
웹 스크래핑 과제 및 솔루션: 복잡성 탐색
게시 됨: 2023-09-13웹 스크래핑은 웹사이트에서 데이터를 추출하는 데 매우 유용한 기술이 되었습니다. 연구 목적으로 정보를 수집하거나, 가격이나 추세를 추적하거나, 특정 온라인 작업을 자동화해야 하는 경우 웹 스크래핑을 사용하면 시간과 노력을 절약할 수 있습니다. 웹사이트의 복잡한 부분을 탐색하고 다양한 웹 스크래핑 문제를 해결하는 것은 어려운 작업이 될 수 있습니다. 이 기사에서는 웹 스크래핑 프로세스에 대한 포괄적인 이해를 통해 이를 단순화하는 방법을 살펴보겠습니다. 적절한 도구 선택, 대상 데이터 식별, 웹 사이트 구조 탐색, 인증 및 보안 문자 처리, 동적 콘텐츠 처리 등 관련 단계를 다룹니다.
웹 스크래핑 이해
웹 스크래핑은 HTML, CSS 코드 분석 및 파싱을 통해 웹사이트에서 데이터를 추출하는 절차입니다. 여기에는 웹 페이지에 HTTP 요청을 보내고, HTML 콘텐츠를 검색하고, 이어서 관련 정보를 추출하는 작업이 포함됩니다. 소스 코드를 검사하고 데이터를 복사하는 수동 웹 스크래핑은 선택 사항이지만, 특히 광범위한 데이터 수집의 경우 비효율적이고 시간이 많이 소요되는 경우가 많습니다.
웹 스크래핑 프로세스를 자동화하기 위해 Python과 같은 프로그래밍 언어, Beautiful Soup 또는 Selenium과 같은 라이브러리, Scrapy 또는 Beautiful Soup와 같은 전용 웹 스크래핑 도구를 사용할 수 있습니다. 이러한 도구는 웹사이트와의 상호작용, HTML 구문 분석, 효율적인 데이터 추출을 위한 기능을 제공합니다.
웹 스크래핑 과제
적절한 도구 선택
웹 스크래핑 노력의 성공을 위해서는 올바른 도구를 선택하는 것이 중요합니다. 웹 스크래핑 프로젝트를 위한 도구를 선택할 때 고려해야 할 몇 가지 사항은 다음과 같습니다.
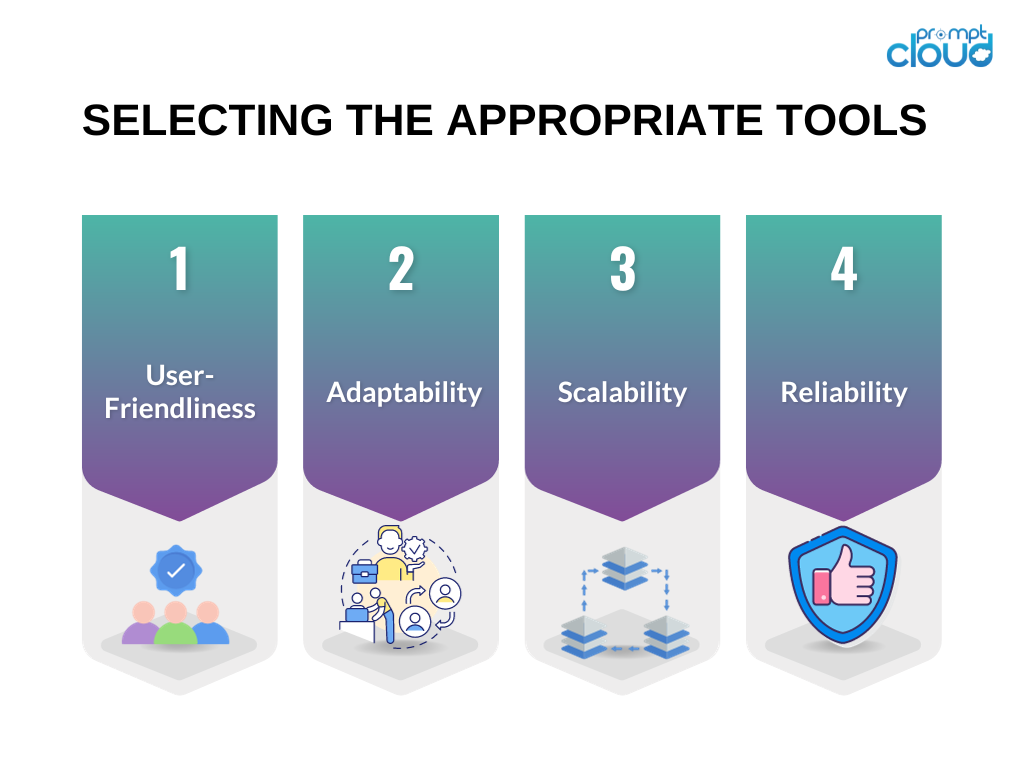
사용자 친화성 : 사용자 친화적인 인터페이스를 갖춘 도구나 명확한 문서와 실제 사례를 제공하는 도구를 우선시합니다.
적응성 : 다양한 유형의 웹사이트를 처리하고 웹사이트 구조의 변화에 적응할 수 있는 도구를 선택하세요.
확장성 : 데이터 수집 작업에 상당한 양의 데이터가 포함되거나 고급 웹 스크래핑 기능이 필요한 경우 대용량을 처리하고 병렬 처리 기능을 제공할 수 있는 도구를 고려하십시오.
신뢰성 : 연결 시간 초과 또는 HTTP 오류와 같은 다양한 오류 유형을 관리할 수 있는 도구가 갖추어져 있고 오류 처리 메커니즘이 내장되어 있는지 확인하세요.
이러한 기준에 따라 웹 스크래핑 프로젝트에는 Beautiful Soup, Selenium과 같이 널리 사용되는 도구가 자주 권장됩니다.
대상 데이터 식별
웹 스크래핑 프로젝트를 시작하기 전에 웹사이트에서 추출하려는 대상 데이터를 식별하는 것이 중요합니다. 이는 제품 정보, 뉴스 기사, 소셜 미디어 게시물 또는 기타 유형의 콘텐츠일 수 있습니다. 원하는 데이터를 효과적으로 추출하기 위해서는 타겟 웹사이트의 구조를 이해하는 것이 중요합니다.

대상 데이터를 식별하려면 Chrome DevTools 또는 Firefox 개발자 도구와 같은 브라우저 개발자 도구를 사용할 수 있습니다. 이러한 도구를 사용하면 웹페이지의 HTML 구조를 검사하고, 필요한 데이터가 포함된 특정 요소를 식별하고, 해당 데이터를 추출하는 데 필요한 CSS 선택기 또는 XPath 표현식을 이해할 수 있습니다.
웹사이트 구조 탐색
웹사이트는 중첩된 HTML 요소, 동적 JavaScript 콘텐츠 또는 AJAX 요청으로 구성된 복잡한 구조를 가질 수 있습니다. 이러한 구조를 탐색하고 관련 정보를 추출하려면 신중한 분석과 전략이 필요합니다.
복잡한 웹사이트 구조를 탐색하는 데 도움이 되는 몇 가지 기술은 다음과 같습니다.
CSS 선택기 또는 XPath 표현식 사용 : HTML 코드의 구조를 이해하면 CSS 선택기 또는 XPath 표현식을 사용하여 특정 요소를 대상으로 하고 원하는 데이터를 추출할 수 있습니다.
페이지 매김 처리 : 대상 데이터가 여러 페이지에 분산되어 있는 경우 모든 정보를 스크랩하려면 페이지 매김을 구현해야 합니다. 이는 "다음" 또는 "더 보기" 버튼을 클릭하는 프로세스를 자동화하거나 다양한 매개변수로 URL을 구성하여 수행할 수 있습니다.
중첩된 요소 처리 : 때로는 대상 데이터가 여러 수준의 HTML 요소 내에 중첩되어 있는 경우가 있습니다. 이러한 경우 원하는 정보를 추출하려면 부모-자식 관계 또는 형제 관계를 사용하여 중첩된 요소를 탐색해야 합니다.
인증 및 보안 문자 처리
일부 웹사이트에서는 자동 스크래핑을 방지하기 위해 인증이 필요하거나 보안 문자를 제시할 수 있습니다. 이러한 웹 스크래핑 문제를 극복하려면 다음 전략을 사용할 수 있습니다.
세션 관리 : 인증 요구 사항을 처리하기 위해 쿠키 또는 토큰을 사용하여 세션 상태를 유지합니다.
사용자 에이전트 스푸핑 : 다양한 사용자 에이전트를 에뮬레이션하여 일반 사용자로 표시하고 탐지를 피합니다.
보안문자 해결 서비스 : 사용자를 대신하여 보안문자를 자동으로 해결할 수 있는 타사 서비스를 사용하세요.
인증 및 보안 문자를 우회할 수 있지만 웹 스크래핑 활동이 웹 사이트의 서비스 약관 및 법적 제한 사항을 준수하는지 확인해야 합니다.
동적 콘텐츠 다루기
웹사이트에서는 종종 JavaScript를 사용하여 콘텐츠를 동적으로 로드하거나 AJAX 요청을 통해 데이터를 가져옵니다. 기존의 웹 스크래핑 방법은 이러한 동적 콘텐츠를 캡처하지 못할 수 있습니다. 동적 콘텐츠를 처리하려면 다음 접근 방식을 고려하세요.
헤드리스 브라우저 사용 : Selenium과 같은 도구를 사용하면 실제 웹 브라우저를 프로그래밍 방식으로 제어하고 동적 콘텐츠와 상호 작용할 수 있습니다.
웹 스크래핑 라이브러리 활용 : Puppeteer 또는 Scrapy-Splash와 같은 특정 라이브러리는 JavaScript 렌더링 및 동적 콘텐츠 추출을 처리할 수 있습니다.
이러한 기술을 사용하면 콘텐츠 전달을 위해 JavaScript에 크게 의존하는 웹사이트를 스크랩할 수 있습니다.
오류 처리 구현
웹 스크래핑이 항상 순조롭게 진행되는 것은 아닙니다. 웹사이트는 구조를 변경하거나, 오류를 반환하거나, 스크래핑 활동을 제한할 수 있습니다. 이러한 웹 스크래핑 문제와 관련된 위험을 완화하려면 오류 처리 메커니즘을 구현하는 것이 중요합니다.
웹사이트 변경 모니터링 : 웹사이트의 구조나 레이아웃이 변경되었는지 정기적으로 확인하고 이에 따라 스크래핑 코드를 조정하세요.
재시도 및 시간 초과 메커니즘 : 연결 시간 초과 또는 HTTP 오류와 같은 간헐적인 오류를 적절하게 처리하기 위해 재시도 및 시간 초과 메커니즘을 구현합니다.
예외 기록 및 처리 : 구문 분석 오류, 네트워크 오류 등 다양한 유형의 예외를 캡처하고 처리하여 스크래핑 프로세스가 완전히 실패하는 것을 방지합니다.
오류 처리 기술을 구현하면 웹 스크래핑 코드의 신뢰성과 견고성을 보장할 수 있습니다.
요약
결론적으로, 프로세스를 이해하고, 올바른 도구를 선택하고, 대상 데이터를 식별하고, 웹사이트 구조를 탐색하고, 인증 및 보안 문자를 처리하고, 동적 콘텐츠를 처리하고, 오류 처리 기술을 구현하면 웹 스크래핑 문제를 더 쉽게 만들 수 있습니다. 이러한 모범 사례를 따르면 웹 스크래핑의 복잡성을 극복하고 필요한 데이터를 효율적으로 수집할 수 있습니다.