
Jak zaprojektować skuteczny proces analizy danych B2C
Opublikowany: 2022-10-28Wydajny proces analizy danych umożliwia zespołom marketingowym prawidłowy pomiar wyników, zarówno obecnych, jak i historycznych, a także dokonywanie wiarygodnych prognoz i odpowiednią optymalizację strategii.
Był to kluczowy czynnik sukcesu czołowych marek B2C, takich jak Amazon, Netflix i Walmart. W miarę jak konsumenci wciąż poszukują cyfrowych możliwości zaspokojenia swoich codziennych potrzeb, dyrektorzy marketingu B2C we wszystkich branżach dostrzegają znaczenie analizy danych w dostarczaniu klientom wysokiej jakości doświadczeń i zwiększaniu zwrotu z inwestycji.
W tym przewodniku omówimy znaczenie posiadania konfiguracji analizy danych, a także przeprowadzimy Cię przez proces projektowania i wdrażania jej w Twojej firmie.
Wzrost złożoności podróży klientów
Potrzeba kompleksowej konfiguracji analizy danych wynika ze stale rosnącej złożoności podróży klienta i oczekiwań klientów dotyczących spersonalizowanego doświadczenia.
W rzeczywistości 71% klientów postrzega spersonalizowane interakcje jako standard, a 76% jest sfrustrowanych, gdy ich nie otrzymuje. Marki, które nie poddają się personalizacji, ryzykują utratę 38% swoich klientów, wynika z badania przeprowadzonego przez Gartnera. Rozbijmy to dalej.

W Stanach Zjednoczonych i wielu częściach Europy przeciętne gospodarstwo domowe ma dostęp do co najmniej 7 podłączonych urządzeń, z których wiele można wykorzystać do interakcji z markami między innymi za pośrednictwem wyszukiwania, poczty e-mail i mediów społecznościowych. Chociaż daje to firmom B2C możliwości dotarcia do większej liczby klientów, sprawia, że marketing i sprzedaż są bardziej czasochłonne i wymagające.
Od etapu odkrycia do konwersji klient przechodzi długą drogę, zwykle średnio z ośmiu punktów kontaktu. Wyobraź sobie, 92% klientów odwiedza sklepy internetowe bez początkowego zamiaru dokonania zakupu. W rzeczywistości 25% tych klientów odwiedza je, aby porównać ceny i funkcje konkurencji, a 45% odwiedza je, aby dowiedzieć się więcej o określonych produktach i usługach. Działania marketingowe są kontynuowane nawet poza sklepem internetowym – w mediach społecznościowych, porównywarkach, wyszukiwarkach i innych platformach. Nawet po dokonaniu zakupu podróż klienta trwa, a osoby te pragną spersonalizowanych rekomendacji i ofert.
To powiedziawszy, marketing skierowany do klientów w wielu punktach styku zajmuje i generuje ogromne ilości danych. Dane te zawierają informacje o zachowaniach konsumentów na różnych etapach ścieżki konwersji, ich unikalnych potrzebach oraz sposobach tworzenia spersonalizowanych ofert, które najprawdopodobniej będą im odpowiadać.
Obsługa dużych ilości danych z wielu źródeł może być czasochłonna, kosztowna i podatna na błędy. Firmy często kończą z danymi wyciszonymi i niskiej jakości, co obniża jakość doświadczeń, które dostarczają swoim klientom. To z kolei prowadzi do utraty około 4,7 biliona dolarów w globalnej sprzedaży konsumenckiej.
Aby przerwać ten cykl, firmy muszą wykorzystać nowoczesną technologię i praktyki zarządzania danymi.
Operacje oparte na danych: dostępność danych i czyste dane
W seminarium internetowym przeprowadzonym przez InfoTrust i Forrester starszy analityk Richard Joyce powiedział: „tylko 10% wzrost dostępności danych przyniesie ponad 65 mln USD dodatkowego dochodu netto dla typowej firmy z listy Fortune 1000”.
Dostępność danych polega na udostępnianiu danych do użytku w organizacji. Oznacza to, że osoby z różnych działów i z różnym doświadczeniem w przetwarzaniu danych wiedzą, gdzie i jak mogą uzyskać dostęp do danych lub zażądać ich i uzyskać je w stanie nadającym się do użytku.
Dostępność do czyszczenia danych jest jednym z podstawowych aspektów firmy B2C opartej na danych. Umożliwia działom mającym kontakt z klientami dostęp do informacji o krytycznym znaczeniu, co prowadzi do wyższych konwersji i wzrostu zysku netto, jak wspomniano powyżej. Wiele korzyści z dostępności danych obejmuje również następujące elementy.
Ulepszone podejmowanie decyzji
Gdy dane są dostępne i przydatne dla kadry kierowniczej z różnych działów, każdemu liderowi łatwiej jest zrozumieć ogólną wydajność biznesową firmy i sposób, w jaki działania jego zespołu przyczyniają się do osiągnięcia celu końcowego.
Informacje te są kluczowe, aby pomóc im w podejmowaniu decyzji i wdrażaniu strategii, które przynoszą pozytywne rezultaty, jednocześnie przybliżając firmę do jej celów. Należy podkreślić, że nigdy nie należy ignorować jakości danych wykorzystywanych przy podejmowaniu decyzji.
Według Gartnera firmy tracą średnio 15 milionów dolarów rocznie z powodu decyzji opartych na danych o niskiej jakości.
Dowiedz się, jak mierzyć i poprawiać jakość danych
Ulepszona jakość danych
Silosy są głównym winowajcą niskiej jakości danych w firmach. Gdy dane są wyciszone w różnych działach, na pewno pojawią się duplikaty i niespójności, przez co trudno jest zbudować całościowy obraz klientów, partnerów i produktów firmy. Według MIT dane niskiej jakości mogą sprawić, że firma straci od 15% do 25% swoich przychodów.
Jednak gdy dane stają się dostępne, sytuacja się odwraca. Zespoły otrzymują bardziej aktualne dane, duplikaty i niespójne informacje są eliminowane, generowane są lepsze wglądy, a firma osiąga większe zyski.
Bardziej efektywna alokacja budżetu
Mając dostęp do odpowiednio zorganizowanych danych, możliwe staje się zidentyfikowanie kanałów i strategii, które przynoszą najlepsze rezultaty. Wiedza o tym pozwoli Ci uzasadnić każdy wydatek i przeznaczyć większy budżet na obszary o wysokiej wydajności.
Lepsze wrażenia klientów
Zapylenie krzyżowe danych konsumenckich między zespołami mającymi kontakt z klientami umożliwia różnym działom uzyskanie głębszego wglądu w zachowanie klientów i ich unikalne potrzeby na każdym etapie ich podróży. Ma to kluczowe znaczenie w generowaniu treści wspierających sprzedaż, tworzeniu spersonalizowanych ofert i nawiązywaniu lepszych relacji z klientami.

Projektowanie procesu analizy danych dla firm B2C
Analiza danych obejmuje sześć głównych faz, powszechnie określanych jako cykl życia analizy danych.
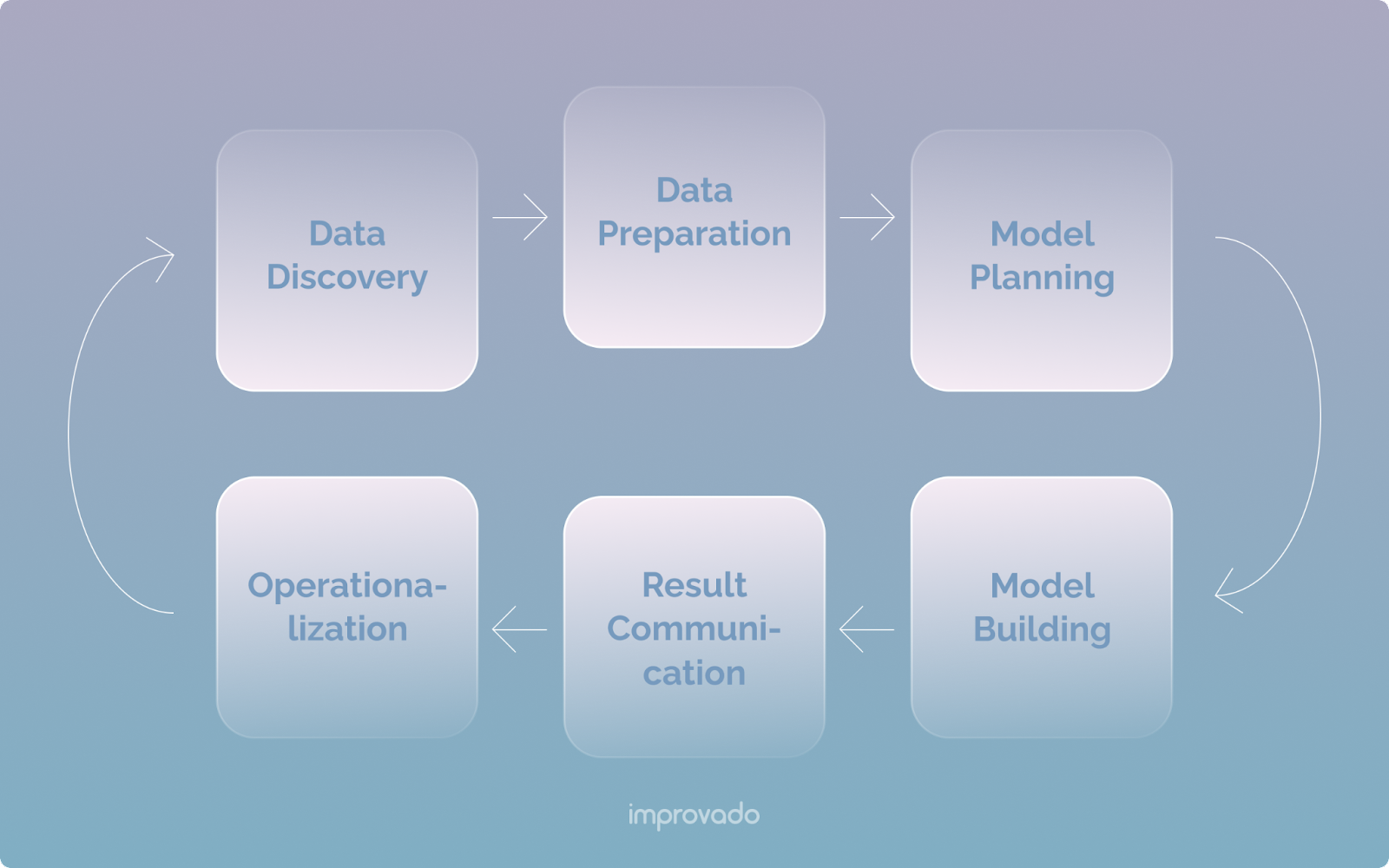
W tej sekcji omówimy, jak zbudować proces analizy B2C przy użyciu różnych faz cyklu życia analizy danych.
Odkrycie i przygotowanie
Etap odkrywania koncentruje się bardziej na potrzebach biznesowych niż na samych danych. Tutaj musisz wyznaczyć jasne cele dla swojego zespołu i opracować strategię, jak to osiągnąć. Będziesz musiał zbadać trendy w swojej branży i dokonać oceny dostępnych zasobów i wymagań technologicznych.
Następnie określisz, jakie są źródła danych Twojej firmy i jaką historię chcesz przekazać swoim danym. Te dane zwykle przechodzą przez test hipotezy, w którym rozwiązujesz swoje potrzeby biznesowe w oparciu o aktualne scenariusze rynkowe.
Po etapie odkrycia następuje etap przygotowań. Tutaj nacisk przenosi się z celów biznesowych na wymagania dotyczące danych. Przygotowanie danych obejmuje przechwytywanie, przetwarzanie i czyszczenie danych biznesowych przychodzących ze źródeł wewnętrznych i zewnętrznych. Zebrane dane mogą być ustrukturyzowane (mające zdefiniowane wzorce), częściowo ustrukturyzowane lub nieustrukturyzowane.
Jako marka B2C Twoje źródła danych mogą obejmować Amazon Advertising, Facebook Ads i Shopify.
Planowanie i budowa modeli
Teraz, gdy już przechwyciłeś potrzebne dane, następnym krokiem będzie załadowanie i przekształcenie danych. Na tym polega faza planowania modelu.
Istnieje kilka technik, których możesz użyć do załadowania danych do piaskownicy analitycznej. Dwa główne typy to:
- Wyodrębnij, przekształć i załaduj (ETL): Ta procedura wyodrębnia i przekształca dane przy użyciu predefiniowanych reguł biznesowych przed załadowaniem ich do obszaru izolowanego.
- Extract, Load and Transform (ELT): Tutaj ładujesz surowe dane do piaskownicy, a następnie przekształcasz dane.
Przeczytaj nasz przewodnik dla początkujących po procesach ETL
Brudne dane mogą być filtrowane lub całkowicie usuwane w tej fazie. Inne techniki, które możesz zastosować, obejmują agregację danych, integrację i czyszczenie.
Faza budowania obejmuje tworzenie zestawów danych do celów szkoleniowych i produkcyjnych. Tutaj będziesz polegać na technikach, takich jak drzewa decyzyjne, regresje logistyczne i sieci neuronowe. Ten etap obejmuje również wykonanie zaprojektowanego modelu, a charakter środowiska wykonawczego jest zdefiniowany i przygotowany, aby łatwiej było go rozbudować, jeśli wymagane jest bardziej niezawodne środowisko.
Wyniki komunikacji
Ten etap obejmuje udostępnienie wyników realizacji modelu interesariuszom w firmie. Interesariusze przeanalizują Twój raport, aby ustalić, czy spełnia on kryteria biznesowe określone w fazie odkrywania. Obejmuje to identyfikację krytycznych wniosków z analizy, pomiar celów biznesowych związanych z wynikami oraz wygenerowanie przystępnego podsumowania dla interesariuszy firmy.
Operacjonalizacja
Ten etap obejmuje przeniesienie danych z piaskownicy i wdrożenie modelu w rzeczywistym środowisku. Dane są stale monitorowane i analizowane, aby wygenerowane modele zwracały oczekiwane wyniki. Zawsze możesz wrócić, aby wprowadzić poprawki, jeśli wyniki nie są zgodne z oczekiwaniami.
Automatyzacja analizy danych z Impprovado
Ręczne tworzenie potoków danych i zarządzanie nimi może być procesem czasochłonnym, zasobożernym i podatnym na błędy, szczególnie w przypadku firm na poziomie przedsiębiorstwa z petabajtami danych.
Średnio inżynierowie danych w firmach klasy korporacyjnej spędzają 40% swojego dnia pracy na naprawie błędnych danych i uszkodzonych potoków danych.
Podatny na błędy charakter ręcznego ETL pogarsza powolne tempo, w jakim inżynierowie danych wykrywają incydenty w potoku. Według Wakefielda inżynierowie potrzebują średnio czterech godzin na wykrycie błędów i około dziewięciu godzin na ich naprawienie.
Prowadzi to do częstego występowania złych danych, co z kolei wpływa na 26% przychodów tych firm. Aby ograniczyć zagrożenie złych danych, firmy muszą wykorzystywać zautomatyzowane platformy ETL, takie jak Impprovado.
Impprovado to platforma danych o przychodach, która automatyzuje analizy i raportowanie marketingu wielokanałowego na dużą skalę. Platforma automatyzuje kluczowe obszary cyklu życia analizy danych Twojej firmy (agregacja, transformacja i czyszczenie), dostarczając czyste, gotowe do analizy dane do żądanej hurtowni, BI, analityki lub narzędzia do wizualizacji.
Pozwala to zaoszczędzić do 90% czasu raportowania, daje większą kontrolę nad danymi firmy i ostatecznie zwiększa zwrot z inwestycji.
Wyprzedzenie krzywej
Ponieważ krajobraz konsumencki staje się z dnia na dzień coraz bardziej złożony, organizacje oparte na danych nadal wyprzedzają konkurencję, wzmacniając swój stos analityczny dzięki zautomatyzowanym wielokanałowym platformom przychodów i pozostawiając w tyle ręczne ETL.
Dzięki temu mogą scentralizować istniejące dane, skalować z nowymi źródłami danych i skoncentrować się na odkrywaniu istotnych informacji zorientowanych na rozwój.
Jeśli chcesz dowiedzieć się więcej o tym, jak Impprovado może pomóc w ustanowieniu solidnego i skalowalnego procesu analizy danych dla Twojej firmy, skontaktuj się z nami. Chętnie pomożemy!