
데이터 품질: 데이터에 대한 자신감을 회복하는 가장 좋은 방법
게시 됨: 2022-09-29기업은 증거 기반 통찰력을 얻기 위해 데이터를 수집합니다. 그러나 주요 의사 결정권자의 75%는 데이터를 신뢰하지 않습니다. 게다가 직원의 거의 절반이 여전히 직감에 따라 결정을 내립니다.
그러나 기업에서 데이터가 수익과 비즈니스 성장에 긍정적인 영향을 미치기를 원한다면 데이터 품질 프로세스를 수립해야 합니다. 이러한 프로세스는 직원과 의사 결정자에게 더 많은 확신을 주고 비즈니스 의사 결정을 내릴 때 데이터에 의존할 수 있는 권한을 부여합니다.
주요 내용
- 수집 시점에서 데이터를 정리하여 데이터 품질을 개선합니다. 이렇게 하면 라인을 따라 데이터를 정리할 필요가 없습니다.
- 품질 데이터에는 정확성, 완전성, 일관성, 유효성, 고유성, 무결성 및 적시성의 7가지 주요 차원이 있습니다.
- 데이터 품질을 개선하기 위한 네 가지 프로세스는 데이터 프로파일링, 데이터 거버넌스, 데이터 정리 및 데이터 표준화입니다. 이러한 작업은 수동으로 수행할 수 있지만 그렇게 하면 사람의 실수에 대한 창이 열립니다. Improvado와 같은 도구는 이러한 프로세스를 자동화하고 단순화합니다.
- 데이터 품질을 측정하기 위해 품질 차원을 사용하는 것 외에도 균형 잡힌 데이터 품질 측정 프로세스를 위해 생산성 및 참여 메트릭을 혼합에 추가하십시오.
- 데이터 품질은 마케팅 및 영업 프로세스를 투명하게 만들고 부서 간 협업을 개선하는 데 도움이 됩니다.
데이터 품질이란 무엇입니까?
데이터는 새로운 오일입니다. 정제하지 않으면 가치가 없는 기름과 마찬가지로 데이터는 사용할 수 있게 되기 전까지는 가치가 없습니다. 불행히도 데이터는 깨지기 쉬우며 쉽게 오염될 수 있습니다.
데이터 품질은 이러한 일이 발생하지 않도록 합니다. 데이터를 평가하고, 정확하고 오류가 없는지 확인하고, 귀하와 귀하의 비즈니스에 관심이 있는 통찰력의 적절한 이미지를 표시하는 프로세스입니다.
데이터 품질을 정의하는 것은 무엇입니까?
60개 이상의 데이터 품질 차원이 있습니다. 그러나 실제로 대부분의 데이터 팀은 7개에 관심을 갖고 있습니다.
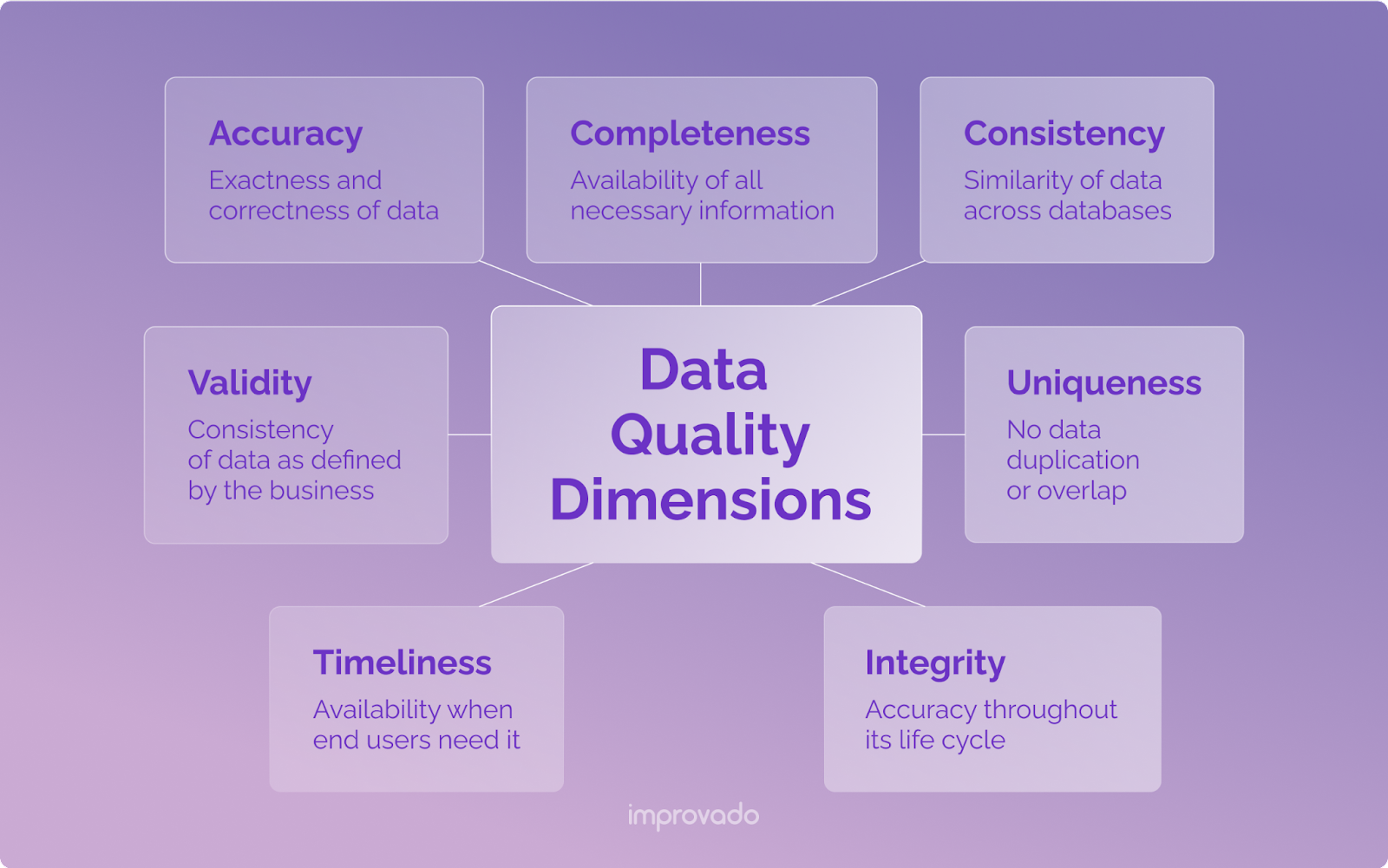
1. 정확도
이 데이터 품질 차원은 데이터의 정확성과 정확성을 나타냅니다. 정확성의 목표는 실제로 일어나는 일을 반영하는 오류 없는 데이터를 생성하는 것입니다.
이것은 일반적으로 품질 데이터의 가장 중요한 차원으로 간주됩니다.
2. 완성도
데이터에 의도된 목적에 필요한 모든 정보가 포함되어 있으면 완전한 것으로 간주됩니다. 수집된 데이터의 목적에 따라 완성도가 달라질 수 있습니다.
예를 들어 수집된 데이터의 목표가 리드를 판매로 전환하는 것이라고 가정해 보겠습니다. 마케팅 팀이 이름과 이메일만 수집하지만 영업 팀이 데모 통화를 위해 전화번호가 필요한 경우 보유한 데이터는 불완전한 것으로 간주됩니다.
3. 일관성
서로 다른 데이터베이스의 데이터는 데이터 오류를 방지하기 위해 일관성이 있어야 합니다.
이메일 마케팅 소프트웨어가 고객의 이메일 주소 변경 사항을 등록하는 경우 이 변경 사항은 CRM(고객 관계 관리) 소프트웨어에도 반영되어야 합니다. 그렇게 하지 않으면 청구 알림에 문제가 발생할 수 있습니다.
4. 유효성
데이터 유효성은 비즈니스에서 정의한 데이터 값의 일관성을 나타냅니다.
예를 들어, 유럽 기반 비즈니스는 dd-mm-yyyy 형식(2022년 9월 12일)을 사용하여 날짜 형식을 지정할 수 있습니다. 그러나 누군가 mm-dd-yyyy 형식(2022년 9월 12일)을 사용하여 쓰기 항목을 추가하면 이 데이터는 더 이상 유효하지 않습니다.
5. 독창성
고유성은 데이터 세트 간에 데이터 중복 또는 겹침이 없음을 의미합니다.
잠재 고객이 JH Watson으로 리드 마그넷에 등록했다고 가정해 보겠습니다. 그런 다음 소프트웨어를 구입할 때 이름을 John H. Watson이라고 쓰면 데이터베이스에 한 사람으로 입력해야 합니다.
6. 무결성
이 차원은 데이터가 조직의 다른 시스템 및 부서를 통해 이동할 때 전체 수명 주기에 걸쳐 데이터를 보존하는 것을 나타냅니다. 또한 데이터 변조를 방지하기 위한 프로세스가 마련되어 있음을 의미합니다.
7. 적시성
데이터의 적시성은 필요할 때마다 데이터를 사용할 수 있음을 의미합니다.
예를 들어 연간 재무 제표는 회계사가 필요할 때 준비해야 합니다. 그렇지 않은 경우 데이터 적시성 차원의 요구 사항을 충족하지 않습니다.
품질 데이터의 이점
품질 데이터는 조직의 프로세스와 비즈니스로서의 전반적인 가치에 긍정적인 영향을 미칩니다.
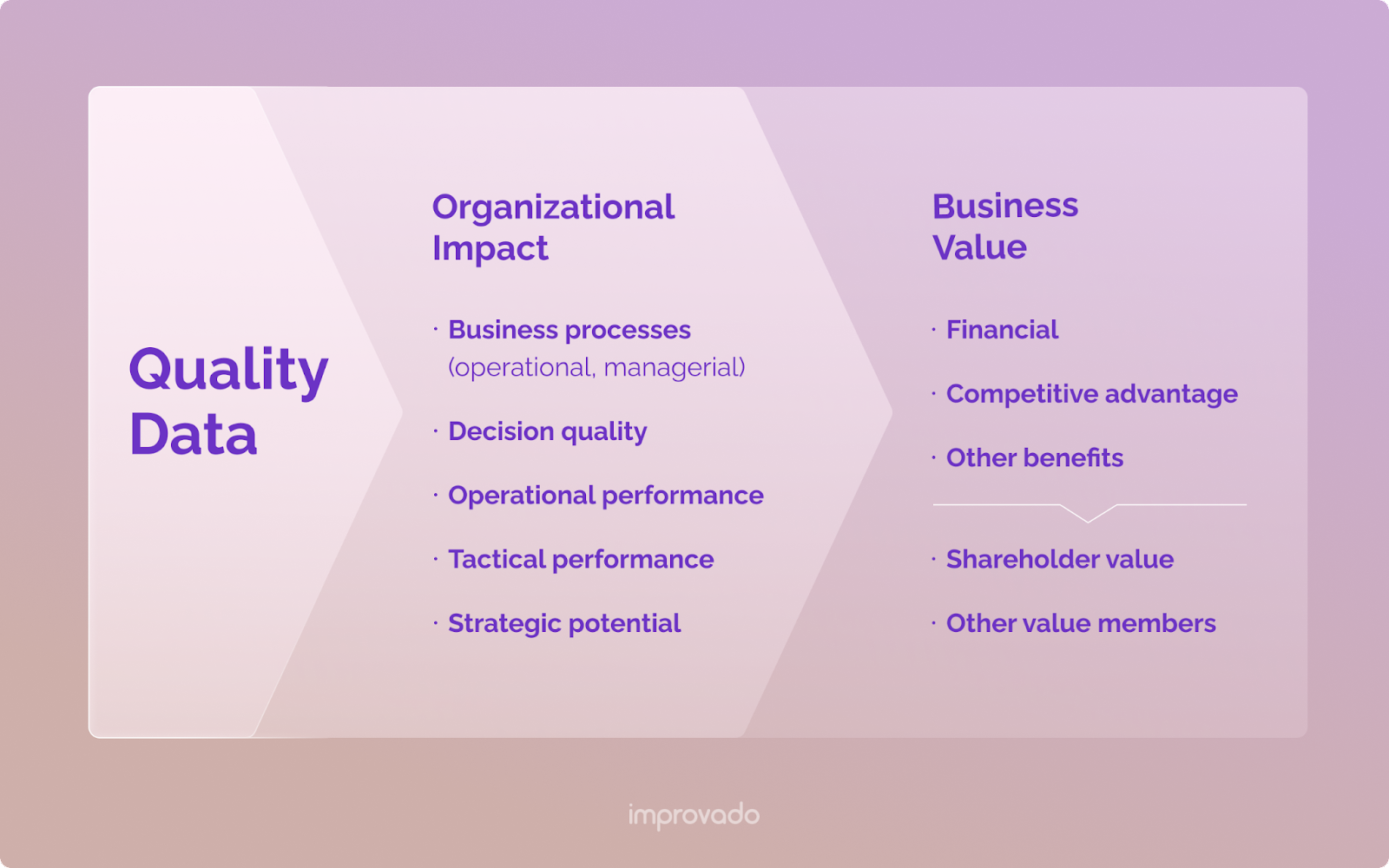
양질의 데이터 프로세스가 마련되어 있고 이를 의사 결정자에게 전달하면 데이터가 더 많이 사용되어 결국 비즈니스 의사 결정과 혁신의 기초가 됩니다.
의사 결정자가 더 빨리 통찰력을 얻을 수 있기 때문에 비즈니스 수익성과 수익이 증가합니다. 또한 사람들이 데이터를 수정하고 조정하는 데 시간을 낭비하지 않기 때문에 비즈니스 성과도 향상됩니다.
영업, 마케팅 및 고객 관리 팀을 위한 데이터 품질의 중요성
데이터 품질은 오류나 불일치를 방지하면서 서로 다른 부서와 해당 데이터 간의 정렬을 촉진합니다.
이를 통해 부서 간 협업이 더 쉬워집니다. 모든 판매 및 마케팅 활동에는 투명성이 있으며 모든 사람은 고객과 라이프사이클 전반에 걸친 여정에 대한 거시적 및 미시적 관점을 얻습니다.

데이터 프로세스가 제대로 이루어지지 않을 때 발생할 수 있는 최악의 상황은 무엇입니까?
우리는 나쁜 데이터 때문에 많은 기업들이 난처한 상황에 빠졌다는 이야기를 들었습니다.
예를 들어, 삼성은 직원이 잘못된 데이터 안전 조치로 실수를 했을 때 1,050억 달러의 손실을 입었다고 인정합니다. Uber는 회계 실수로 인해 수년 동안 운전자에게 낮은 급여를 지불했습니다. US Postal Service는 배달할 수 없는 이메일을 처리하는 데 약 15억 달러를 지출했습니다.
그리고 잘못된 데이터로 인한 마케팅 및 영업 팀의 사고에 대한 많은 이야기는 어떻습니까? 몇 가지 일반적인 사항은 다음과 같습니다.
- 마케팅 팀은 잘못된 레이블이 지정된 이메일을 보내고 있습니다. 최소한 브랜드 신뢰를 무너뜨리는 것입니다.
- PPC 팀은 비용이 많이 드는 잘못된 시장 부문을 목표로 삼고 있습니다.
- 영업 팀이 잘못되었거나 존재하지 않는 전화번호로 전화를 걸어 효율성에 영향을 미치고 있습니다.
- 고객 서비스 팀은 중복 항목으로 인해 고객에게 두 번 청구했으며 그 결과 고객이 화를 냈습니다.
이 모든 것이 나쁜 데이터가 기업을 곤경에 빠뜨릴 수 있음을 분명히 합니다.
그렇기 때문에 데이터를 비즈니스 의사 결정 및 활동의 초석으로 사용하는 모든 비즈니스에서 양질의 데이터가 우선 순위가 되어야 합니다. 양질의 데이터는 그들이 한 일, 일어날 수 있는 일, 수익 증대를 위해 할 수 있는 일에 대한 정확한 그림을 제공할 것입니다.
데이터 품질 측정 방법
현재로서는 데이터 품질을 측정하기 위한 확립된 표준이 없습니다. 조직은 지침을 설정하고 데이터 관리 및 거버넌스에 대한 기준선과 기대치를 설정해야 합니다.
일반적으로 데이터 품질 측정기준은 측정항목으로 사용됩니다. 각 메트릭에는 산업 또는 데이터 세트의 목적에 따라 가중치와 중요도가 할당됩니다. 예를 들어, 금융 산업은 유효성에 더 높은 가치를 부여하는 반면 제약 산업은 정확성을 우선시합니다.
Mikkel Dengse는 데이터 품질을 측정하는 것 이상으로 생산성 및 참여 메트릭을 조합에 추가할 것을 권장합니다.
생산성은 데이터 관리에 소요되는 시간의 효율성을 측정하는 반면 참여는 최종 사용자가 필요할 때마다 데이터 보고서를 사용할 수 있도록 합니다.
데이터 품질을 개선하는 방법
첫째, 데이터를 다루는 모든 사람은 데이터 품질에 대한 전적인 책임을 져야 합니다. 여기에는 데이터 작성자(데이터를 생성하는 사람)와 데이터 사용자(데이터를 사용하는 사람)가 포함됩니다.
데이터 사용자는 데이터 작성자가 해당 요구 사항을 충족하는 데이터 제공에 집중할 수 있도록 필요한 데이터 유형을 명확하게 전달해야 합니다.
이것이 명확해지면 데이터 품질을 개선할 수 있습니다.
하지만 어디서부터 시작합니까?
데이터 품질을 향상시키려면 루트에서 시작하여 고품질 데이터만 데이터베이스에 입력하도록 허용해야 합니다. 이렇게 하면 데이터 품질을 확인해야 하는 필요성이 줄어들지는 않습니다.
그러나 이것은 질문을 던집니다. 이미 가지고 있는 데이터는 어떻습니까? 어떻게 청소합니까?
다음은 현재 데이터의 품질 문제를 수정하기 위한 4가지 데이터 개선 프로세스입니다.
데이터 프로파일링
데이터 프로파일링은 데이터 품질을 개선하기 위한 첫 번째 단계입니다. 오류, 누락된 정보 또는 중복 문제를 해결하기 위해 데이터를 검토하고 검사하는 프로세스입니다.
수동으로 수행할 경우 프로세스에 시간과 비용이 많이 소요될 수 있으며 인적 오류가 발생하기 쉽습니다. 그러나 데이터 통합 도구는 프로세스의 속도를 높이고 정확성을 향상시킬 수 있습니다.
데이터 거버넌스
조직의 사람들은 회사 데이터를 처리할 때마다 특정 역할을 할당받아야 합니다.
이것이 데이터 거버넌스의 역할입니다. 즉 누가 데이터에 액세스할 수 있는지, 어떤 조치를 취할 수 있으며, 어떤 방법을 사용할 수 있는지에 대한 규칙이 명확하도록 데이터를 구성하고 관리하는 프로세스입니다. 이는 사람들이 작업을 수행할 수 있는 충분한 액세스 권한을 부여하면서 인적 오류를 최소화합니다.
데이터 정리
더 이상 비즈니스 목표에 부합하지 않는 데이터는 데이터 정리를 통해 제거해야 합니다. 그렇지 않으면 데이터가 오염됩니다. 이 프로세스는 중복되고 부정확하며 불완전한 데이터를 제거합니다.
데이터 표준화
데이터는 다양한 소스에서 가져올 수 있습니다. 예를 들어 마케팅 및 영업 팀의 경우 이메일 소프트웨어, Google Analytics, CRM 도구 및 Facebook 및 Google Ads와 같은 광고 플랫폼에서 데이터를 얻을 수 있습니다.
데이터 표준화를 통해 이러한 다른 위치에서 수집된 모든 데이터를 정렬하고 데이터 불일치를 방지할 수 있습니다. 이를 통해 부서 간 협업과 통찰력 공유가 더 부드럽고 빨라집니다.
데이터를 표준화하는 쉬운 방법은 300개 이상의 마케팅 및 판매 소스에서 데이터를 추출하는 Improvado와 같은 자동화 도구를 사용하는 것입니다.

네 차례 야
우리는 데이터 중심의 세상에 살고 있습니다. 양질의 데이터를 보유하고 데이터로 무엇을 해야 하는지 알고 있는 기업은 많은 이점을 누릴 수 있습니다. 그들은 더 빠르게 확장하고 모든 경쟁자들을 뒤처지게 할 수 있습니다.
여전히 데이터 품질 관리가 이루어지지 않는다면 지금이 데이터 품질에 투자할 최적기입니다.