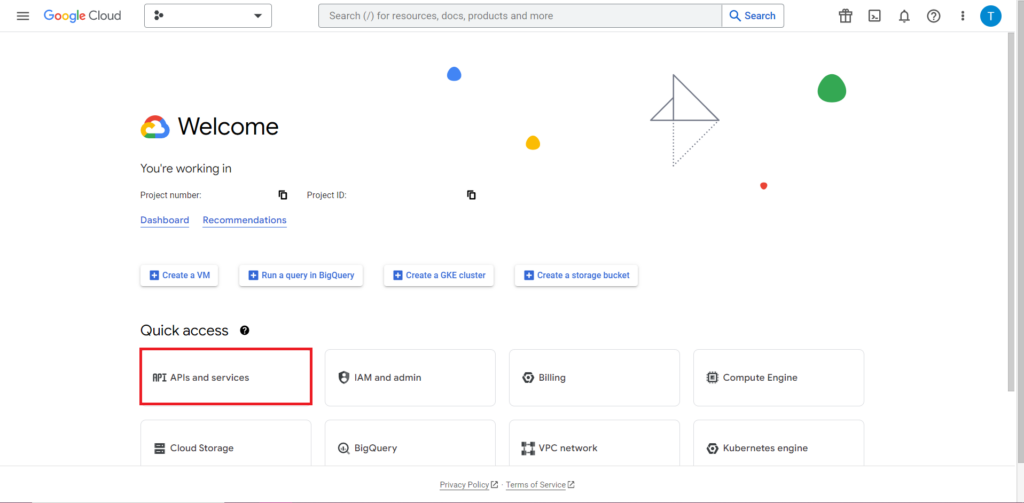
그런 다음 사이드바에서 '자격 증명'을 클릭합니다.
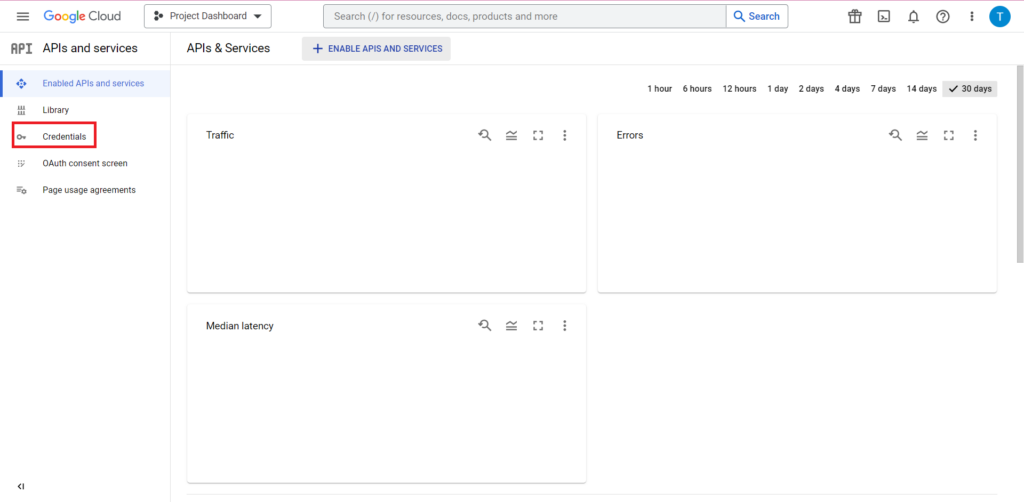
자격 증명 페이지에서 기존 API 키, OAuth 2.0 클라이언트 ID 및 서비스 계정을 볼 수 있습니다. 이를 위해 OAuth 2.0 클라이언트 ID가 필요하므로 해당 ID 행의 맨 끝에 있는 다운로드 버튼을 누르거나 페이지 상단의 '자격증명 만들기'를 클릭하여 새 ID를 만드세요. ID에 관련 BigQuery 프로젝트를 보고 수정할 수 있는 권한이 있는지 확인하세요. 이렇게 하려면 사이드바를 열고 'IAM 및 관리자' 위로 마우스를 가져간 다음 'IAM'을 클릭하세요. 이 페이지에서 페이지 상단의 '액세스 권한 부여' 버튼을 사용하여 해당 프로젝트에 대한 서비스 계정 액세스 권한을 부여할 수 있습니다.
JSON 파일을 얻고 저장하면 gar_set_client() 함수로 경로를 전달하여 자격 증명을 설정할 수 있습니다. 승인을 위한 전체 코드는 다음과 같습니다.
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
gar_set_client() 함수의 경로를 자신의 JSON 파일 경로로 바꾸고 BigQuery에 액세스하는 데 사용하는 이메일 주소를 bqr_auth() 함수에 삽입하는 것이 좋습니다.
승인이 모두 설정되면 BigQuery에 업로드할 일부 데이터가 필요합니다. 이 데이터를 데이터 프레임에 넣어야 합니다. 이 문서의 목적을 위해 여러 위치와 판매량이 포함된 가상의 데이터를 만들 예정이지만 대부분의 경우 .csv 파일이나 스프레드시트에서 실제 데이터를 읽을 것입니다. .csv 파일에서 데이터를 읽으려면 read.csv() 함수를 사용하여 파일 경로를 인수로 전달하면 됩니다.
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
또는 스프레드시트에 데이터를 저장한 경우 이 스프레드시트의 위치에 따라 방법이 달라집니다. 스프레드시트가 Google 스프레드시트에 저장된 경우 googlesheets4 라이브러리를 사용하여 해당 데이터를 R로 읽을 수 있습니다.
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
이전과 마찬가지로 이전에 이 패키지를 사용한 적이 없다면 코드를 실행하기 전에 콘솔에서 install.packages(“googlesheets4”)를 실행해야 합니다.
스프레드시트가 Excel 형식인 경우 tidyverse 라이브러리의 일부인 readxl 라이브러리를 사용해야 합니다. 사용을 권장합니다. 여기에는 R에서 데이터 조작을 훨씬 쉽게 해주는 수많은 함수가 포함되어 있습니다.
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
그리고 다시 한 번, 이전에 실행하지 않았다면 install.package(“tidyverse”)를 실행해야 합니다!
마지막 단계는 BigQuery에 데이터를 업로드하는 것입니다. 이를 위해서는 BigQuery에 업로드할 위치가 필요합니다. 테이블은 프로젝트 내에 위치할 데이터 세트 내에 위치하며 다음 형식으로 세 가지 모두의 이름이 필요합니다.
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
제 경우에 이것은 제 코드가 다음과 같다는 것을 의미합니다.
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
테이블이 아직 존재하지 않더라도 걱정하지 마십시오. 코드가 자동으로 테이블을 생성합니다. 프로젝트, 데이터 세트 및 테이블의 이름을 위의 코드에(인용 부호 안에) 삽입하고 올바른 데이터 프레임을 업로드하고 있는지 확인하는 것을 잊지 마십시오! 이 작업이 완료되면 아래와 같이 BigQuery에 데이터가 표시됩니다.
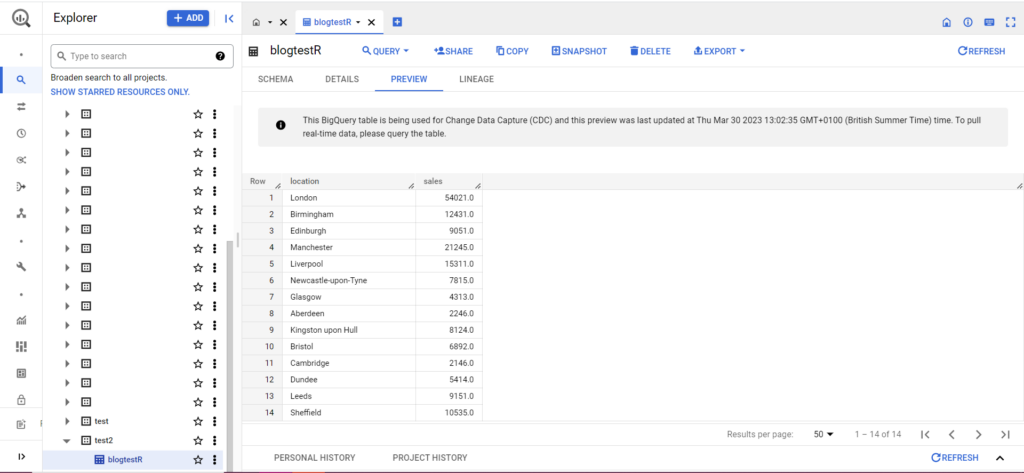
마지막 단계로 BigQuery에 추가하고 싶은 추가 데이터가 있다고 가정해 보겠습니다. 예를 들어 위의 데이터에서 대륙의 위치 몇 개를 포함하는 것을 잊고 BigQuery에 업로드하고 싶지만 기존 데이터를 덮어쓰고 싶지 않다고 가정해 보겠습니다. 이를 위해 bqr_upload_data에는 writeDisposition이라는 매개변수가 있습니다. writeDisposition에는 "WRITE_TRUNCATE" 및 "WRITE_APPEND"의 두 가지 설정이 있습니다. 전자는 테이블의 기존 데이터를 덮어쓰도록 bqr_upload_data()에 지시하고 후자는 새 데이터를 추가하라고 지시합니다. 따라서 이 새 데이터를 업로드하기 위해 다음과 같이 작성합니다.

bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
물론 BigQuery에서 데이터에 새로운 룸메이트가 있음을 알 수 있습니다.
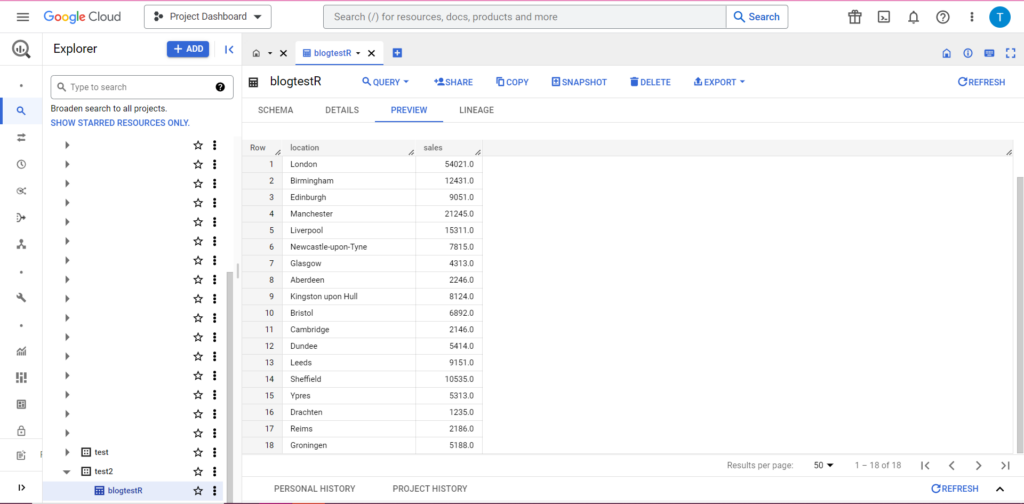
Python에서 BigQuery로 업로드
파이썬에서는 상황이 조금 다릅니다. 다시 한 번 일부 패키지를 가져와야 하므로 다음부터 시작하겠습니다.
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
권한 부여가 복잡합니다. 다시 한 번 자격 증명이 포함된 JSON 파일이 필요합니다. 위와 같이 Google Cloud Console로 이동하여 'API 및 서비스'를 클릭한 다음 사이드바에서 'Credentials'를 클릭합니다. 이번에는 페이지 하단에 '서비스 계정'이라는 섹션이 있습니다.
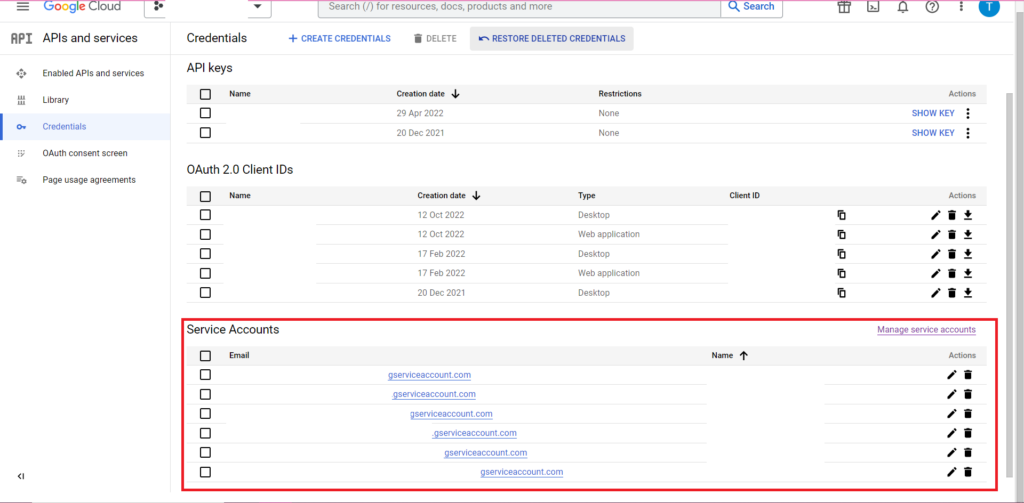
여기에서 서비스 계정에 대한 키를 다운로드하거나 '서비스 계정 관리'를 클릭하여 자격 증명을 다운로드할 수 있는 새 키 또는 새 서비스 계정을 만들 수 있습니다.
그런 다음 서비스 계정에 BigQuery 프로젝트에 액세스하고 수정할 수 있는 권한이 있는지 확인해야 합니다. 다시 한 번 사이드바의 'IAM 및 관리자' 아래 IAM 페이지로 이동하고 페이지 상단의 '액세스 권한 부여' 버튼을 사용하여 관련 프로젝트에 대한 서비스 계정 액세스 권한을 부여할 수 있습니다.
정리가 완료되면 인증 코드를 작성할 수 있습니다.
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
다음으로 데이터를 데이터 프레임으로 가져와야 합니다. 데이터 프레임은 pandas 패키지에 속하며 생성이 매우 간단합니다. CSV에서 읽으려면 다음 예를 따르십시오.
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
당연히 위의 경로를 자신의 CSV 파일로 바꿔야 합니다. Excel 파일에서 읽으려면 다음 예를 따르십시오.
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Google 스프레드시트에서 읽기는 까다로우며 추가 승인이 필요합니다. 몇 가지 새 패키지를 가져와서 위의 R 자습서에서 검색한 JSON 자격 증명 파일을 사용해야 합니다. 이 코드에 따라 데이터를 승인하고 읽을 수 있습니다.
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
데이터 프레임에 데이터가 있으면 BigQuery에 다시 한 번 업로드할 차례입니다! 다음 템플릿에 따라 이 작업을 수행할 수 있습니다.
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
예를 들어, 이전에 만든 데이터를 업로드하기 위해 방금 작성한 코드는 다음과 같습니다.
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
이 작업이 완료되면 데이터가 BigQuery에 즉시 나타납니다!
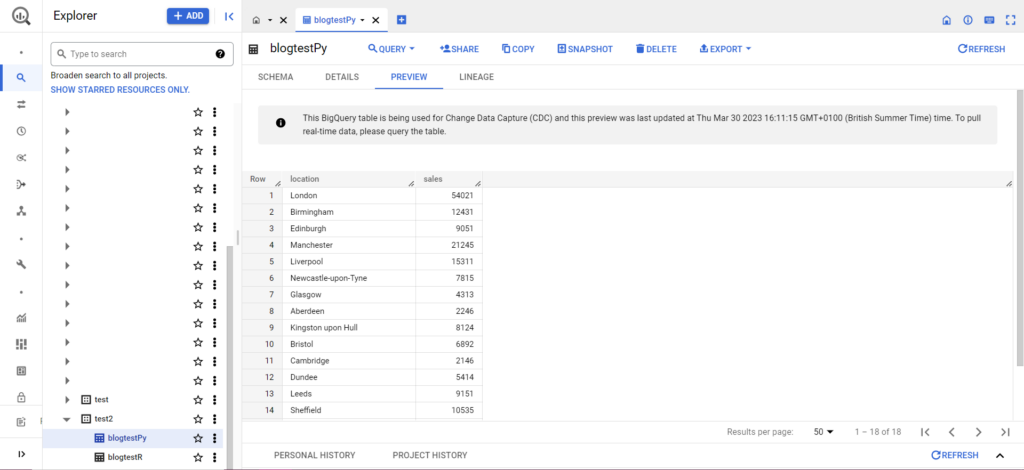
이러한 기능에 익숙해지면 이러한 기능으로 더 많은 작업을 수행할 수 있습니다. 분석 설정을 더 잘 제어하고 싶다면 Semetrical이 도와드리겠습니다! 데이터를 최대한 활용하는 방법에 대한 자세한 내용은 블로그를 확인하세요. 또는 모든 분석에 대한 추가 지원이 필요하면 Web Analytics로 이동하여 어떻게 도움을 받을 수 있는지 알아보십시오.