
Najlepsze praktyki i przypadki użycia zgarniania danych ze strony internetowej
Opublikowany: 2023-12-28Podczas pobierania danych ze strony internetowej istotne jest przestrzeganie przepisów i ram witryny docelowej. Przestrzeganie najlepszych praktyk jest nie tylko kwestią etyki, ale także pozwala uniknąć komplikacji prawnych i gwarantuje niezawodność ekstrakcji danych. Oto najważniejsze kwestie:
- Przestrzegaj pliku robots.txt : zawsze najpierw sprawdź ten plik, aby dowiedzieć się, co właściciel witryny ustawił jako niedozwolone w przypadku skrobania.
- Korzystaj z interfejsów API : jeśli to możliwe, użyj oficjalnego interfejsu API witryny, który jest bardziej stabilną i zatwierdzoną metodą dostępu do danych.
- Pamiętaj o liczbie żądań : Nadmierne pobieranie danych może obciążać serwery witryn, dlatego należy zachować ostrożność podczas wysyłania żądań.
- Przedstaw się : za pomocą swojego podpisu agenta użytkownika podawaj przejrzyście swoją tożsamość i cel podczas skrobania.
- Obchodź się z danymi odpowiedzialnie : przechowuj i wykorzystuj zebrane dane zgodnie z przepisami dotyczącymi prywatności i przepisami o ochronie danych.
Przestrzeganie tych praktyk zapewnia skromność etyczną, utrzymanie integralności i dostępności treści online.
Zrozumienie ram prawnych
Podczas pobierania danych ze strony internetowej ważne jest, aby poruszać się po powiązanych ze sobą ograniczeniach prawnych. Kluczowe teksty legislacyjne obejmują:
- Ustawa o oszustwach i nadużyciach komputerowych (CFAA): ustawodawstwo w Stanach Zjednoczonych sprawia, że dostęp do komputera bez odpowiedniego upoważnienia jest nielegalny.
- Ogólne rozporządzenie o ochronie danych Unii Europejskiej (RODO) : wyraża zgodę na wykorzystanie danych osobowych i zapewnia osobom fizycznym kontrolę nad ich danymi.
- Ustawa Digital Millennium Copyright Act (DMCA) : chroni przed rozpowszechnianiem treści chronionych prawem autorskim bez pozwolenia.
Scrapery muszą także przestrzegać „warunków użytkowania” witryn internetowych, które często ograniczają pobieranie danych. Zapewnienie zgodności z tymi przepisami i zasadami jest niezbędne do etycznego i prawnego usunięcia danych ze stron internetowych.
Wybór odpowiednich narzędzi do skrobania
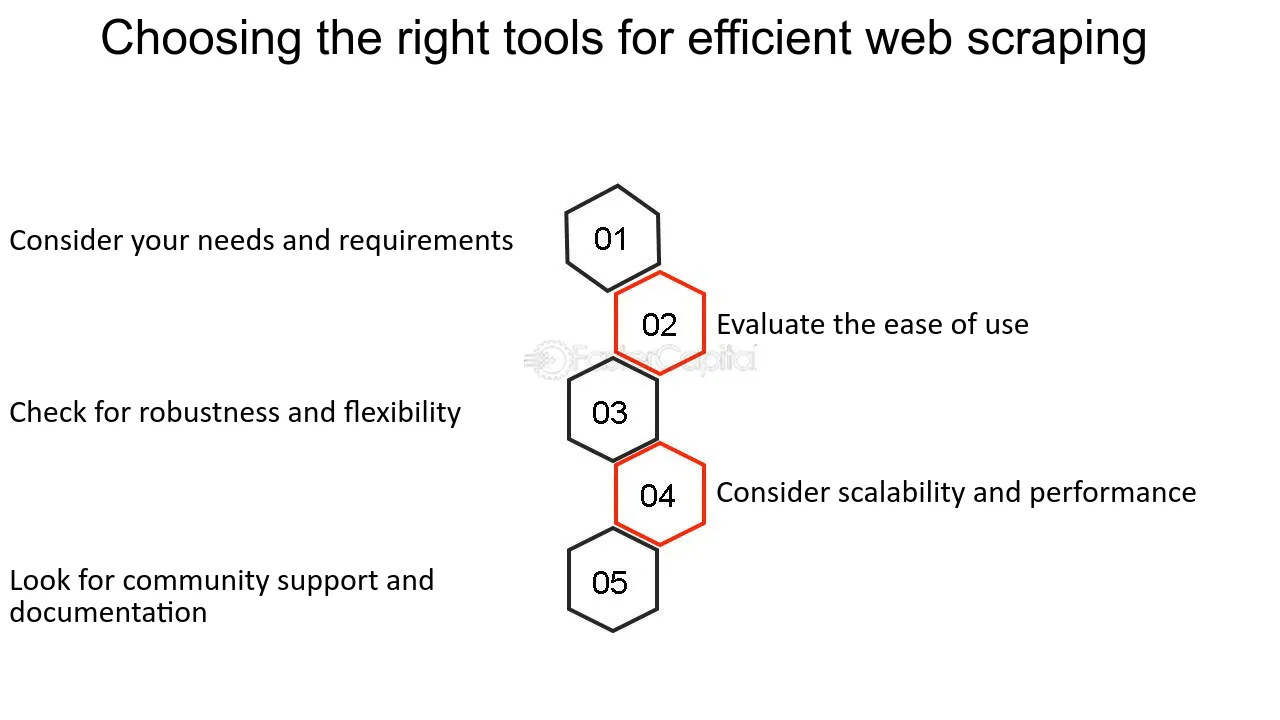
Wybór odpowiednich narzędzi ma kluczowe znaczenie przy rozpoczynaniu projektu skrobania stron internetowych. Czynniki, które należy wziąć pod uwagę, obejmują:
- Złożoność witryny : witryny dynamiczne mogą wymagać narzędzi takich jak Selenium, które mogą wchodzić w interakcję z JavaScript.
- Ilość danych : W przypadku skrobania na dużą skalę zalecane są narzędzia z rozproszonymi możliwościami skrobania, takie jak Scrapy.
- Legalność i etyka : wybierz narzędzia z funkcjami zgodnymi z plikiem robots.txt i ustaw ciągi agenta użytkownika.
- Łatwość obsługi : Nowicjusze mogą preferować przyjazne dla użytkownika interfejsy dostępne w oprogramowaniu takim jak Octoparse.
- Znajomość programowania : Osoby niekodujące mogą skłaniać się ku oprogramowaniu z graficznym interfejsem użytkownika, podczas gdy programiści mogą zdecydować się na biblioteki takie jak BeautifulSoup.
Źródło obrazu: https://fastercapital.com/
Najlepsze praktyki skutecznego usuwania danych z witryny internetowej
Aby skutecznie i odpowiedzialnie usuwać dane ze strony internetowej, postępuj zgodnie z poniższymi wskazówkami:
- Przestrzegaj plików robots.txt i warunków korzystania z witryny, aby uniknąć problemów prawnych.
- Używaj nagłówków i zmieniaj programy użytkownika, aby naśladować ludzkie zachowanie.
- Zaimplementuj opóźnienie między żądaniami, aby zmniejszyć obciążenie serwera.
- Korzystaj z serwerów proxy, aby zapobiegać blokadom adresów IP.
- Scrape poza godzinami szczytu, aby zminimalizować zakłócenia w działaniu witryny.
- Zawsze przechowuj dane efektywnie, unikając duplikacji wpisów.
- Zapewniaj dokładność zeskrobanych danych poprzez regularne kontrole.
- Podczas przechowywania i wykorzystywania danych należy pamiętać o przepisach dotyczących ochrony danych.
- Aktualizuj swoje narzędzia do skrobania, aby móc obsługiwać zmiany w witrynie.
- Zawsze bądź przygotowany na dostosowanie strategii skrobania, jeśli strony internetowe zaktualizują swoją strukturę.
Przypadki użycia skrobania danych w różnych branżach
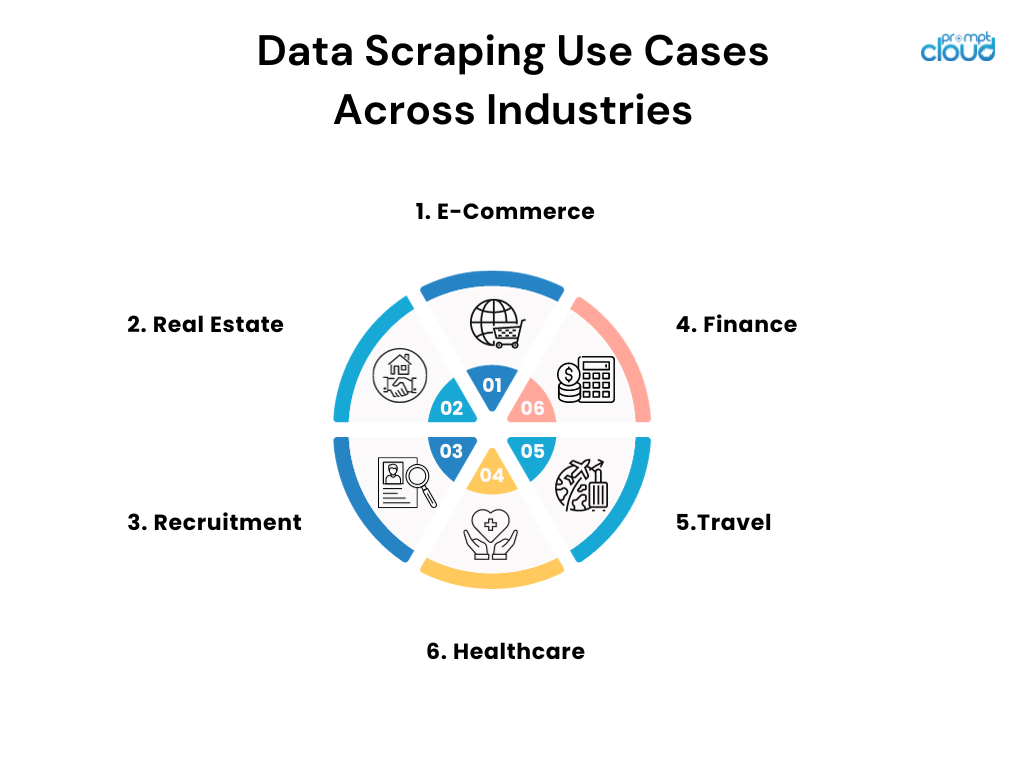
- Handel elektroniczny: Sprzedawcy internetowi stosują metodę skrobania, aby monitorować ceny konkurencji i odpowiednio dostosowywać swoje strategie cenowe.
- Nieruchomości: agenci i firmy przeglądają oferty w celu gromadzenia informacji o nieruchomościach, trendach i danych cenowych z różnych źródeł.
- Rekrutacja: Firmy przeglądają portale z ofertami pracy i media społecznościowe, aby znaleźć potencjalnych kandydatów i przeanalizować trendy na rynku pracy.
- Finanse: Analitycy przeglądają rejestry publiczne i dokumenty finansowe, aby opracować strategie inwestycyjne i śledzić nastroje rynkowe.
- Podróże: Agencje przeglądają ceny linii lotniczych i hoteli, aby zapewnić klientom najlepsze możliwe oferty i pakiety.
- Opieka zdrowotna: Naukowcy przeglądają medyczne bazy danych i czasopisma, aby być na bieżąco z najnowszymi odkryciami i badaniami klinicznymi.
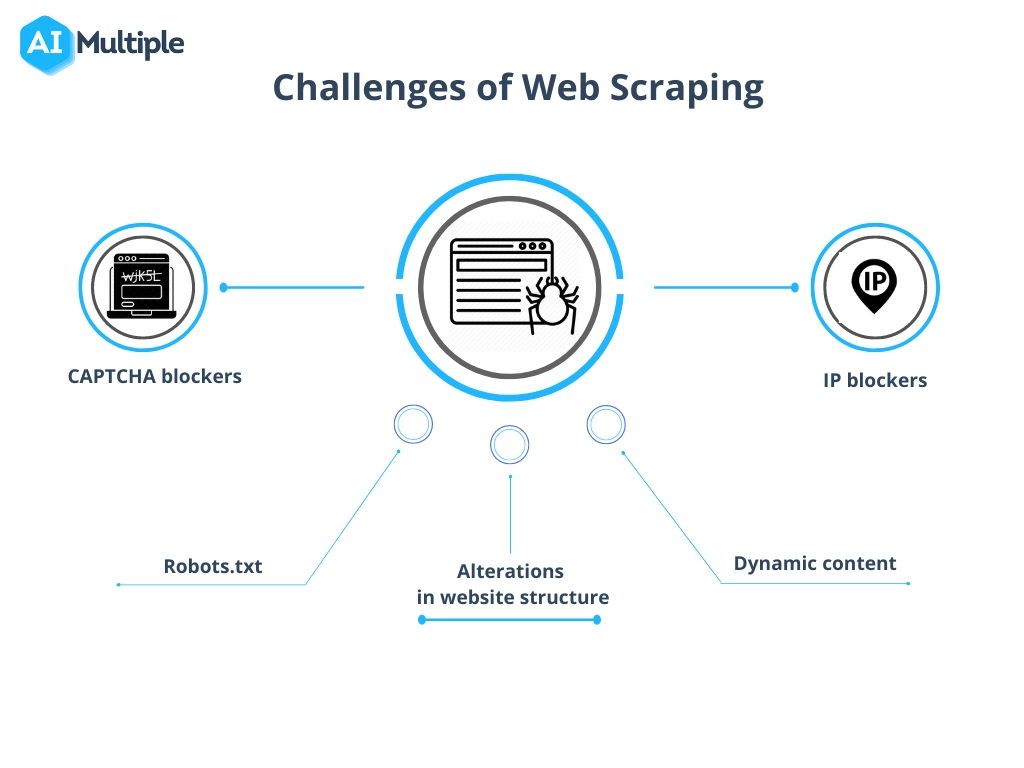
Rozwiązywanie typowych problemów związanych ze zbieraniem danych
Proces zgarniania danych ze strony internetowej, choć niezwykle cenny, często wiąże się z pokonywaniem przeszkód, takich jak zmiany w strukturze witryny, środki zapobiegające skrobaniu i obawy dotyczące jakości danych.

Źródło obrazu: https://research.aimultiple.com/
Aby efektywnie się nimi poruszać:
- Pozostań adaptacyjny : regularnie aktualizuj skrypty skrobania, aby dopasować je do aktualizacji witryny. Korzystanie z uczenia maszynowego może pomóc w dynamicznym dostosowywaniu się do zmian strukturalnych.
- Przestrzegaj granic prawnych : Zrozum i przestrzegaj legalności skrobania, aby uniknąć sporów sądowych. Pamiętaj, aby zapoznać się z plikiem robots.txt i warunkami korzystania z usługi w witrynie internetowej.
- Góra formy
- Naśladuj interakcję człowieka : strony internetowe mogą blokować skrobaki, które zbyt szybko wysyłają żądania. Wprowadź opóźnienia i losowe odstępy między żądaniami, aby wyglądały mniej robotycznie.
- Obsługa CAPTCHA : dostępne są narzędzia i usługi, które mogą rozwiązać lub ominąć CAPTCHA, chociaż ich użycie należy rozważyć pod kątem konsekwencji etycznych i prawnych.
- Zachowaj integralność danych : Zapewnij dokładność wyodrębnionych danych. Regularnie sprawdzaj poprawność danych i czyść je, aby zachować jakość i użyteczność.
Strategie te pomagają w pokonywaniu typowych przeszkód związanych ze skrobaniem i ułatwiają wyodrębnianie cennych danych.
Wniosek
Efektywne wydobywanie danych ze stron internetowych to cenna metoda o różnorodnych zastosowaniach, począwszy od badań rynku po analizę konkurencji. Niezbędne jest przestrzeganie najlepszych praktyk, zapewnienie zgodności z prawem, przestrzeganie wytycznych dotyczących pliku robots.txt i dokładne kontrolowanie częstotliwości skrobania, aby zapobiec przeciążeniu serwera.
Odpowiedzialne stosowanie tych metod otwiera drzwi do bogatych źródeł danych, które mogą dostarczyć przydatnych spostrzeżeń i pomóc w podejmowaniu świadomych decyzji zarówno firmom, jak i osobom prywatnym. Właściwe wdrożenie w połączeniu z względami etycznymi gwarantuje, że zbieranie danych pozostanie potężnym narzędziem w krajobrazie cyfrowym.
Chcesz udoskonalić swoje spostrzeżenia, zbierając dane ze strony internetowej? Nie szukaj dalej! PromptCloud oferuje etyczne i niezawodne usługi skrobania sieci dostosowane do Twoich potrzeb. Połącz się z nami pod adresem sales@promptcloud.com, aby przekształcić surowe dane w przydatne informacje. Wspólnie usprawnimy proces podejmowania decyzji!
Często Zadawane Pytania
Czy dopuszczalne jest usuwanie danych ze stron internetowych?
Oczywiście skrobanie danych jest w porządku, ale musisz przestrzegać zasad. Zanim zaczniesz przygodę ze skrobaniem, zapoznaj się z warunkami korzystania z usługi i plikiem robots.txt danej witryny. Okazanie szacunku dla układu witryny, przestrzeganie limitów częstotliwości i przestrzeganie zasad etyki są kluczem do praktyk odpowiedzialnego gromadzenia danych.
Jak mogę wyodrębnić dane użytkownika ze strony internetowej poprzez skrobanie?
Wyodrębnianie danych użytkownika poprzez skrobanie wymaga skrupulatnego podejścia zgodnego z normami prawnymi i etycznymi. Jeśli to możliwe, do odzyskiwania danych zaleca się korzystanie z publicznie dostępnych interfejsów API udostępnianych przez witrynę internetową. W przypadku braku interfejsu API konieczne jest zapewnienie, że stosowane metody skrobania są zgodne z przepisami dotyczącymi prywatności, warunkami użytkowania i zasadami określonymi na stronie internetowej, aby złagodzić potencjalne konsekwencje prawne
Czy scraping danych ze stron internetowych jest nielegalny?
Legalność web scrapingu zależy od kilku czynników, w tym od celu, metodologii i zgodności z obowiązującymi przepisami. Chociaż skrobanie sieci samo w sobie nie jest nielegalne, nieautoryzowany dostęp, naruszenie warunków korzystania z witryny internetowej lub lekceważenie przepisów dotyczących prywatności może prowadzić do konsekwencji prawnych. Odpowiedzialne i etyczne postępowanie w działaniach związanych z web scrapingiem jest sprawą najwyższej wagi i wiąże się z dużą świadomością granic prawnych i względów etycznych.
Czy strony internetowe mogą wykrywać przypadki skrobania sieci?
Strony internetowe mają wdrożone mechanizmy służące do wykrywania i zapobiegania czynnościom skrobania sieci, elementy monitorujące, takie jak ciągi znaków klienta użytkownika, adresy IP i wzorce żądań. Aby ograniczyć wykrywanie, najlepsze praktyki obejmują stosowanie technik takich jak rotacja agentów użytkownika, korzystanie z serwerów proxy i wdrażanie losowych opóźnień między żądaniami. Należy jednak pamiętać, że próby obejścia środków wykrywania mogą naruszać warunki korzystania z witryny internetowej i potencjalnie skutkować konsekwencjami prawnymi. Odpowiedzialne i etyczne praktyki web scrapingu traktują priorytetowo przejrzystość i przestrzeganie standardów prawnych i etycznych.