
Zaawansowane techniki zwiększania przepustowości LLM
Opublikowany: 2024-04-02W dynamicznym świecie technologii modele wielkojęzykowe (LLM) stały się kluczowymi graczami w naszej interakcji z informacjami cyfrowymi. Te potężne narzędzia umożliwiają pisanie artykułów, odpowiadanie na pytania, a nawet prowadzenie rozmów, ale wiążą się z nimi pewne wyzwania. Ponieważ wymagamy więcej od tych modeli, napotykamy przeszkody, zwłaszcza jeśli chodzi o zwiększenie ich szybkości i wydajności. Na tym blogu chodzi o bezpośrednie pokonywanie tych przeszkód.
Zagłębiamy się w kilka inteligentnych strategii mających na celu zwiększenie szybkości działania tych modeli, bez utraty jakości ich wyników. Wyobraź sobie, że próbujesz poprawić prędkość samochodu wyścigowego, zapewniając jednocześnie bezbłędne pokonywanie ciasnych zakrętów — do tego właśnie dążymy w przypadku modeli o dużym języku. Przyjrzymy się metodom takim jak Continuous Batching, które pomagają w płynniejszym przetwarzaniu informacji, oraz innowacyjnym podejściu, takim jak Paged i Flash Attention, które sprawiają, że LLM są bardziej uważni i szybsi w swoim cyfrowym rozumowaniu.
Jeśli więc ciekawi Cię przesuwanie granic możliwości tych gigantów sztucznej inteligencji, jesteś we właściwym miejscu. Przeanalizujmy wspólnie, jak te zaawansowane techniki kształtują przyszłość LLM, czyniąc je szybszymi i lepszymi niż kiedykolwiek wcześniej.
Wyzwania związane z osiągnięciem wyższej przepustowości w przypadku LLM
Osiągnięcie wyższej przepustowości w modelach wielkojęzycznych (LLM) wiąże się z kilkoma znaczącymi wyzwaniami, z których każde stanowi przeszkodę dla szybkości i wydajności, z jaką te modele mogą działać. Główną przeszkodą jest samo zapotrzebowanie na pamięć niezbędną do przetwarzania i przechowywania ogromnych ilości danych, z którymi współpracują te modele. W miarę wzrostu złożoności i rozmiaru LLM wzrasta zapotrzebowanie na zasoby obliczeniowe, co utrudnia utrzymanie, a co dopiero zwiększanie prędkości przetwarzania.
Kolejnym poważnym wyzwaniem jest autoregresyjny charakter LLM, zwłaszcza w modelach używanych do generowania tekstu. Oznacza to, że dane wyjściowe na każdym etapie zależą od poprzednich, co stwarza wymóg przetwarzania sekwencyjnego, który z natury ogranicza szybkość wykonywania zadań. Ta sekwencyjna zależność często skutkuje wąskim gardłem, ponieważ każdy krok musi poczekać na zakończenie swojego poprzednika, zanim będzie mógł kontynuować, co utrudnia wysiłki mające na celu osiągnięcie wyższej przepustowości.
Ponadto równowaga pomiędzy dokładnością i szybkością jest delikatna. Zwiększanie przepustowości bez pogarszania jakości wyników to wspinaczka po linie wymagająca innowacyjnych rozwiązań, które pozwolą poruszać się po złożonym krajobrazie wydajności obliczeniowej i efektywności modeli.
Wyzwania te stanowią tło, na którym dokonuje się postępów w optymalizacji LLM, przesuwając granice tego, co jest możliwe w dziedzinie przetwarzania języka naturalnego i poza nią.
Wymagania dotyczące pamięci
Faza dekodowania generuje pojedynczy token w każdym kroku czasowym, ale każdy token zależy od tensorów klucza i wartości wszystkich poprzednich tokenów (w tym tensorów KV tokenów wejściowych obliczonych podczas wstępnego napełniania i wszelkich nowych tensorów KV obliczonych do bieżącego kroku czasowego). .
Dlatego też, aby zminimalizować za każdym razem zbędne obliczenia i uniknąć ponownego obliczania tych wszystkich tensorów dla wszystkich tokenów w każdym kroku czasowym, możliwe jest buforowanie ich w pamięci GPU. W każdej iteracji, gdy obliczane są nowe elementy, są one po prostu dodawane do działającej pamięci podręcznej w celu wykorzystania w następnej iteracji. Jest to zasadniczo znane jako pamięć podręczna KV.
To znacznie zmniejsza liczbę potrzebnych obliczeń, ale wprowadza wymagania dotyczące pamięci wraz z już wyższymi wymaganiami dotyczącymi pamięci w przypadku modeli z dużymi językami, co utrudnia działanie na standardowych procesorach graficznych. Wraz ze wzrostem rozmiaru parametrów modelu (7B do 33B) i większą precyzją (fp16 do fp32) wzrastają również wymagania dotyczące pamięci. Zobaczmy przykład wymaganej pojemności pamięci,
Jak wiemy, dwoma głównymi użytkownikami pamięci są
- Własne ciężary modelu w pamięci, w tym przypadku nie. parametrów takich jak 7B i typ danych każdego parametru, np. 7B w fp16 (2 bajty) ~= 14 GB w pamięci
- Pamięć podręczna KV: pamięć podręczna używana dla wartości klucza etapu samouwagi, aby uniknąć zbędnych obliczeń.
Rozmiar pamięci podręcznej KV na token w bajtach = 2 * (liczba_warstw) * (rozmiar_ukryty) * precyzja_w_bajtach
Pierwszy współczynnik 2 odpowiada macierzom K i V. Te ukryte_rozmiar i dim_head można uzyskać z karty modelu lub pliku konfiguracyjnego.
Powyższa formuła dotyczy tokena, więc dla sekwencji wejściowej będzie to seq_len * size_of_kv_per_token. Zatem powyższa formuła zostanie przekształcona w:
Całkowity rozmiar pamięci podręcznej KV w bajtach = (długość_sekwencji) * 2 * (liczba_warstw) * (rozmiar_ukryty) * precyzja_w_bajtach
Na przykład w przypadku LLAMA 2 w FP16 rozmiar będzie wynosić (4096) * 2 * (32) * (4096) * 2, czyli ~ 2 GB.
Powyższe dotyczy pojedynczego wejścia, w przypadku wielu wejść liczba ta szybko rośnie, alokacja pamięci i zarządzanie nią w trakcie działania staje się zatem kluczowym krokiem w celu osiągnięcia optymalnej wydajności, jeśli nie skutkuje brakiem pamięci i problemami z fragmentacją.
Czasami zapotrzebowanie na pamięć jest większe niż pojemność naszego procesora graficznego. W takich przypadkach musimy przyjrzeć się równoległości modelu, równoległości tensorów, które nie są tutaj omówione, ale można zbadać w tym kierunku.
Autoregresja i operacja związana z pamięcią
Jak widać, część generująca dane wyjściowe w dużych modelach językowych ma charakter autoregresyjny. Wskazuje, że nowy token ma zostać wygenerowany, zależy to od wszystkich poprzednich tokenów i ich stanów pośrednich. Ponieważ na etapie wyjściowym nie wszystkie tokeny są dostępne do dalszych obliczeń i ma tylko jeden wektor (dla następnego tokena) i blok z poprzedniego etapu, przypomina to operację macierz-wektor, która w niewystarczającym stopniu wykorzystuje możliwości obliczeniowe GPU, gdy w porównaniu do fazy wstępnej. Szybkość, z jaką dane (wagi, klucze, wartości, aktywacje) są przesyłane do procesora graficznego z pamięci, dominuje nad opóźnieniem, a nie nad szybkością faktycznie przeprowadzanych obliczeń. Innymi słowy, jest to operacja związana z pamięcią .
Innowacyjne rozwiązania pozwalające pokonać wyzwania związane z przepustowością
Ciągłe dozowanie
Bardzo prostym krokiem, aby zmniejszyć charakter etapu dekodowania związany z pamięcią, jest wsadowe podzielenie danych wejściowych i wykonanie obliczeń dla wielu wejść jednocześnie. Jednak proste, ciągłe grupowanie wsadowe spowodowało słabą wydajność ze względu na naturę generowanych sekwencji o różnej długości, a w tym przypadku opóźnienie partii zależy od najdłuższej sekwencji generowanej wsadowo, a także od rosnącego zapotrzebowania na pamięć, ponieważ używanych jest wiele wejść teraz przetwarzane na raz.
Dlatego proste dozowanie statyczne jest nieskuteczne i następuje dozowanie ciągłe. Jego istota polega na dynamicznym agregowaniu przychodzących partii żądań, dostosowywaniu się do wahań częstotliwości nadejścia i wykorzystywaniu możliwości przetwarzania równoległego, gdy jest to możliwe. Optymalizuje to również wykorzystanie pamięci poprzez grupowanie sekwencji o podobnej długości w każdej partii, co minimalizuje ilość dopełnienia potrzebnego w przypadku krótszych sekwencji i pozwala uniknąć marnowania zasobów obliczeniowych na nadmierne dopełnianie.

Adaptacyjnie dostosowuje rozmiar partii w oparciu o takie czynniki, jak bieżąca pojemność pamięci, zasoby obliczeniowe i długość sekwencji wejściowych. Zapewnia to optymalne działanie modelu w różnych warunkach, bez przekraczania ograniczeń pamięci. Pomaga to w skupieniu uwagi (wyjaśnione poniżej) pomaga w zmniejszeniu opóźnień i zwiększeniu przepustowości.
Czytaj dalej: Jak ciągłe przetwarzanie wsadowe umożliwia 23-krotną przepustowość w wnioskowaniu LLM, jednocześnie zmniejszając opóźnienie p50
Uwaga stronicowana
Ponieważ przeprowadzamy przetwarzanie wsadowe w celu poprawy przepustowości, odbywa się to również kosztem zwiększonego zapotrzebowania na pamięć podręczną KV, ponieważ przetwarzamy teraz wiele danych wejściowych jednocześnie. Sekwencje te mogą przekraczać pojemność pamięci dostępnych zasobów obliczeniowych, przez co przetwarzanie ich w całości staje się niepraktyczne.
Zaobserwowano również, że naiwna alokacja pamięci podręcznej KV powoduje dużą fragmentację pamięci, podobnie jak to obserwujemy w systemach komputerowych z powodu nierównej alokacji pamięci. Firma vLLM wprowadziła Paged Attention, technikę zarządzania pamięcią zainspirowaną koncepcjami systemu operacyjnego dotyczącą stronicowania i pamięci wirtualnej, aby skutecznie obsługiwać rosnące wymagania dotyczące pamięci podręcznej KV.
Paged Attention rozwiązuje problemy pamięci, dzieląc mechanizm uwagi na mniejsze strony lub segmenty, z których każdy obejmuje podzbiór sekwencji wejściowej. Zamiast obliczać jednocześnie wyniki uwagi dla całej sekwencji wejściowej, model skupia się na jednej stronie na raz i przetwarza ją sekwencyjnie.
Podczas wnioskowania lub uczenia model iteruje po każdej stronie sekwencji wejściowej, obliczając wyniki uwagi i odpowiednio generując dane wyjściowe. Po przetworzeniu strony wyniki są zapisywane, a model przechodzi do następnej strony.
Dzieląc mechanizm uwagi na strony, Paged Attention umożliwia modelowi dużego języka obsługę sekwencji wejściowych o dowolnej długości bez przekraczania ograniczeń pamięci. Skutecznie zmniejsza zużycie pamięci wymaganej do przetwarzania długich sekwencji, umożliwiając pracę z dużymi dokumentami i partiami.
Czytaj dalej: Szybkie udostępnianie LLM za pomocą vLLM i PagedAttention
Błyskawiczna uwaga
Ponieważ mechanizm uwagi ma kluczowe znaczenie w przypadku modeli transformatorów, na których opierają się duże modele językowe, pomaga on modelowi skupić się na odpowiednich częściach tekstu wejściowego podczas dokonywania prognoz. Jednakże w miarę jak modele oparte na transformatorach stają się większe i bardziej złożone, mechanizm samouwagi staje się coraz bardziej powolny i wymaga dużej ilości pamięci, co prowadzi do problemu wąskiego gardła pamięci, jak wspomniano wcześniej. Flash Attention to kolejna technika optymalizacji, która ma na celu złagodzenie tego problemu poprzez optymalizację operacji uwagi, umożliwiając szybsze uczenie i wnioskowanie.
Kluczowe cechy Flash Uwaga:
Kernel Fusion: ważne jest, aby nie tylko zmaksymalizować wykorzystanie mocy obliczeniowej procesora graficznego, ale także sprawić, aby działało tak wydajnie, jak to możliwe. Flash Attention łączy wiele etapów obliczeń w jedną operację, redukując potrzebę powtarzalnych transferów danych. To uproszczone podejście upraszcza proces wdrażania i zwiększa wydajność obliczeniową.
Kafelkowanie: Flash Attention dzieli załadowane dane na mniejsze bloki, ułatwiając przetwarzanie równoległe. Strategia ta optymalizuje wykorzystanie pamięci, umożliwiając skalowalne rozwiązania dla modeli o większych rozmiarach wejściowych.
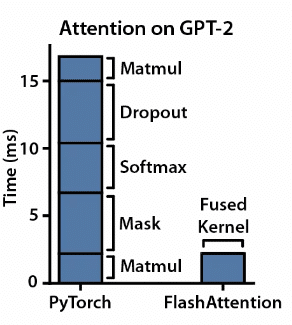
(Skonsolidowane jądro CUDA przedstawiające, jak kafelkowanie i fuzja skracają czas wymagany do obliczeń, źródło obrazu: FlashAttention: Szybka i oszczędzająca pamięć funkcja Exact Attention z funkcją IO-Awareness)
Optymalizacja pamięci: Flash Attention ładuje parametry tylko dla kilku ostatnich tokenów, ponownie wykorzystując aktywacje z ostatnio obliczonych tokenów. Takie podejście do przesuwanego okna zmniejsza liczbę żądań I/O w celu załadowania wag i maksymalizuje przepustowość pamięci flash.
Ograniczone przesyłanie danych: Funkcja Flash Attention minimalizuje przesyłanie danych tam i z powrotem między typami pamięci, takimi jak pamięć o dużej przepustowości (HBM) i SRAM (statyczna pamięć o dostępie swobodnym). Ładując wszystkie dane (zapytania, klucze i wartości) tylko raz, zmniejsza się obciążenie związane z powtarzalnymi transferami danych.
Studium przypadku – optymalizacja wnioskowania za pomocą dekodowania spekulatywnego
Inną metodą zastosowaną do przyspieszenia generowania tekstu w modelu języka autoregresyjnego jest dekodowanie spekulatywne. Głównym celem dekodowania spekulatywnego jest przyspieszenie generowania tekstu przy jednoczesnym zachowaniu jakości wygenerowanego tekstu na poziomie porównywalnym z dystrybucją docelową.
Dekodowanie spekulatywne wprowadza model mały/roboczy, który przewiduje kolejne tokeny w sekwencji, które następnie są akceptowane/odrzucane przez model główny na podstawie wcześniej zdefiniowanych kryteriów. Integracja mniejszego modelu roboczego z modelem docelowym znacznie zwiększa szybkość generowania tekstu, wynika to z charakteru zapotrzebowania na pamięć. Ponieważ projekt modelu jest mały, wymaga mniej nie. masy neuronów do załadowania i nie. obliczeń jest teraz również mniejsza w porównaniu z modelem głównym, co zmniejsza opóźnienia i przyspiesza proces generowania wyników. Następnie model główny ocenia wygenerowane wyniki i sprawdza, czy mieszczą się one w docelowym rozkładzie następnego prawdopodobnego tokena.
Zasadniczo dekodowanie spekulatywne usprawnia proces generowania tekstu, wykorzystując mniejszy, szybszy model roboczy do przewidywania kolejnych tokenów, przyspieszając w ten sposób ogólną prędkość generowania tekstu przy jednoczesnym zachowaniu jakości wygenerowanej treści zbliżonej do dystrybucji docelowej.
Bardzo ważne jest, aby tokeny generowane przez mniejsze modele nie zawsze były stale odrzucane, w tym przypadku prowadzi to do spadku wydajności zamiast poprawy. Poprzez eksperymenty i charakter przypadków użycia możemy wybrać mniejszy model/wprowadzić dekodowanie spekulatywne do procesu wnioskowania.
Wniosek
Podróż przez zaawansowane techniki zwiększania przepustowości modelu dużego języka (LLM) wyznacza drogę naprzód w dziedzinie przetwarzania języka naturalnego, pokazując nie tylko wyzwania, ale także innowacyjne rozwiązania, które mogą im sprostać. Techniki te, od ciągłego przetwarzania wsadowego po Paged i Flash Attention oraz intrygujące podejście do dekodowania spekulatywnego, to coś więcej niż tylko stopniowe ulepszenia. Stanowią one znaczący postęp w naszej zdolności do szybszego, wydajniejszego i ostatecznie bardziej dostępnego dla szerokiego zakresu zastosowań dużych modeli językowych.
Znaczenia tych osiągnięć nie można przecenić. Optymalizując przepustowość LLM i poprawiając wydajność, nie tylko ulepszamy silniki tych potężnych modeli; na nowo definiujemy możliwości pod względem szybkości i wydajności przetwarzania. To z kolei otwiera nowe horyzonty dla zastosowania dużego modelu językowego, od usług tłumaczeń językowych w czasie rzeczywistym, które mogą działać z prędkością konwersacji, po zaawansowane narzędzia analityczne zdolne do przetwarzania ogromnych zbiorów danych z niespotykaną dotąd szybkością.
Co więcej, techniki te podkreślają znaczenie zrównoważonego podejścia do optymalizacji dużych modeli językowych – takiego, które dokładnie uwzględnia wzajemne oddziaływanie między szybkością, dokładnością i zasobami obliczeniowymi. W miarę przesuwania granic możliwości LLM utrzymanie tej równowagi będzie miało kluczowe znaczenie dla zapewnienia, że modele te będą mogły w dalszym ciągu służyć jako wszechstronne i niezawodne narzędzia w niezliczonej liczbie branż.
Zaawansowane techniki zwiększania przepustowości dużych modeli językowych to coś więcej niż tylko osiągnięcia techniczne; są kamieniami milowymi w ciągłej ewolucji sztucznej inteligencji. Obiecują, że LLM będą bardziej elastyczne, wydajniejsze i potężniejsze, torując drogę przyszłym innowacjom, które będą w dalszym ciągu przekształcać nasz cyfrowy krajobraz.
Przeczytaj więcej o architekturze GPU dla optymalizacji wnioskowania modelu dużego języka w naszym ostatnim poście na blogu